Imagine you’re a cricket player facing a new opponent. As a beginner, you struggle to make strategic decisions on the field due to a lack of experience. To improve, you seek guidance from a seasoned coach who provides feedback and teaches you the game’s tactics. Similarly, in AI, “Reinforcement Learning from Human Feedback (RLHF) learns from human guidance and accelerate their training process,” explains Long Ouyang, a research scientist at OpenAI.
RLHF involves two key players: the human teacher and the AI learner. Like the cricket coach, the human teacher provides feedback to guide the AI’s decision-making. The AI learner, on the other hand, uses this feedback to improve its decision-making abilities and optimize performance.
Just as a cricket player flourished under the guidance of a coach, RLHF empowers AI systems to leverage human feedback and accelerate their learning process, ultimately advancing the capabilities of AI. So, strap on your pads and stamp your authority on the 22 yards of RLHF!
Introduction to Reinforcement Learning from Human Feedback (RLHF)
What is RLHF?”
Reinforcement learning from human feedback (RLHF) is a subfield of artificial intelligence (AI) that combines the power of human guidance with machine learning algorithms. It involves training an AI agent to make decisions by receiving feedback. Unlike traditional reinforcement learning (RL), where the agent learns through trial and error, RLHF enables faster and more targeted learning by leveraging human expertise.
Imagine you’re teaching a dog to perform tricks. Initially, the dog doesn’t know how to respond to commands. Through RL, you reward the dog whenever it performs a correct action. However, RLHF takes a different approach. You guide the dog by providing specific instructions and corrections during the training process. By incorporating your feedback, the dog learns faster and performs tricks proficiently.
The difference between RL and RLHF lies in the source of feedback. RL relies on autonomous exploration, while RLHF integrates human guidance to accelerate learning. RLHF acts as a teacher, enhancing the learning process by leveraging human expertise. For that purpose, it uses observation space, the set of all possible inputs.
Benefits of RLHF
RLHF offers a promising approach to enhancing business operations and decision-making. By leveraging human expertise and guidance, RLHF empowers businesses to optimize their systems, improve customer experiences, and achieve heightened levels of performance and efficiency. Here are some of the benefits that you may avail with RLHF:
- Accelerated training: RLHF uses human feedback to train reinforcement learning models faster. You can save time by using human feedback to direct the learning, instead of relying on flawed or limited goals. For example, RLHF can improve AI summary generation by using human feedback to adjust to different domains or contexts.
- Improved performance: RLHF lets you improve your reinforcement learning models with human feedback. This can fix flaws and boost the model’s choices. For example, RLHF can improve chatbot responses by using human feedback on quality and values, leading to satisfied customers.
- Reduced cost and risk: RLHF saves costs and risks of training RL models from zero. With human expertise, you can skip expensive trials and catch errors sooner. In drug discovery, RLHF can identify promising candidate molecules for testing, cutting the time and cost of screening.
- Enhanced safety and ethics: RLHF trains reinforcement learning models to make ethical and safe decisions with human feedback. For example, RLHF can help medical models recommend treatments that prioritize patient safety and values.
- Increased user satisfaction: RLHF lets you tailor reinforcement learning models with user feedback and preferences. You can make personalized experiences that suit user needs with human insights. RLHF can improve recommendations with user feedback in recommendation systems.
- Continuous learning and adaptation: RLHF helps reinforcement learning models learn and update with human feedback. The models can stay current with changing conditions by getting feedback regularly. For example, RLHF can help fraud detection models adjust and spot new fraud patterns better.
Challenges of RLHF
Balancing the need for a large and diverse set of feedback with the practical limitations of human input proves to be a significant hurdle. Here are some of the most common challenges that you may face with RLHF:
- Quality and consistency of human feedback: The feedback provided by humans can vary depending on the task, the interface, and the individual preferences of the humans, making it difficult for models to learn accurate and optimal policies.
- Reward alignment: Aligning feedback with the desired task reward can be challenging. Mapping human preferences or demonstrations to a suitable reward function requires careful consideration and can lead to mismatches or dangerous behavior.
- Scaling to large action spaces: Scaling the RLHF model to domains with large action spaces can be computationally expensive compared to unsupervised learning. It becomes more challenging to obtain and process feedback from humans efficiently.
- Incorporating diverse human perspectives: Accounting for diverse feedback and preferences is crucial for building robust and inclusive RLHF systems. Handling conflicting feedback and biases while maintaining fairness can be demanding.
