If you have heard the buzzwords ChatGPT and generative AI (the tech behind ChatGPT), you may be wondering how it works. From generating music that mimics the style of Bach to creating images that look like a master artist painted them, generative AI has come a long way in its ability to produce new and original content. But what goes on behind the scenes?
This blog will explore what is generative AI and how does it work, types of generative AI models, and applications based on these models. We will also look at some real-world applications of generative AI, its benefits, and challenges with generative AI. Let’s start with generative AI meaning.
What is generative AI?
Generative Artificial Intelligence is a field of AI that focuses on creating algorithms and models that can generate new and realistic data resembling patterns from a training dataset. In simpler words, generative AI refers to a class of AI systems that produce entirely new data. These systems or models are trained to learn from huge datasets and create something entirely new based on that information. Hence, the term “generative” is used to describe it.
Generative AI has many applications in various fields, such as art, image synthesis, natural language generation, music composition, coding, and more. We have explored the uses and applications in detail in our blog on what is generative AI.
Most traditional types of artificial inteligence such as discriminative AI are designed to classify or categorize existing data. On the contrary, the goal of generative AI models is to generate completely original artifacts that have not been seen before.
Discriminative AI vs Generative AI
-
Discriminative AI
Discriminative AI models are trained to recognize patterns in datasets and use those patterns to make predictions or classifications about new samples. For example, a discriminative AI model might be trained on a dataset named cat or dog images. It could then classify new images as either cats or dogs based on the patterns it learned from the input data.
-
Generative AI
A generative AI model is designed to learn underlying patterns in datasets and use that knowledge to generate new samples similar but not identical to the original dataset. For example, a generative AI algorithms trained on a dataset of images of cats might be able to generate new images of cats that look similar to the ones in the original dataset but are not exact copies.
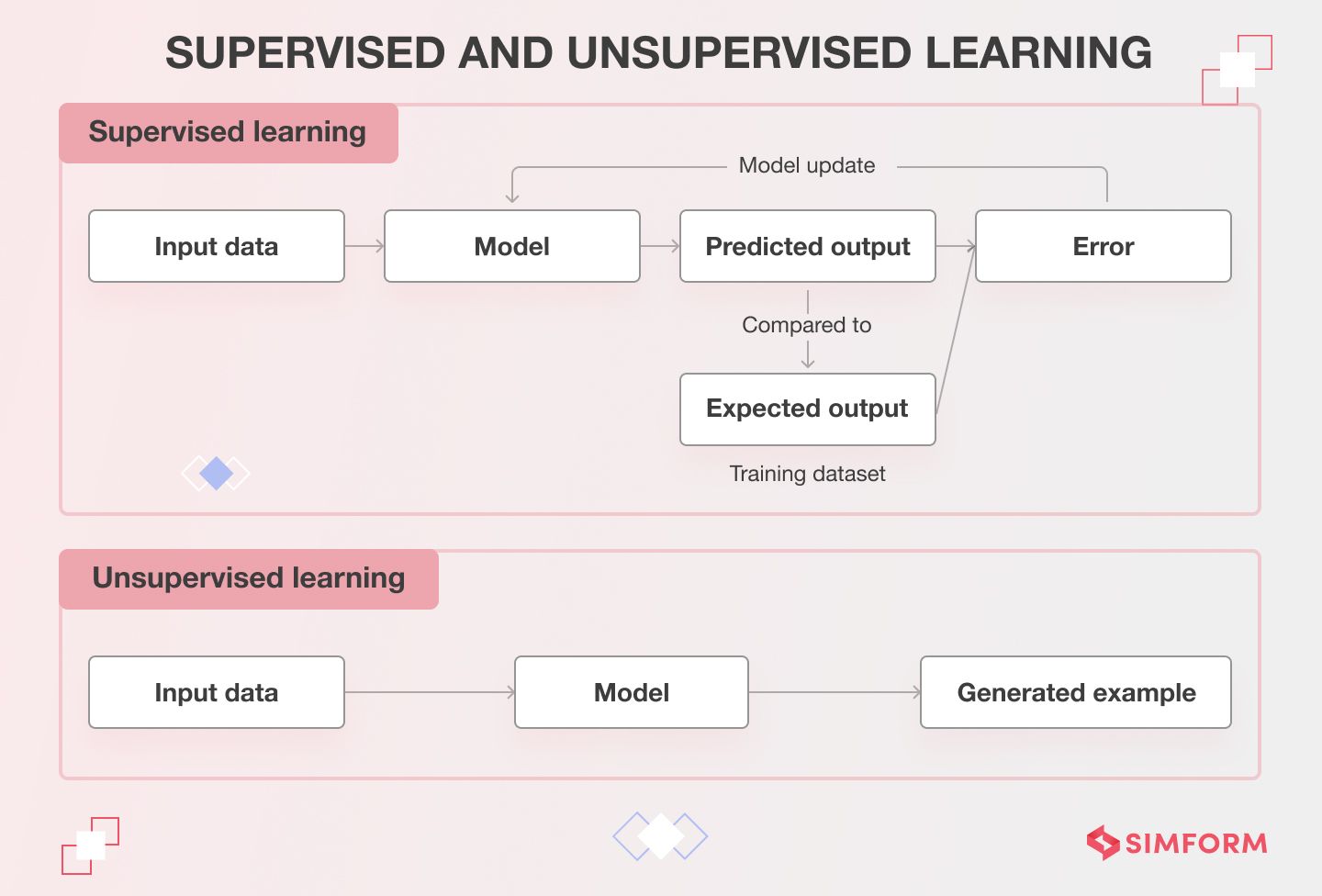
Another critical difference between generative AI and other types of AI is that generative models are typically unsupervised, meaning they do not require pre-labeled data to learn from. This makes generative AI particularly useful in applications where structured or organized data is scarce or difficult to obtain.
Generative AI can use both unsupervised and semi-supervised machine learning algorithms.
