OpenAI released ChatGPT on November 30, 2022. Since then, it has become one of the most talked about and used tools in the world. To put things in perspective, the most popular applications like TikTok and Instagram garnered 100 million users in nine months and 30 months respectively; ChatGPT did that in just two months.
ChatGPT is built on the foundation of a Large Language Model (LLM) called GPT-3. Its popularity finally brought the concept of LLMs into the spotlight and now businesses in various industries are looking for ways to harness this AI model to build their own revolutionary products.
In this article, we’ll dive deep into the nitty gritty of LLMs. You’ll get to know what they are, how large language models work, their limitations, their applications, and much more.
What is a large language model?
A large language model is an AI model that can understand human language based text input and generate human-like responses. It can do so with the help of massive text data (the entire internet, in the case of ChatGPT) that it has been trained on so that it can recognize patterns in a language to generate coherent responses.
These models are built using deep learning techniques, specifically using a type of neural network called the Transformer architecture. They are “large” because they consist of an extensive number of parameters (often billions) that are trained on vast amounts of textual data.
LLMs are a relatively new development in the field of artificial intelligence. The first LLMs were released about seven years ago and they offered very basic features. But the large language models of today, like GPT4, are equipped to work like your virtual assistants. You can ask them to draft emails for you, create presentations, write a blog post, or even teach you a foreign language.
Some well-known examples of large language models include OpenAI’s GPT-3, Google’s BERT, and NVIDIA’s Megatron. These models have demonstrated remarkable capabilities in natural language processing (NLP) tasks such as translation, summarization, question-answering, and text generation.
The architecture of large language models
Large language models are a type of neural network, specifically designed for natural language processing (NLP) tasks. These models consist of multiple layers of interconnected neurons, which are organized into a hierarchical structure.
The first LLMs were based on a recurrent neural network. Such a model, when fed with a string of text, could predict what the next word in the sequence would be. Back then, an LLM was ‘recurrent’ in the sense that it could learn from its own output. That means the outputs it generated were fed back into the network to improve future performance.
Then, in 2017, a new architecture for LLMs emerged, called the Transformer. It was first introduced by the researchers at Google Brain, Vaswani et al. (2017) in the paper “Attention is All You Need.”
The Transformer in LLMs
The Transformer architecture is based on the concept of the self-attention mechanism. This mechanism enables an LLM to consider all the different parts of the text input together. As a result, the model can weigh the importance of different words in a text input, identify the relationships between the words in a given sequence, and thus, generate a highly accurate and coherent output.
But how exactly does the attention mechanism weigh the importance of every word? It first computes a score for each word in the input sequence based on its relevance to the task at hand. The model then uses these scores to create a weighted representation of the input, which is passed through multiple layers of feed-forward neural networks.
The Transformer architecture is highly parallelizable, which means it can work on many pieces of information at the same time. And that is why LLMs can process large amounts of data simultaneously. This feature has facilitated the development of increasingly larger language models, such as OpenAI’s GPT-3, which contains an astounding 175 billion parameters. The parameters for GPT-4 are unknown at the time of writing this article.
How do large language models work?
There are two primary stages to the working of a large language model.
Pre-training
During this phase, the model is trained on a massive dataset containing a diverse range of text from the internet, such as books, articles, and websites. Pre-training helps the models learn the patterns of language, which include grammar, syntax, and semantics.
An understanding of all these language patterns is achieved through unsupervised learning. During pre-training, an LLM can be trained in multiple ways.
For instance, OpenAI asks its GPT models to predict subsequent words in a partially complete sentence. Google, on the other hand, trained BERT using a method called masked language modeling. In this methodology, the model needs to guess the randomly blanked words in a sentence.
The model regularly updates the weights of its parameters to minimize the prediction error and that’s how it learns to generate coherent and contextually relevant text.
Pre-training is the most expensive and time-consuming stage of building an LLM. To put things into perspective, a single run of GPT-3 is estimated to cost more than $4 million.
Fine-tuning
After pre-training, the model is fine-tuned on a smaller, task-specific dataset. During this phase, the model is trained using supervised learning, where it is provided with labeled examples of the desired output.
Fine-tuning allows the model to adapt its pre-trained knowledge to the specific requirements of the target task, such as translation, summarization, sentiment analysis, and more.
This process typically involves the use of techniques such as gradient descent and backpropagation to update the model’s parameters and optimize its performance on the task.
In-context learning
Researchers at MIT, Stanford, and Google Research are investigating an interesting phenomenon called in-context learning. This happens when a large language model can complete a task by witnessing only a few examples, even if it wasn’t initially trained for that task.