- Undesirable behaviors or loopholes: RLHF models may still exhibit behaviors that are not captured by human feedback or exploit loopholes in the reward model, which raises issues of alignment and robustness.
With challenges come solutions!
You can overcome these RLHF challenges using AI assistance, adversarial training, and active learning. For that, let’s first understand the core components of RLHF.
Key components of RLHF
The key components of RLHF provide a foundation for developing intelligent systems that can learn from demonstrations and feedback, bridging the gap between human knowledge and machine learning. Here they are:
- Agent: The RLHF framework involves an agent, an AI system that learns to perform tasks through RL. The agent interacts with an environment and receives feedback through rewards or punishments based on its actions.
- Human demonstrations: RLHF shows the agent what to do. These demonstrations consist of state-action sequences representing desirable behavior. The agent learns from these demonstrations to imitate the desired actions.
- Reward models: Alongside these demonstrations, reward models provide additional feedback to the agent. You can provide models that assign a value function to different states or actions based on desirability. The agent learns to maximize the cumulative reward signal it receives.
- Inverse reinforcement learning (IRL): IRL is a technique used in RLHF to infer the underlying reward function from demonstrations. By observing the demonstrated behavior, agents try to understand the implicit reward structure and learn to imitate it.
- Behavior cloning: Behavior cloning is a way for the agent to imitate the actions humans demonstrate. The agent learns a rule by making its actions close to human actions.
- Reinforcement learning (RL): After learning from demonstrations, the agent transitions to RL to further refine its policy. RL involves the agent exploring the environment, taking action, and receiving feedback. It learns to optimize its policy through trial and error.
- Iterative improvement: RLHF often involves an iterative process. You provide demonstrations and feedback to the agent, and it progressively improves its policy through a combination of imitation learning and RL. This iterative cycle continues until the agent achieves satisfactory performance.
Understanding human feedback in RLHF
Human feedback helps RLHF by providing valuable guidance and supervision throughout the learning process. It enables learning agents to benefit from human expertise, accelerate the learning process, and improve the efficiency of behavior acquisition.
Types of human feedback in RLHF
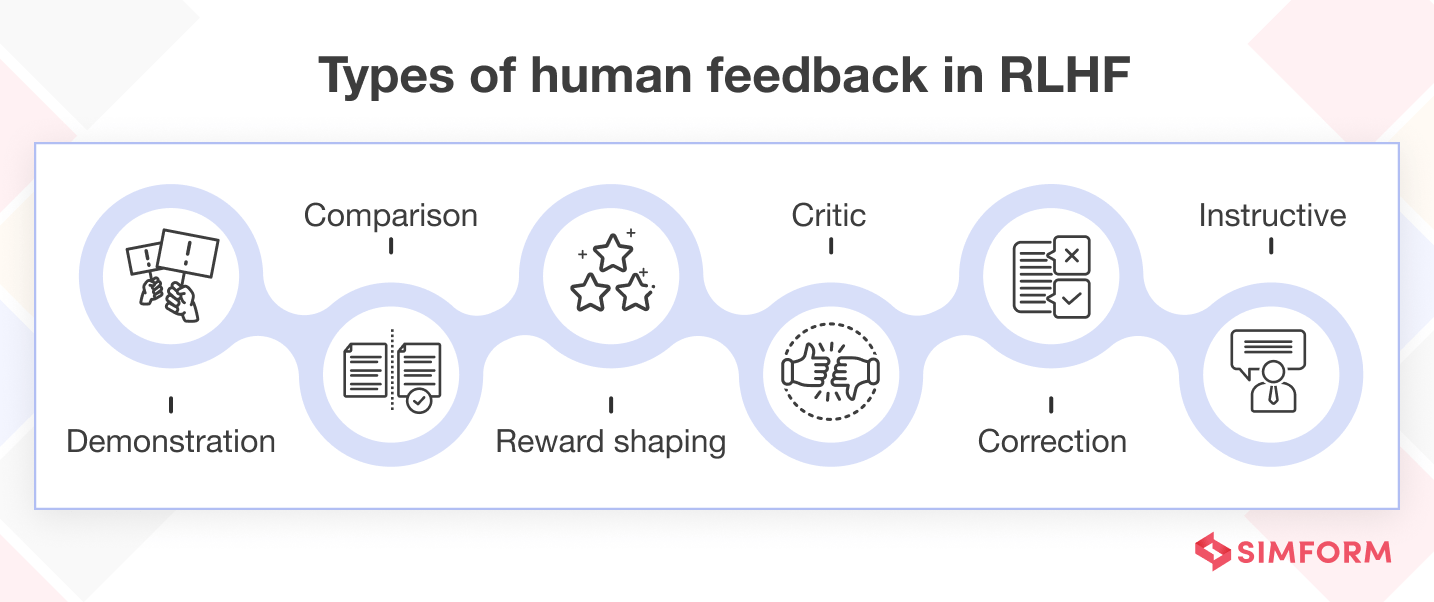 Some types of human feedback in RLHF are:
Some types of human feedback in RLHF are:
- Demonstration feedback: It involves providing the agent with expert demonstrations of desired behavior. For example, in a self-driving car scenario, a human driver could demonstrate how to drive well.