- Unsupervised machine learning algorithms
They are used when no labeled data is available for training. Instead, the algorithm is given a bunch of unstructured data sets. It looks at the unorganized data and tries to identify patterns and structures independently without any instructions or prior knowledge. Clustering and anomaly detection are examples of unsupervised learning techniques.
- Semi-supervised machine learning algorithms
They are used when some labeled data is available for training, but the amount is insufficient to train a complete model. The algorithm uses the labeled data along with the unlabeled data to identify patterns and structures within the data. Semi-supervised learning can be considered a hybrid approach between supervised and unsupervised learning techniques.
Returning to our main question, let’s delve into the workings of generative AI.
How does generative AI work?
Generative AI is a fascinating field that uses various techniques, like neural networks and deep learning algorithms, to identify patterns and generate new outcomes based on them. It’s like the AI version of tapping into the human brain’s creative processes!
Generative AI uses various techniques—including neural networks and deep learning algorithms—to identify patterns and generate new outcomes based on them.
The training process for a generative model involves feeding it a large dataset of examples, such as images, text, audio, and videos. Then, the model analyzes the patterns and relationships within the input data to understand the underlying rules governing the content. It generates new data by sampling from a probability distribution it has learned. And it continuously adjusts its parameters to maximize the probability of generating accurate output.
For example, a generative model trained on a dataset of cat images could be used to create new images of cats by sampling from the learned distribution and then refining the output through a process called “inference.”
During inference, the model adjusts its output to better match the desired output or correct any errors. This ensures that the generated output becomes more realistic and aligns better with what the user wants to see.
Generative AI models
There are several popular generative AI models, each with its strengths and weaknesses. We will discuss the most commonly used models below.
Generative Adversarial Networks (GANs)
Like any generative AI model, the goal of GANs is to generate new data based on a fed dataset. To achieve this, it uses two neural networks: a generator and a discriminator.
Let’s say we want to generate cat images using GAN. The generator takes a random input vector and uses it to generate a new cat image. Initially, it might look like random pixels, but as the training progresses, the generator learns to generate realistic images of cats.