For example, if someone feeds the model several sentences with positive or negative meanings, the model can accurately determine the sentiment of a new sentence. Normally, a machine-learning model like GPT-3 would need to be retrained with new data to perform a new task. But in in-context learning, the model’s parameters are not updated, which makes it seem like the model has learned something new without actually being trained for it.
“With a better understanding of in-context learning, researchers could enable models to complete new tasks without the need for costly retraining,” says Ekin Akyürek, the lead author of the paper exploring this recent phenomenon.
Types of Large Language Models
Some popular types of large language models include:
1. Transformer-based models
Transformer language models work by processing and generating text using a combination of self-attention mechanisms, positional encoding, and multi-layer neural networks.
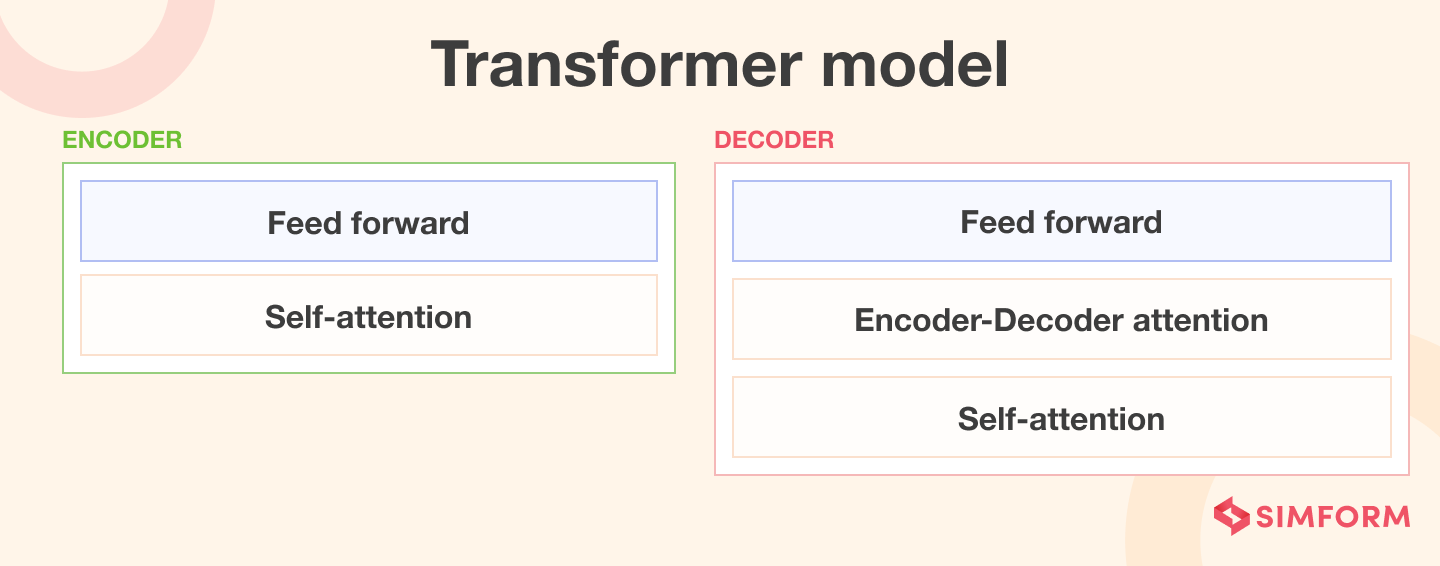
The main building block of the Transformer is the self-attention mechanism. This mechanism creates a weighted representation of the input sequence by considering the relationships among all the different parts of the text. This enables the model to capture long-range dependencies and contextual information.