- Comparison feedback: In this type of feedback, the agent is given information about the relative quality of its actions. For instance, a human might indicate that they prefer action A over action B, helping to guide the learning process and improve the agent’s performance.
- Reward shaping feedback: It modifies the reward signal to guide the agent’s learning process. An example would be assigning higher rewards for actions that lead to desired outcomes, such as reaching a goal in a maze-solving task.
- Correction feedback: Here, the agent receives corrective feedback when it makes mistakes. For instance, in a language translation task, a human could correct mistranslations made by the agent.
- Critique feedback: This feedback involves providing qualitative feedback on the agent’s performance. An example would be a user providing suggestions for improvement in a virtual assistant’s responses.
- Instructive feedback: In this type of feedback, the human directly instructs the agent on what actions to take. For example, if the agent is learning to play a video game, the human might say, “Try to avoid the red enemies and collect the green power-ups to increase your score.”
Methods for incorporating human feedback in RLHF
In RLHF, methods for incorporating feedback aim to leverage human knowledge and guidance to improve the supervised learning process. Here are six well-known methods:
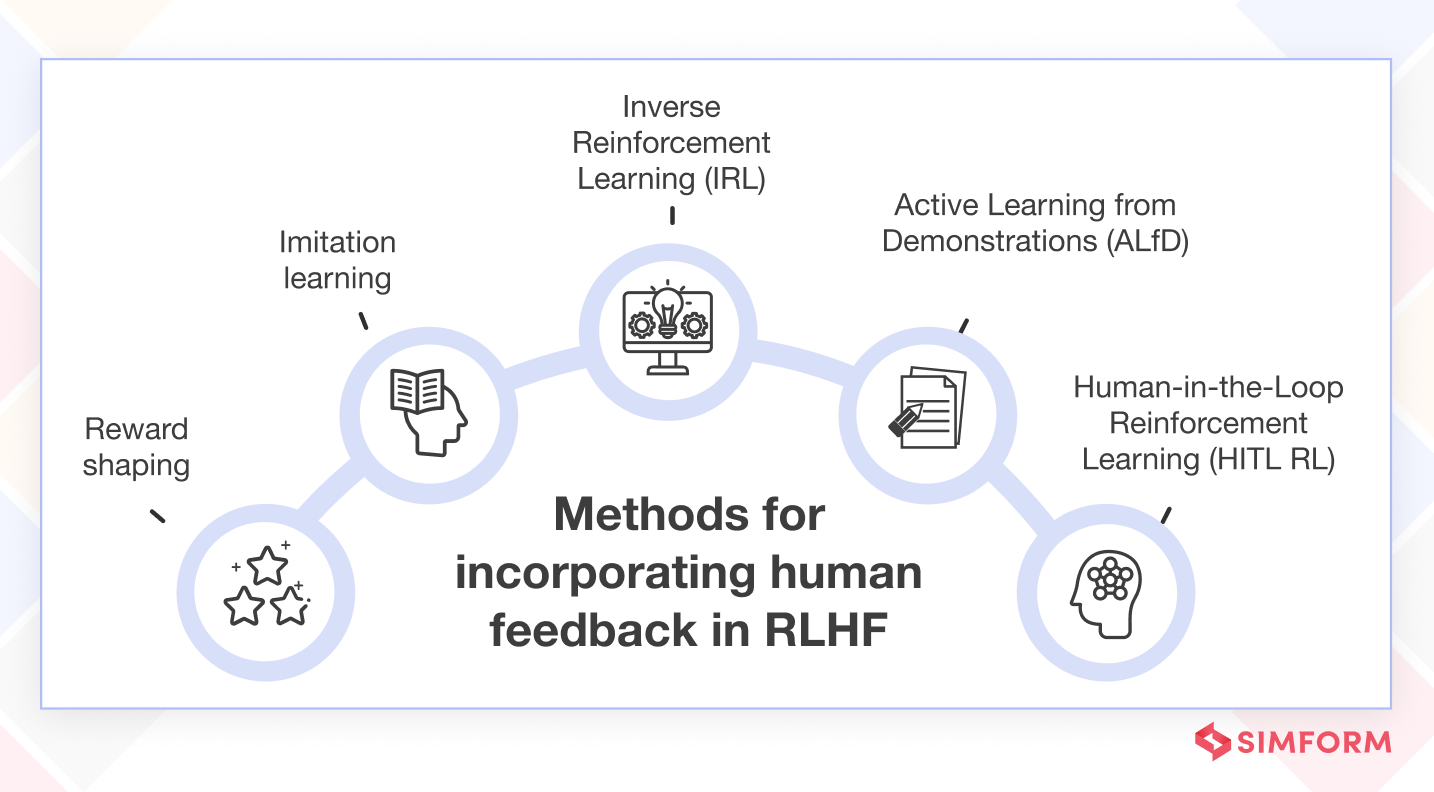 Reward shaping: Modifying the reward function to help the learning agent.
Reward shaping: Modifying the reward function to help the learning agent.
For example, Google’s Vertex AI, its AI services, comprises an Imagen text-to-image model. To provide customers with quality text-to-image results, Google has added RLHF as a service in Vertex. Here, the RLHF uses reward shaping to train the reward model and fine-tune its output to optimize the generative AI model.
- Imitation learning: The agent learns from demonstrations provided by a human expert. By imitating the expert’s actions, the agent can learn effective strategies.
Brett Adcock and his company are using a combination of reinforcement learning and imitation learning to train robots on how to do warehousing better. The purpose is to build a fleet of valuable robots and use their data with imitation learning to train a more extensive fleet.