The discriminator then takes both – real images of cats from the dataset and the fake ones generated by the generator – and tries to classify them as either real or fake. Based on this classification, it learns to get better at discriminating images in the next round. On the other hand, the generator learns how well, or not, the generated samples fooled the discriminator and gets better at creating more realistic images in the next round.
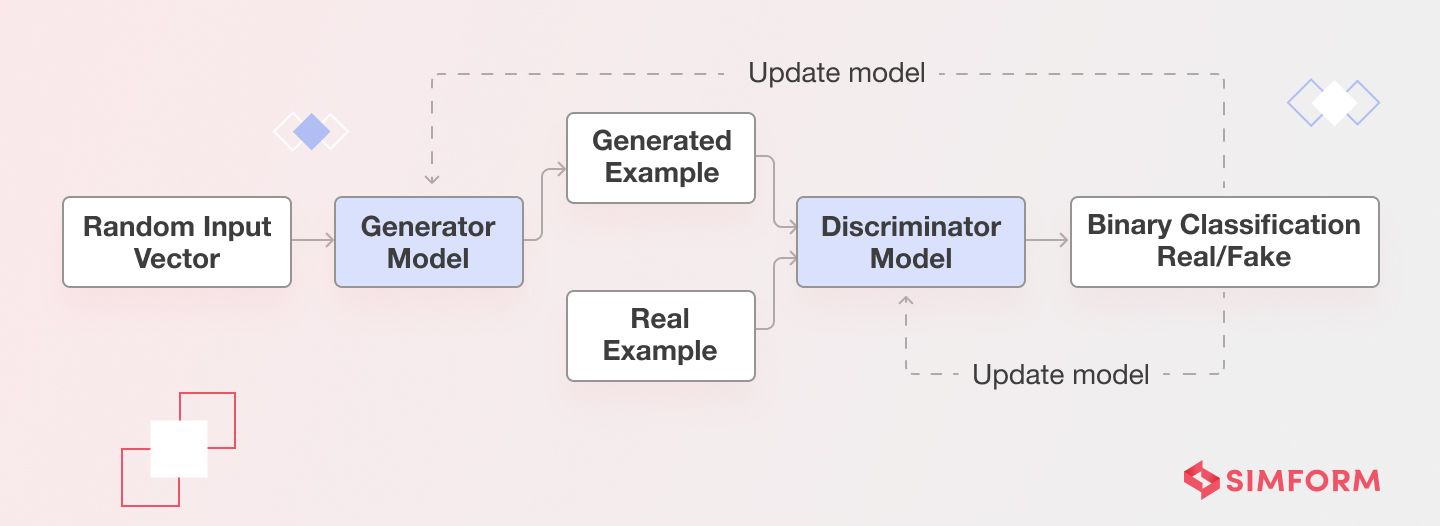
As the discriminator gets better at classifying images, the generator gets better at making images that are more difficult for the discriminator to classify. Thus, like a two-player game, both neural networks work as each other’s adversaries to improve their abilities and generate more realistic images of cats. That’s how this model came to use the term ‘adversarial’ in its name.
GANs training process
The training process of GANs can be broken down into the following steps:
- Initialization: The generator and discriminator are initialized with random weights.
- Training Loop: The generator generates a batch of fake data, while the discriminator is trained on a combination of real and fake data. The discriminator outputs a probability score between 0 and 1, indicating whether the input data is real or fake.
- Backpropagation: The error signal from the discriminator is backpropagated through the network to update its weights. The generator is then trained using the error signal from the discriminator to update its weights.
- Sampling: Once the model is trained, the generator can generate new data by sampling from the learned distribution.
GANs have been used for various applications, such as generating realistic images, videos, and speech. One advantage of GANs is their ability to generate high-quality and diverse samples, as they can learn complex and multi-modal distributions.
However, GANs can be difficult to train and may suffer from mode collapse, where the generator produces limited and repetitive samples. Various modifications and improvements have been proposed to address these issues, such as Wasserstein GANs and StyleGANs.
