Observability is the answer to the chaos of distributed systems. It provides context, which is key to getting to the root cause and resolving issues.
But many are still on the fence when it comes to adopting observability. The most common argument is that it’s a costly affair
The good news is that you can measure the ROI of observability. In this article, we’ll take you through all the quantifiable and non-quantifiable benefits of observability and also assess the cost of implementing observability.
With this detailed cost-benefit analysis of observability, you can decide for yourself if it makes sense for your infrastructure.
What are the quantifiable benefits of observability?
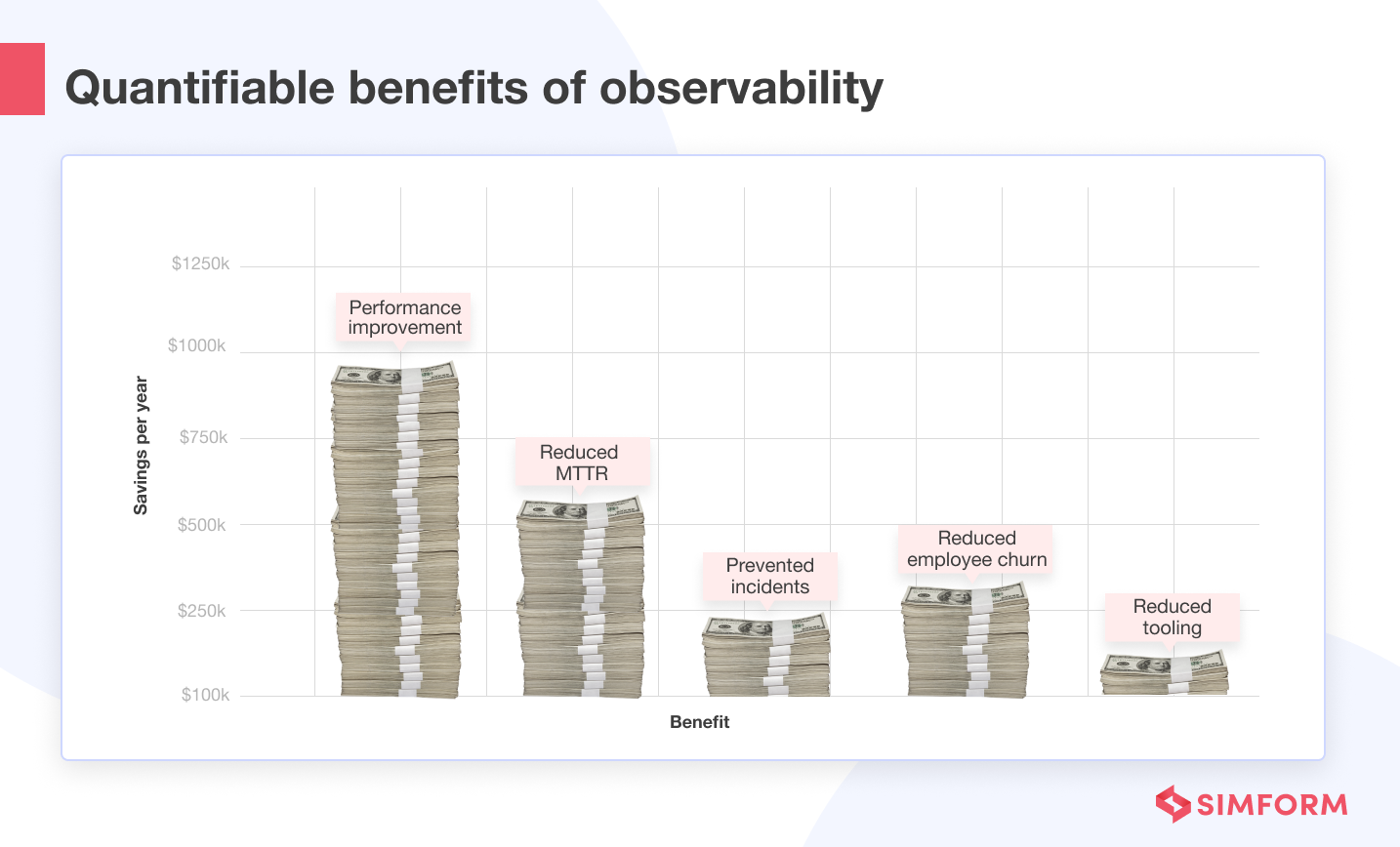
It’s easier to assess the ROI if you can quantify the returns. Observability has multiple measurable benefits. Let’s review some of them and see how they can contribute to your organization’s profitability.