- Inverse reinforcement learning (IRL): The agent infers the underlying reward function from human demonstrations. By understanding the intent behind the demonstrations, the agent can learn to perform tasks more intelligently.
Igor Halperin, Jiayu Liu, and Xiao Zhang suggest a method combining human and artificial intelligence to learn the best investment practices of fund managers. By analyzing their investment decisions, IRL can understand an investor’s hidden utility function in asset allocation. By modeling the investor’s behavior, IRL can give insights into their risk preferences, time length, and other factors, informing optimal asset allocation strategies tailored to their preferences that you can apply for your asset allocation.
- Active learning from demonstrations (ALfD): The agent interacts with the human to actively request demonstrations for some situations that need guidance. It helps in exploring the state-action space better.
ALfD can be used for image restoration by using human shows to improve the restored images. ALfD trains a model with labeled and unlabeled data. Human experts can show image restoration by restoring some images. The ALfD framework learns from these shows to help restore other unlabeled images, improving them based on the learned shows.
- Human-in-the-Loop reinforcement learning (HITL RL): The agent interacts with a human in real-time, receiving feedback and corrections during learning. The human can intervene and guide the agent’s actions when necessary.
Amazon Augment AI leverages HITL RL to enhance its performance and improve customer experiences. The process starts with an initial model trained with supervised learning, then fine-tuned with reinforcement learning. In this context, HITL RL incorporates human feedback and expertise in the training. It ensures that the model learns from real-world scenarios and continuously adapts to evolving user needs.
With the core components of RL with human feedback known, it will become easier for you to know the working of RLHF and the algorithm behind it. Let us focus on that aspect in our upcoming section.
How does RLHF work?