Potential applications of Generative Adversarial Networks (GANs):
- Image and video generation and manipulation, including creating photorealistic images and deep fakes
- Style transfer and image-to-image translation, such as converting a daytime scene to a nighttime scene
- Data augmentation and data synthesis, which can help improve the performance of supervised learning models
- Text-to-image synthesis and image captioning
- 3D object generation and design, including generating realistic avatars and virtual environments
- Voice conversion and audio synthesis
- Game development and design, such as creating new levels and characters
- Creative applications, such as generating art, music, and literature
- Security and privacy, such as generating fake data to protect sensitive information and training models to detect and prevent deep fakes
- Scientific research and simulation, such as simulating complex systems and predicting outcomes in physics and other sciences
Note: The effectiveness of GANs in these applications may depend on various factors, such as training data quality, the complexity of the underlying distribution, and the specific architecture and hyperparameters of the GAN model.
A real-life example based on GANs is CycleGAN, which is used for image-to-image translation. CycleGAN can convert images from one domain to another without paired training data. For example, it can convert a daytime image to a nighttime image or a horse image to a zebra image.
CycleGAN works by using two generator networks and two discriminator networks that work together in a cyclic process to generate new images in a way that maintains the identity of the original image. It is a powerful tool that can be used to create new visual content and transform existing images in creative and unexpected ways.
Variational Autoencoders (VAEs)
With generative AI development, you can easily generate new outputs similar to the training data. But more often, you’d want to explore variations in the data in a specific direction. This is where VAEs work better than other models.
Taking the cat image example we used earlier, let’s see how a VAE would process it. Variational Autoencoders (VAEs) take the image as input and processes it through two neural networks– an encoder and a decoder. The encoder compresses the image into a low-dimensional representation of the input data (which we call ‘latent space’), and the decoder uses it to generate a new image similar to the original one.
The difference between VAEs and traditional autoencoders is that VAEs use probabilistic models to learn the underlying distribution of the training data. The probabilistic approach allows VAEs to capture the uncertainty and variability present in the data rather than focus solely on reconstructing the input data.
VAEs training process
The training process of VAEs can be broken down into the following steps:
- Encoding: The input data is fed into the encoder network, which compresses the data into the latent space. The latent space follows a Gaussian distribution assumption.
- Sampling: From the learned Gaussian distribution, a point is randomly sampled in the latent space.
- Decoding: The decoder network takes the sampled point and decodes it into a new data point. The decoder is trained to reconstruct the original input data from the latent space representation.
- Loss Calculation: The loss function for VAEs consists of the reconstruction loss and the KL-divergence loss. The reconstruction loss measures how well the decoder can reconstruct the original input data. In contrast, the KL-divergence loss measures the difference between the learned distribution of the latent space and the actual distribution.
- Backpropagation: The error signal from the loss function is backpropagated through the network to update the weights of both the encoder and decoder.
Once the VAE is trained, it can generate new data by sampling from the learned distribution of the latent space. The VAE can also be used for other applications, such as data compression, denoising, and feature extraction.