1. Performance improvement over time
Modern systems have a variety of components. Consequently, there are exponentially more ways for them to malfunction. And it’s incredibly difficult to get to the root cause of issues in the case of distributed systems.
But with observability, you can unearth the root cause quickly. Sound observability implementations lead to fewer outages, improved uptime, and better performance. The improved performance also leads to fewer SLA violations, which translates into millions of dollars in savings for larger enterprises.
In fact, Forrester’s research suggests that observability can lead to savings of $1.9 million over three years.
World Fuel Services provides fuel to aviation, marine, and transportation industries and is a Fortune 250 company. If its application goes down, the consequences can be passenger flight delays, bottlenecks in supply chains, and more. So the stakes are always high with the operations.
Before making the system observable, one of its major challenges was that engineers had to manually login into the system and go through logs to locate the issues. It was an inefficient and time-consuming process. And the company used to bleed dollars throughout this manual troubleshooting process.
Post observability, it has not only reduced the troubleshooting time from 1 hour to 15 minutes but also experienced a significant improvement in uptime. All the necessary information is available to engineers on a single dashboard, and they get notified whenever the system is under stress.
With observability, it can proactively address issues, which has massively contributed to overall performance improvement.
2. Reduced MTTR
When managing a modern distributed system, you’ll encounter many issues. That’s bound to happen. But successful businesses and their systems possess the capability to address the issues very quickly. So much so that end users never even realize there was some backend problem.
Application-wide observability enables you to identify and resolve issues as quickly as possible. And the three pillars of observability (logs, metrics, and traces) play a massive role in the process.
The ‘metrics’ alert SREs when something goes wrong. It’ll let you know that the system is under stress and something’s not within the acceptable range. Then you can use ‘traces’ to locate the problem. Traces point you to the right data stream and save a lot of valuable time in finding the problem sources. Finally, ‘logs’ inform you about the specific operations that caused the issues. The relevant party can then resolve the issue and ensure it doesn’t happen in the future.
Without observability, it’s challenging to find the problem, let alone resolve the issue.
How does reduced MTTR leads to reduced costs?
IT issues lead to loss of revenue, loss of reputation, and a dent in developer productivity. Every time a new problem surfaces, the developer has to leave whatever they are doing and address the issue immediately.
The time spent away from productive tasks can be quantified. And when you look at the cost associated with this wasted potential, it can go up quickly for any large organization.
But the good news is that organizations have reported up to a 95% reduction in MTTR after implementing observability. And for a medium to large-sized enterprise, the savings after reducing the MTTR can amount to up to $2 million in three years.
3. Prevented incidents
Observability not only enables you to respond to issues quickly but helps prevent them as well. This is especially true for teams following the observability-driven-development approach.
Legacy monitoring systems used to rely on specific system outputs to detect issues. But that’s not the case with observability. It analyzes the entire system and all its outputs to make sure everything is working as expected.
With observability, SREs can set up notifications for when certain SLOs aren’t met. So they know something’s wrong as soon as a system shows the first sign of unexpected behavior. And often, the heads-up is enough for them to fix the issue before it blows up into a full-fledged IT incident.