RLHF is an algorithm that combines the power of human expertise with the learning capabilities of artificial intelligence (AI) systems. With RLHF, AI agents can learn complex tasks efficiently by receiving feedback from human trainers. Here’s a step-by-step guide on how RLHF works:
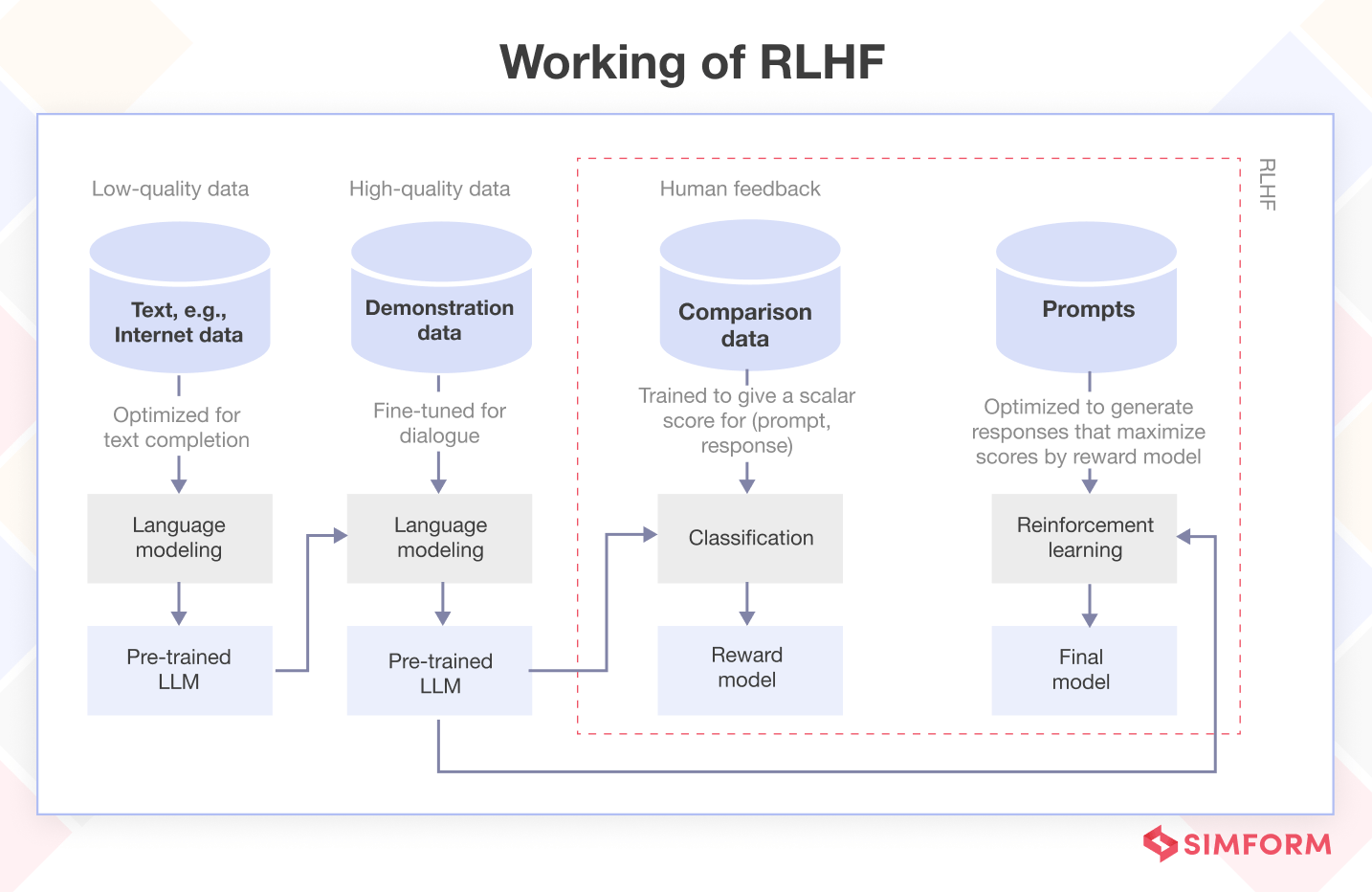
Step 1 – Initialization: Define the task you want the AI agent to learn and specify the reward function accordingly.
Step 2 – Demonstration collection and data preprocessing: Collect demonstrations from human trainers who perform the task expertly. These demonstrations serve as examples for the AI agent to learn from. Process the collected demonstrations, converting them into a format suitable for training the AI agent.
Step 3 – Initial policy training: You train the AI agent using the demonstrations as a starting point. The agent learns to mimic the behavior of the human trainers based on the collected data.
Step 4 – Policy iteration: You deploy the initial policy and let the AI agent interact with the environment. Its learned policy determines the agent’s actions.