Here is an example of image denoising with autoencoders:
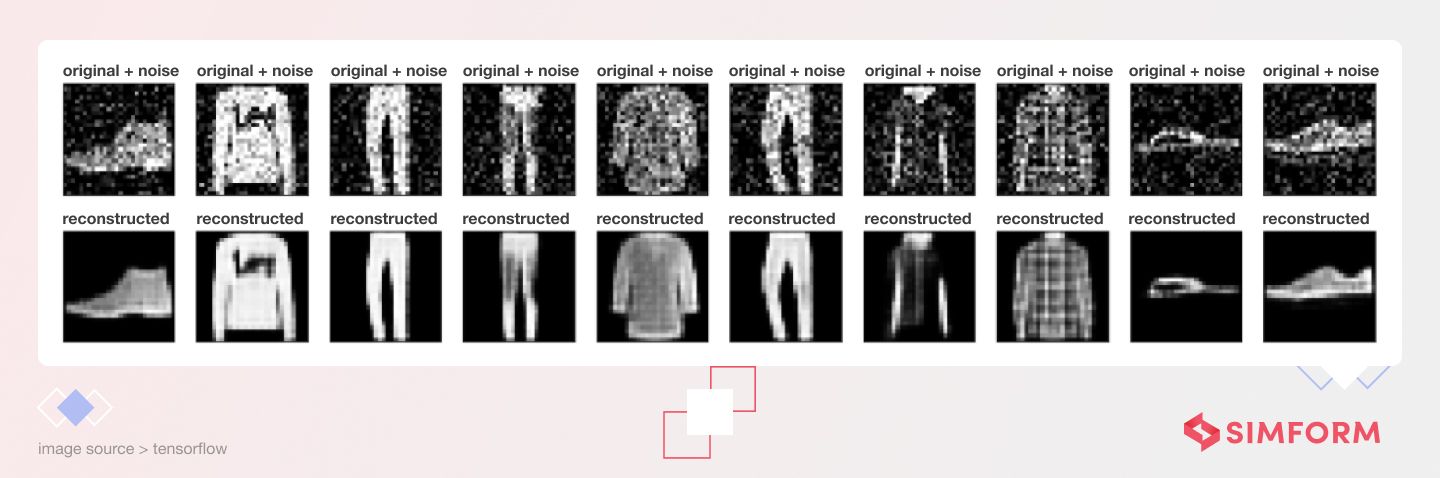
One advantage of VAEs is that they can learn a more structured representation of the data, as the encoder learns to compress the data into a lower-dimensional space. However, VAEs may produce blurry or low-quality samples, as the probabilistic nature of the model can introduce noise and uncertainty. Various modifications and improvements have been proposed to address these issues, such as using adversarial training and flow-based models.
Potential applications of Variational Autoencoders (VAEs):
- Image generation and manipulation
- Video generation and prediction
- Data compression and denoising
- Anomaly detection and outlier removal
- Recommendation systems and personalization
- Feature extraction and representation learning
- Generation of realistic 3D models and environments
- Natural language processing, including text generation and machine translation
- Biomedical data analysis and drug discovery
- Simulation and prediction in physics and other sciences
Google’s DeepDream uses a VAE-like approach to create images that resemble the original image but with a dream-like quality. It uses Convolutional Neural Networks (CNNs) to find and enhance patterns in images.
To create a DeepDream image, the algorithm takes an input image and passes it through multiple layers of a pre-trained neural network. At each layer, the algorithm tries to enhance certain image features by amplifying the patterns that the network recognizes. This process is repeated several times, with the output of one layer serving as the input to the next until the image becomes highly abstract and surreal.
Diffusion models
Diffusion models are another type of generative AI models that are currently pushing the boundaries of AI. Think Stable Diffusion, Google’s Imagen, and Midjourney.
Also known as denoising diffusion probabilistic models (DDPMs), they learn to create high-quality synthetic data by iteratively adding noise to a base sample and then removing the noise.
The core idea of how diffusion models work is they destroy training data by adding noise. It is done iteratively, increasing the amount of noise at each iteration. Then, the model learns how to remove the noise, applying a denoising process progressively to reconstruct the original data.

After training, the model can apply the learned denoising process to new inputs and generate new samples. By working with noisier data over time, the model becomes better at understanding the patterns and structure of the data while getting rid of the extra noise.
The diffusion model is especially good at making high-quality images because it can understand the intricate relationships between pixels in an image.
Another notable feature of diffusion models is that they can be trained using a simple and efficient contrastive loss function, which makes them relatively easy to train compared to other generative models such as GANs and VAEs. Also, diffusion models can perform various generative tasks, including image synthesis, video prediction, and text generation.
DALL-E is a neural network developed by OpenAI that can create images from textual descriptions using a diffusion-based generative model. The model uses a diffusion process to iteratively generate each pixel of the image, allowing for the creation of highly detailed and complex images. Users can input textual descriptions of the desired image, and DALL-E will generate an image that matches the description. For example, textual input such as an armchair in the shape of an avocado.