2. LSTM-based models (Long Short-Term Memory)
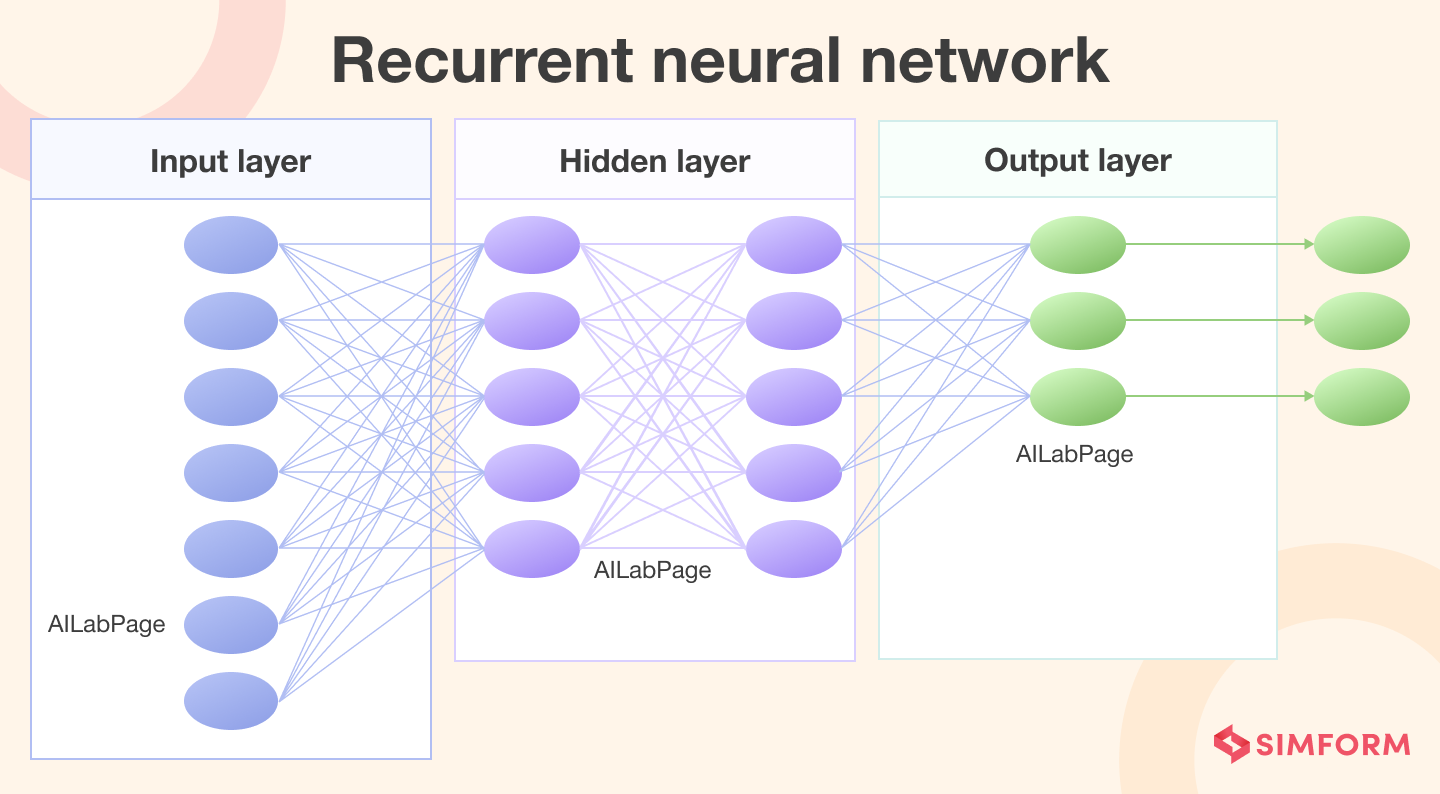
LSTM is a type of recurrent neural network (RNN) that can learn long-term dependencies in text. LSTM-based models, such as ULMFiT (Universal Language Model Fine-tuning), have been used for tasks like text classification, sentiment analysis, and language modeling.
3. ELMo (Embeddings from Language Models)
ELMo is a large-scale language model developed by Allen Institute for AI that generates contextualized word embeddings. ELMo embeddings have been used to improve the performance of various NLP tasks by incorporating context-specific information into the model.
These are some of the popular types of large language models, but there are many other models and variations within the NLP research community, with new models and techniques constantly being developed.
What Are Some Popular Large Language Models?
Several LLMs have gained prominence due to their impressive performance on various NLP benchmarks. Some of the most popular models include:
A. GPT-3 (OpenAI)
The Generative Pre-trained Transformer 3 (GPT-3) by OpenAI is one of the largest and most powerful autoregressive language models to date. With 175 billion parameters, GPT-3 can generate highly coherent and contextually relevant text, and hence, has a wide range of applications, such as text generation, translation, and question-answering.
B. BERT (Google)
BERT (Bidirectional Encoder Representations from Transformers) is an autoencoding language model that has significantly improved the state-of-the-art in various NLP techniques, such as sentiment analysis, named entity recognition, and machine translation. Its bidirectional training approach allows it to capture context from both directions (left-to-right and right-to-left), resulting in a deeper understanding of the input text.
C. T5 (Google)
T5 (Text-to-Text Transfer Transformer) is a scalable and versatile language model that combines the strengths of autoregressive and autoencoding approaches. It is designed to handle a wide range of NLP tasks by converting them into text-to-text problems. Thanks to its advanced language processing capabilities, T5 is adaptable for various applications.