Step 5 – Human feedback: Human trainers provide feedback on the agent’s actions. This feedback can be binary evaluations (good or bad) or more nuanced signals.
Step 6 – Reward model earning: You use human feedback to learn a reward model that captures the trainers’ preferences. This reward model helps guide the agent’s learning process.
Step 7 – Policy update: The agent’s policy uses the learned reward model. The agent learns from human feedback and interactions with the environment, gradually improving its performance.
Step 8 – Iterative process: Steps 4 to 7 are repeated iteratively, with the AI agent refining its policy based on new demonstrations and feedback.
Step 9 – Convergence: The RLHF algorithm continues until the agent’s performance reaches a satisfactory level or until a predetermined stopping criterion gets met.
RLHF combines human trainers’ expertise with AI’s learning capabilities, effectively and efficiently learning complex tasks.
Role of RLHF in training and fine-tuning LLMs
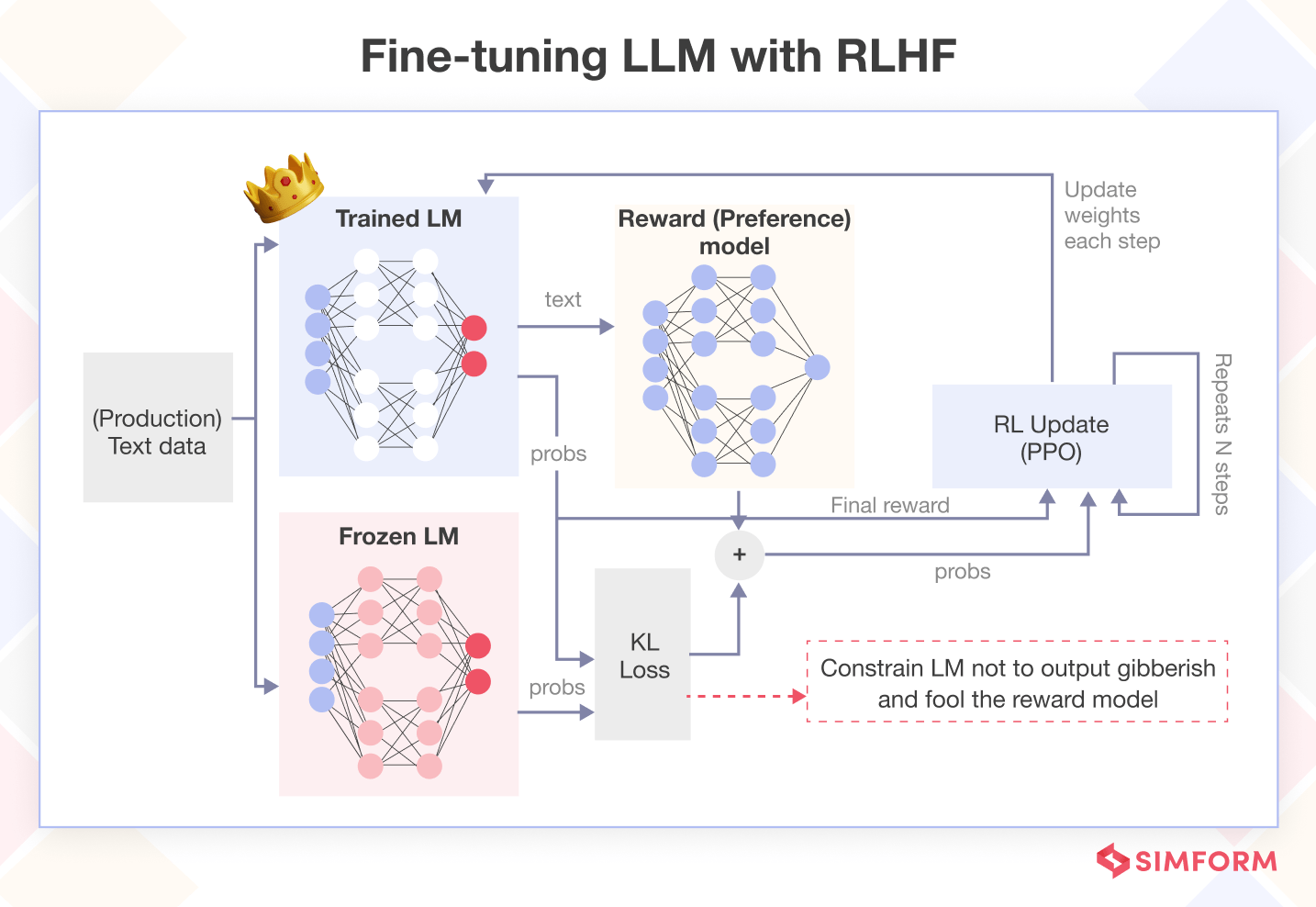 RLHF trains and fine-tunes Large Language Models (LLMs) by leveraging human guidance to create reward models that guide the learning process of the model, improving their performance.