Other generative AI models
-
Autoregressive Models
Autoregressive models generate data one element at a time, using a probabilistic model to predict each element based on the previous elements. These models are commonly used for natural language processing (NLP) tasks, such as text generation and language translation.
In simple terms, autoregressive models predict the next value in a sequence by considering the previous values in the sequence. For example, in a time series of stock prices, an autoregressive model might predict the next day’s price based on the prices of the previous few days.
Large Language Models, also in the limelight currently, use the autoregressive model to generate coherent, human-like responses to a prompt. They are trained on massive amounts of text data, such as articles, books, and websites, and are designed to generate new text similar in style and content to the real data.
LLMs have become highly popular in recent years, with models such as OpenAI’s GPT (Generative Pre-trained Transformer) series and Google’s BERT. They have achieved impressive results on a wide range of language tasks, including language modeling, machine translation, question-answering, and text summarization. Moreover, LLMs’ ability to generate high-quality text has also made them significantly useful for creative applications such as building chatbots, writing poetry, and even writing news articles or social media posts.
-
Transformer-based models
Transformer models have been used as the building blocks for various generative AI models, including language models like GPT-3.
The transformer is a type of neural network architecture based on the self-attention mechanism. When given an input, the mechanism allows the model to assign weights to different parts of the input sequence in parallel. Then, the model identifies their relationship and generates output tailored to the specific input.
Transformers are popularly used for NLP tasks such as language translation, generation, and question-answering. However, they alone may not be considered generative models unless they are trained specifically to create new content.
-
Flow-based Models
Flow-based models are a type of generative AI model designed to learn how data is organized in a dataset. They do this by understanding the chances of different values/events accusing within the set and how likely they will occur. By capturing this, the model generates new data points maintaining the same statistical properties and characteristics.
What’s interesting about flow-based models is that they apply a “simple invertible transformation” to the existing data in a way that can be easily undone or reversed. So the models generate new data points by starting from a simple initial distribution (e.g., random noise). And by applying transformation in reverse, they can generate new samples efficiently without complex optimization.
Thus, flow-based models generate samples faster and are less computationally demanding than other models.
Another advantage of flow-based models is that they can generate high-quality samples with high resolution and fidelity. They can also perform tasks like language modeling, image and speech recognition, and machine translation.
Additionally, flow-based models can be easily trained on large datasets, making them ideal for use in deep learning applications. However, they may be less effective than other models at generating highly structured or hierarchical data.
How to evaluate generative AI models
Selecting the right model for a particular task is crucial since different tasks have their own specific needs and goals. Generative AI models each have their strengths and weaknesses. For example, one model might be great at producing high-quality images, while another excels at generating coherent text.
Evaluating generative models is vital in determining the most suitable one for a given task. It not only helps in choosing the right model but also helps you identify areas that require improvement. As a result, you can refine the model and increase the likelihood of achieving the desired results, ultimately enhancing the overall success of your AI system.