For instance, the German manufacturer Zeppelin uses observability to predict failures in spark plugs. To put things into perspective, a spark plug failure can snowball into plant shutdowns. Their anomaly detection models use machine learning and monitor exhaust temperatures and spark plug voltage. It contextualizes historical data against real-time figures to notify engineers about any unwanted deviations.
Organizations can reduce upto 15% of overall incidents using proactive notifications from observable systems. And based on the size and nature of the business, this can amount to over $200k per year.
4. Reduced employee churn
Consider this scenario. There’s a company with a large and complex software infrastructure. As systems have grown complex over the years, only a handful of developers and operations engineers possess a deep understanding of systems and their nuances.
And because they understand the system so well, they are always responsible for debugging and resolving issues. Consequently, the experts need to spend a significant amount of time responding to alerts and detecting issues that they’d have otherwise spent on more meaningful tasks. At the same time, the less-experienced developers lack system understanding, feel they aren’t moving the needle, and their morale goes down.
Now consider another scenario.
There’s still a large and complex software infrastructure. But this time, it’s observable. So when problems occur, it’s no longer the responsibility of just the ‘hero’ developers and operations engineers.
Firstly, the number of severe issues is significantly low. Secondly, observability provides enough clarity and context for issues that even less-experienced employees can deal with them. Finally, the experts now have enough time to innovate and work on new features, while the up-and-comers feel motivated since they also become key contributors to the business.
Out of the two scenarios above, where do you think employees will want to work?
The company in the first scenario will obviously face serious employee churn. They’ll keep losing valuable human resources. They’ll also have to constantly spend money to attract, train, and retain new developers and engineers. And then it also takes up to 1 or 2 months to bring anyone up to speed.
Companies have reported their employee churn rates going from 15% to 1.5% after employing enterprise-wide observability. Plus, it can help you save around $300k every year.
5. Reduced tooling
Those who don’t have enterprise-wide observability rely on varied tooling to monitor the health of individual systems within the infrastructure. While the individual tools do a good enough job of monitoring a single entity, it’s always a challenge to put things into perspective for a broader process.
There’s much to manage in a modern system – multi-cloud, hybrid-cloud, IoT, microservices, containers, web applications, CI/CD pipelines, and more. And things are only going to get more complex in the future.
With observability, you get a unified way to monitor everything from a single dashboard and ensure the system performs to the best of its capabilities. And if observability covers everything, there is no need to separate tooling for individual entities.
Companies without observability solutions may have more than 15 different monitoring solutions. Think of all the licensing, management, and maintenance costs associated with these tools. Observability can save you all the money you’d otherwise spend on individual tools.
Observability adoption can save more than $100k every year in terms of reduced tooling in a medium to large-sized enterprise that uses several individual monitoring tools.
The exact ROI of observability for your business will depend on multiple factors, such as the nature of the business, company size, tech dependency, and more. However, you can rest assured that observability will help you save significant resources against the abovementioned factors.
And while it’s possible to assign a monetary value to the factors we discussed above, observability has a few benefits that are tricky to quantify. You’ll know why as we discuss them in the next section.
What are the non-quantifiable benefits of observability?
There are certain things that you can’t put a number on but value dearly for business success. Culture, customer experiences, brand perception, and innovation speed are some factors.
Observability affects some of these elements. And it makes complete sense for you to factor these in the cost-benefit analysis. So here are some of the non-quantifiable benefits of observability.
1. Lesser time to value
The modern consumer needs demand your business to innovate at a high pace. And with observability, teams can ship work as soon as it’s ready. They can then closely monitor how the system performs in real-time.
Before observability, teams would get to know about a lot of issues from customer support tickets. And the damage is usually done by this moment. But not anymore. Observability provides fast, accurate, and automated feedback to the developers. This gives them the confidence to roll out features as soon as they are ready. Based on the feedback, they can prioritize issues and resolve them quickly.
Meliá, a global hotel chain, wanted to innovate quickly to keep up with the modern travel trends after the pandemic. So it adopted the cloud-native architecture to roll out more digital features in line with its customers’ preferences.