RLHF trains and fine-tunes Large Language Models (LLMs) by leveraging human guidance to create reward models that guide the learning process of the model, improving their performance.
Firstly, it helps address the challenge of biased or inappropriate outputs generated by the model. By allowing humans to provide feedback on model responses, the RLHF framework trains the model to minimize harmful or undesirable outputs. This iterative feedback loop enables the model to learn from its mistakes and generate more appropriate and contextually accurate responses.
Secondly, RLHF aids in improving the quality and fluency of generated text. Human evaluators can rank different model-generated responses based on their quality, coherence, and relevance. By incorporating this feedback, the RLHF process can guide the model towards generating more fluent and meaningful text.
Furthermore, RLHF can be used to enhance specific aspects of the model’s behavior. By providing feedback on desired behaviors, such as being more concise, using specific terminology, or adhering to certain guidelines, the model can be fine-tuned to meet specific requirements.
Let’s understand how RLHF plays a significant role in the training and fine-tuning of LLM by taking the example of ChatGPT and BARD – the most popular LLMs of today’s day and age!
The role of RLHF in ChatGPT
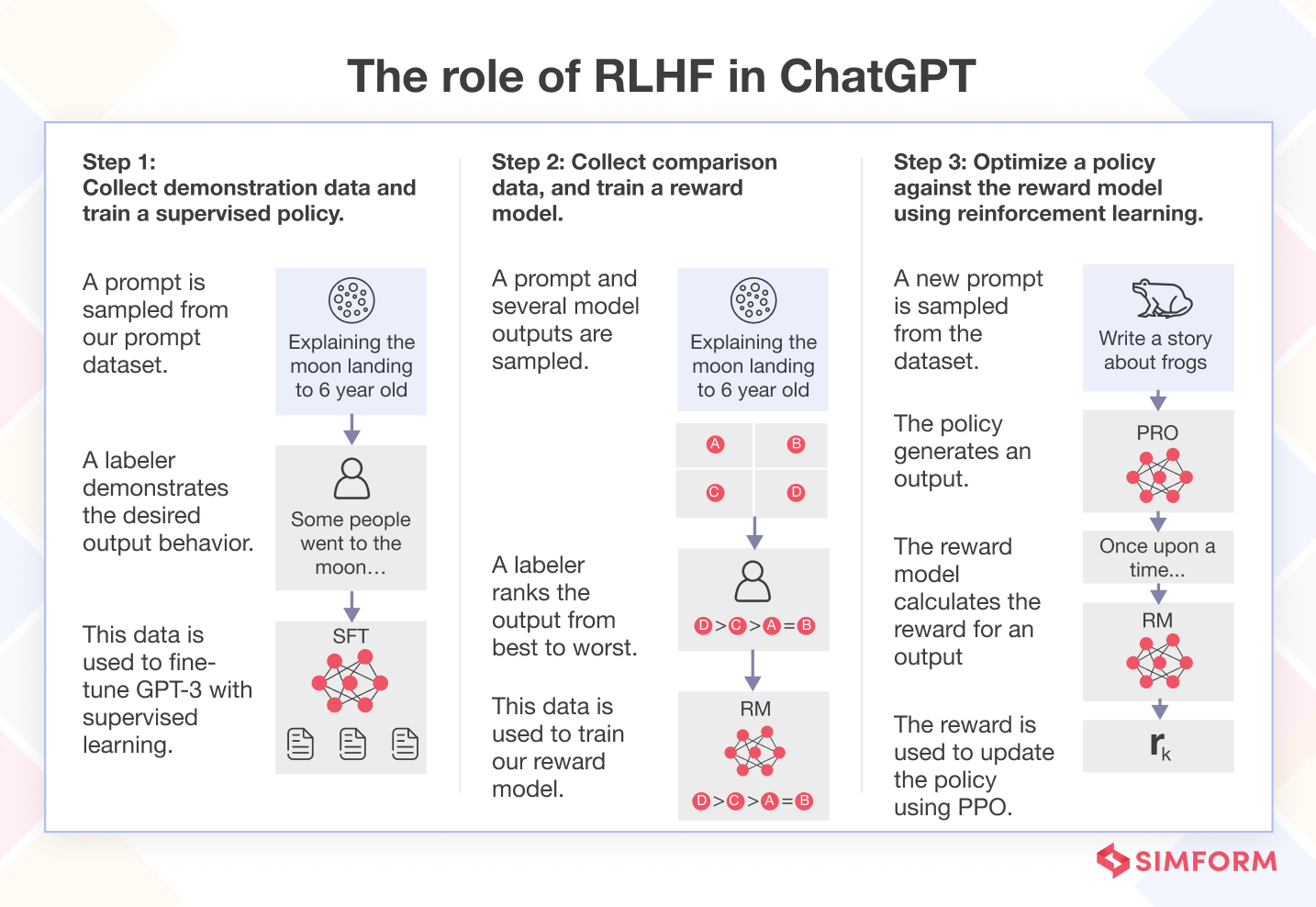 ChatGPT is a generative AI model that uses deep learning techniques to generate human-like responses in a conversational setting.