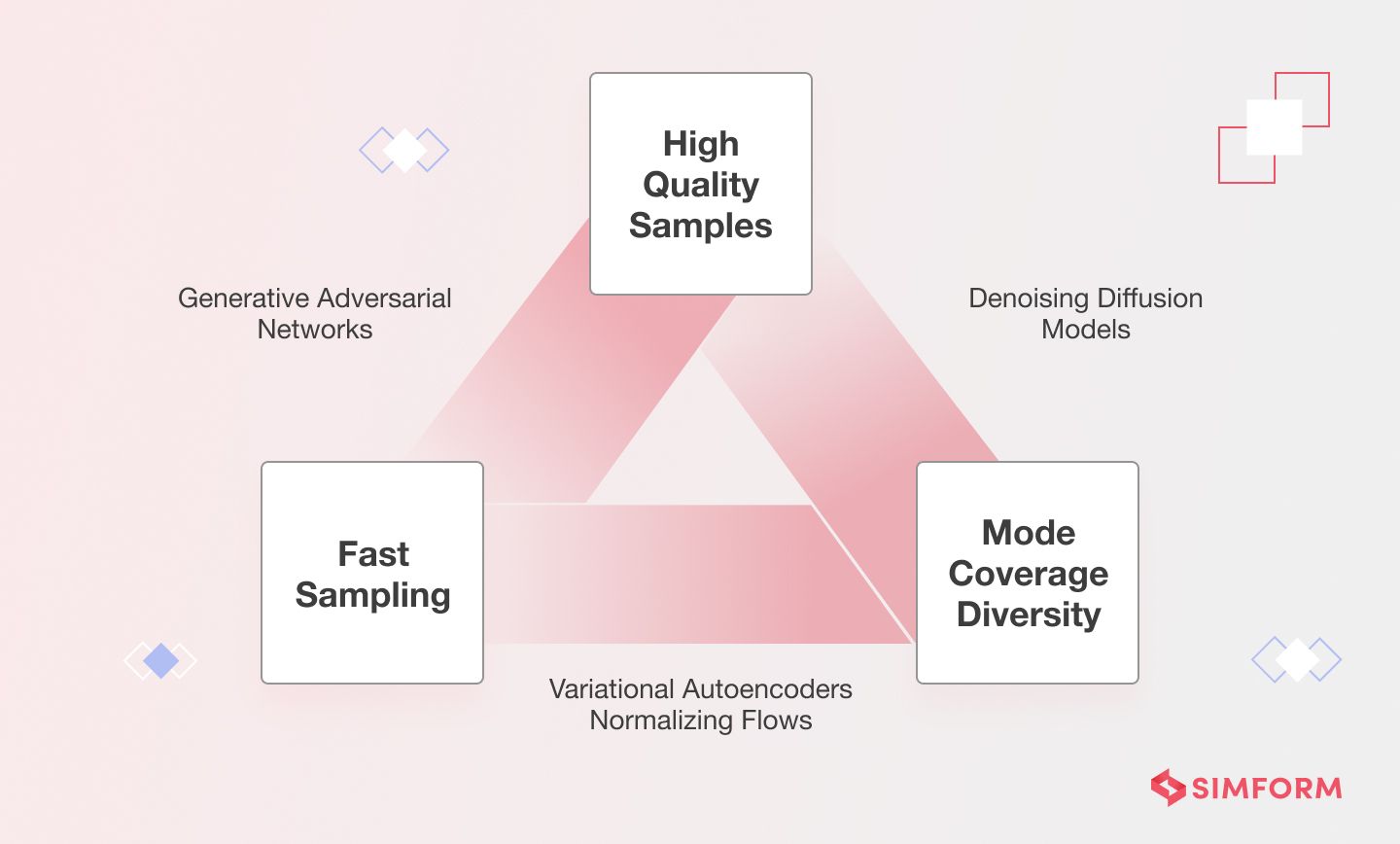
When evaluating models, three main requirements must be met for the model to be considered successful:
- Quality
The quality of the generated outputs is crucial, particularly in applications that interact directly with users. For example, in speech generation, poor speech quality can make it challenging to understand the output, while in image generation, the generated images should be visually indistinguishable from natural images.
- Diversity
A good generative model should also be able to capture the minority modes in its data distribution without sacrificing generation quality. This is known as diversity and helps reduce undesired biases in the learned models.
- Speed
Many interactive applications require fast generation speeds, such as real-time image editing, for content creation workflows. As such, the speed at which a generative model can produce outputs is also important to consider when evaluating its effectiveness.
Applications of generative AI
We already discussed some real-life generative AI examples based on different generative models. However, generative AI is being utilized to advance and transform many fields, such as transportation, natural sciences, entertainment, etc. Below, we will quickly look at a list of generative artificial intelligence applications in different industries.
- Automotive
The automotive industry uses generative AI tools to create 3D worlds and models for simulations and car development. It also leverages synthetic data for training autonomous vehicles.
- Medical research
Understanding generative AI aids medical research by developing new protein sequences for drug discovery. It can automate tasks such as scribing, medical coding, medical imaging, and genomic analysis.