And modern architecture requires modern monitoring ways to continue innovation at high speeds. So Meliá made its system observable.
Meliá’s primary goal was to reduce in-person contact for their guests. So they were rolling out various digital features such as check-in through apps. Observability gave them the confidence to ship these features quickly without worrying about anything going wrong.
The teams could understand and monitor how customers interacted with their apps and if anything needed changes. This allowed them to increase the volume of digital transactions from 40% in 2019 to 80% post-pandemic.
2. Improved customer experiences
Speed, convenience, and quality of service are top things valued by 70% of customers. They are willing to spend up to 16% more on premium services. Businesses that fail to adhere to high customer expectations face dire consequences. For instance, a site that takes too long to load will lose around two-thirds of its customers.
With so much at stake, delivering top-notch digital experiences has become the primary objective of every business. And for those with complex software infrastructures, observability is a boon.
As mentioned in the previous section, observability provides developers real-time insights into the system’s behavior. It means they can address issues immediately and save customers from unpleasant experiences.
Before observability, a lot of glitches used to go unnoticed simply because static monitoring systems weren’t paying attention to those specific parameters.
Unfortunately, these glitches would then negatively impact the customer experience.
However, observability combs out all such anomalies and helps teams focus their engineering efforts toward the best digital experiences. They can quickly trace the issue to the faulty app, process, or device and resolve it.
3. Improved innovation
Businesses that don’t innovate don’t do well in the long run. Look at any digital service you use and see how far they’ve come in the past 5 years or the decade. Those who didn’t evolve didn’t make it.
But innovating continuously for the rapidly evolving ecosystem is no easy feat. After all, modern consumers need all the new features without any planned/unplanned downtimes, glitches, and other disruptions.
Observability enables developers and engineers to find the perfect balance between innovation and prime performance. AI-powered observability develops a comprehensive understanding of systems, processes, and operations and implements a continuous learning cycle to stay above baseline performance metrics. Anything that isn’t coherent with the high-performance standards gets scrutinized and improved upon immediately.
With observability, businesses are more confident than ever to aggressively innovate to deliver the most meaningful and engaging digital experiences. And while all these benefits are great, there’s still one question left to answer.
What is the cost of implementing observability?
Observability is undeniably a critical capability for enterprises eyeing growth. But it can also come at a very steep price if not careful. Since the cost of observability is usually proportional to the use, it’s common for enterprises to go over budget with observability.
But then, what is “over budget” for observability?
And like all things in life, “it depends.”
It depends on
- The use cases
- Environments you want to observe
- Tools you use
Charity Majors, CTO at Honeycomb, suggests that the observability budget should be 20-30% of the infra spend on the enterprise, which sounds about right.
But do not confuse this to be just for observability tooling. There are associated costs too. For example, you’ll have to pay for the hardware to support the tool, and you’ll also have to get a few hands on deck to manage the observability tools.
In order to get the best ROI for observability, you should pay close attention to what you observe. There are instances when enterprises gather a whole bunch of data, but only a handful or none is useful.
Then there is also the case of employing multiple tools to do the same thing. There should always be careful deliberation in the discovery and planning phases to avoid such wastefulness.
27.5% of enterprises find their observability tooling too difficult to use and end up not using it. So there is also the need to ensure appropriate tech competency to make the most of observability tooling.
Conclusion
Observability is undoubtedly essential for enterprises and anyone building a complex cloud infrastructure. Legacy monitoring can’t do the job anymore, and it’s time for you to find ways to make the system observable.
At Simform, we’ve successfully built multiple observable systems and can also help you adopt observability. Not only can we help you decide what environments to observe and which tools to get, but our infrastructure management experts can also assist you with the entire setup and monitoring process.
Feel free to connect if you wish to know more about how observability can benefit your business. We’ll be more than happy to answer questions specific to your business and cloud infrastructure.