ChatGPT is a generative AI model that uses deep learning techniques to generate human-like responses in a conversational setting.
The role of RLHF in ChatGPT is to fine-tune the language model to generate engaging and coherent responses to user queries. RLHF enables ChatGPT, based on GPT-3 and GPT-3.5, to learn from human preferences and values, and improve its conversational skills. An example of RLHF in ChatGPT is as following:
- Fine-tune a pretrained LLM on a specific domain or corpus of instructions and human demonstrations. For example, human writers provide examples of how to answer questions or chat about different topics.
- Collect a human annotated dataset and train a reward model. For example, human evaluators rate the model’s responses on a scale of 1 to 5 based on their coherence, engagement, and informativeness.
- Further fine-tune the model with the reward model and this dataset using RL (e.g. PPO). For example, the model learns to generate responses that maximize the reward from the human evaluators.
This example shows how RLHF helps ChatGPT generate more engaging and coherent responses by receiving feedback from human trainers.
The role of RLHF in BARD
Bard is Google’s experimental, conversational AI chat service. It is meant to function similarly to ChatGPT, with the biggest difference being that Google’s service will pull its information from the web. Here is a step-by-step guide on how Google Bard works along with the role of RLHF:
- Google uses reinforcement learning from human feedback (RLHF) to train the model using human feedback. This process gets repeated many times until the LLM can consistently generate accurate and informative responses.
- Once the LLM gets trained and refined using RLHF, it gets deployed on Google’s servers. It enables users to access Bard through various channels, including the Google Search bar, the Google Assistant, and the Google Cloud Platform.
Google is constantly working to improve Bard. It includes collecting more data, training the LLM on new data, and using RLHF to improve the LLM’s performance.
Overall, in Google Bard, RLHF is used to improve the accuracy and fluency of the model’s responses. By providing feedback on the model’s output, humans can help the model to learn how to generate more accurate and natural-sounding text. You can provide this feedback in various ways, such as through surveys, user interviews, or even just by using the model and providing feedback as you go.
RLHF is a powerful tool that improves the performance of LLMs. By providing feedback from humans, RLHF can help LLMs learn what is considered excellent or lousy output and use this information to improve their performance. It can lead to more accurate, fluent, and informative LLMs.
Discover the comparison between Google Bard and ChatGPT.
What the future holds for RLHF?
The future has endless possibilities for Reinforcement Learning from Human Feedback (RLHF), particularly when combined with fine-tuning Language Models (LLM). This ground-breaking concept shifts the paradigm as machines learn from human interactions and refine their decision-making abilities.
RLHF enables AI systems to adapt and become more intelligent through human feedback. Moreover, we unlock new dimensions of AI capabilities by leveraging the synergy between RLHF and fine-tuning LLMs.
No doubt! There are some challenges and limitations of RLHF that need to be addressed. These challenges require further research to make RLHF effective and reliable.
But imagine models that understand human nuances, effortlessly producing eloquent and precise responses while rejecting questions that are either inappropriate or outside the knowledge space of the model.
That’s the future!
Curious to read more?
Here’s a detailed guide on – how to fine-tune LLMs.