- Entertainment
The entertainment industry benefits from generative AI models to streamline content creation processes for video games, film, animation, world-building, and virtual reality.
- Logistics
The logistics and transportation industry can convert satellite images to map views for accurate location services using generative AI.
- Travel
For the travel industry, generative AI tools can create face identification and verification systems at airports. It creates a full-face picture of a passenger from photos previously taken from different angles. Recently, it has also been experimented to make bookings (such as flights) from inputs given by the users.
- Healthcare
In the healthcare industry, generative AI is used to convert X-rays or CT scans to photo-realistic images to better diagnose dangerous diseases like cancer.
- Marketing
Generative AI is leveraged to perform client segmentation to predict the responses of a target group to advertisements and marketing campaigns. It also enhances upselling and cross-selling strategies through synthetic data generation of outbound marketing messages.
Unlocking the Potential of AI in Diverse Industries: Applications of NLP
Benefits of generative AI
Generative AI has numerous benefits that can be applied across all aspects of businesses. Its ability to automatically generate new content while interpreting and understanding existing content is a game-changer. Developers are constantly exploring ways to improve existing workflows by incorporating generative AI technology. Broadly, generative AI can help businesses:
- Automate manual processes to save time and effort, allowing employees to focus on higher-level tasks.
- Provide insights and predictions based on massive data analysis, enabling data-informed decision-making.
- Generate new ideas for products and services, fostering innovation and helping teams stay ahead in a competitive market.
- Facilitate personalized customer experiences with generative models trained on individual user data.
To sum up, generative AI has the potential to significantly enhance business processes, leading to increased efficiency, productivity, customer satisfaction, and cost-efficiency.
Challenges of generative AI
While generative AI is a rapidly evolving technology, it still faces several challenges in development and application. Some of the common challenges are:
- The need for computation power at scale
Building generative AI models requires significant investment in compute infrastructure to handle billions of parameters and to train on massive datasets. It requires substantial capital investment and technical expertise to procure and leverage hundreds of powerful GPUs and large amounts of memory. This can also create a barrier to entry for individuals or organizations to build in-house solutions.
- Inadequate data quality/quantity
Technology behind generative AI models rely on high-quality and unbiased data to operate effectively. While there is an abundance of data being generated globally, not all of it is suitable for training these models. Some domains, such as 3D asset creation, lack sufficient data and require significant resources to evolve and mature. Moreover, data licensing can be a challenging and time-consuming process that is essential to avoid intellectual property infringement issues.
- Sampling speed
Generative models can sometimes take a while to generate results because they are complex. This can be a problem in time-sensitive situations like instant conversations with chatbots, voice assistants, or customer service applications. Diffusion models, which are known for creating high-quality data, can be especially slow when it comes to generating samples.
However, many companies, like Microsoft and NVIDIA, are developing services and tools to make it easier for businesses to use and run generative models on a large scale. Despite the challenges, generative AI models have the potential to revolutionize many industries and businesses.
Simplify generative AI implementation with Simform
Developing and implementing generative AI models can be a challenging but rewarding process. It requires a deep understanding of ML techniques and their practical applications and the ability to work with large datasets and complex algorithms.
To successfully develop and implement generative AI models, it is essential to:
- Have a clear understanding of the problem you are trying to solve and the type of generative AI model that is best suited to solve it.
- Access high-quality data essential for training the model and ensuring its accuracy and effectiveness.
- Select the right tools and frameworks. Many open-source libraries and tools are available for building and training generative AI systems, including TensorFlow, PyTorch, and Keras. With high-level interfaces, these tools make it easier for developers to focus on the core functionality of the model rather than the underlying technical details.
- Ensure that generative AI tools are developed responsibly and ethically. It includes considering issues such as data privacy, bias, and transparency.
At Simform, our technical know-how and commitment to quality enable us to build cutting-edge, innovative digital products using revolutionary technologies such as AI/ML. If you are looking to gain an early-mover advantage with AI, contact us for a free AI/ML development consultation.