D. RoBERTa (Facebook AI Research)
RoBERTa is a robustly optimized version of BERT, which has been fine-tuned on a larger dataset and with improved training strategies. This has led to better performance on various NLP benchmarks, making it a popular choice for many tasks.
E. XLNet (Carnegie Mellon University and Google)
XLNet is another notable LLM that combines ideas from both autoregressive and autoencoding models. It addresses the limitations of BERT by using a permutation-based training approach, which allows it to capture bidirectional context more effectively.
F. Other notable LLMs
There are numerous other LLMs, such as ALBERT, ELECTRA, and DeBERTa, each with their unique strengths and applications.
Applications of Large Language Models
LLMs have a wide range of applications across various domains and industries. Some of the most common use cases include:
Text Generation and Completion
One of the most popular applications of large language models is text generation and completion. These models can generate coherent and contextually relevant text passages by predicting the most probable next word, given a sequence of words.
This functionality has numerous practical applications, such as generating content for websites, blogs, and social media, as well as completing sentences or paragraphs in documents with missing information.
Moreover, large language models can be fine-tuned to generate text in specific domains, such as legal, medical, or technical writing, making them versatile and adaptable to various industries.
Text Summarization
As the volume of digital information continues to grow exponentially, efficient and accurate text summarization becomes increasingly important. Large language models have shown great potential in extracting the most relevant information from lengthy documents and generating concise summaries.
Text Summarization using LLMs can significantly reduce the time and effort required to read and comprehend large volumes of text. This is particularly useful in industries where information overload is a challenge, such as finance, legal, and healthcare.
Large language models can be applied to news articles, research papers, and books. This facilitates the dissemination of knowledge, enabling individuals to make informed decisions and stay up-to-date with the latest information.
Machine Translation
Another outstanding application of large language models is machine translation. With the ability to understand and generate text in multiple languages, these models can be used to translate text from one language to another. This has significant implications for breaking down language barriers and fostering global communication.
For example, businesses can use LLMs to translate their websites, user manuals, and marketing materials into multiple languages and make their products and services accessible to a broader audience. Additionally, these models can facilitate cross-border collaboration in research, education, and diplomacy, promoting the exchange of ideas and knowledge across different cultures and regions.
Sentiment Analysis
Large language models have also been employed for sentiment analysis, a technique used to determine the emotional tone or attitude expressed in a piece of text. By analyzing text data, these models can classify it as positive, negative, or neutral, helping businesses and organizations gauge public opinion and understand customer feedback.
Sentiment analysis can be applied to various types of data, such as social media posts, product reviews, and customer support interactions. This information can then be used to guide decision-making, improve products and services, and enhance communication strategies.
Question Answering and Conversational AI
The ability to understand and generate human-like language makes large language models particularly well-suited for question answering and conversational AI applications.
By processing and analyzing input text, these models can generate contextually relevant responses, simulating human-like conversation. This technology can be applied to create customer support chatbots, virtual assistants, educational tools, and more. In short, these LLMs can help your business provide an interactive and engaging experience to its users.
What Are the Challenges and Limitations of LLMs?
Despite their impressive capabilities, building and using LLMs does pose several challenges and limitations:
A. Computational Resources and Training Time
Training LLMs requires massive computational resources and can take weeks or even months to complete. This makes it challenging for researchers and organizations with limited resources to develop and deploy LLMs.
B. Accuracy and Reliability Concerns
Although LLMs can generate highly coherent text, they may sometimes produce incorrect or nonsensical outputs. Ensuring the reliability and accuracy of LLM-generated text is an ongoing challenge.
C. Ethical Implications and Potential Biases
LLMs can inadvertently learn and perpetuate biases present in their training data, leading to ethical concerns and potential unintended consequences. Addressing these biases and ensuring the responsible use of LLMs is an important area of ongoing research.
Future Implications and Developments
The recent success of large learning models has brought a lot of attention to the field. More and more organizations are pouring resources into LLMs and we may see even bigger technological leaps in the field in the near future.
AI, powered by LLMs, is supposedly the next big thing after the internet. It has far reaching consequences and can have direct impacts on the lives of many. Many jobs are expected to go obsolete, while many new ones will come into the picture.
It’s difficult to accurately predict what the future with AI looks like. But we can surely focus on things that are certain.
With LLMs and AI, the speed of innovation is going to be manifold. With the right competence, you can build innovative products that can quickly become market leaders.
At Simform, we can provide you with all the necessary technical know-how to build forward-looking digital products. Our body of work reflects our commitment to quality and timely delivery. Connect with us for a free consultation on AI/ML development services if you plan on getting the early-mover advantage in AI.
