Today, the volume of data created, captured, copied, and consumed worldwide is forecast to be 97 zettabytes. (One zettabyte holds 1 billion trillion bytes!). And it is projected to grow to more than 180 zettabytes in 2025.
With data multiplying at such staggering rates, enterprises have started leveraging it to facilitate business growth and expansion. And to derive and produce actionable insights, data pipelines are employed. They not only move data from one place to another. But they gather, process, transform, manage, and utilize data to facilitate analysis and unlock value from modern data.
This blog is a deep dive into what data pipelines are and how they can help businesses gain a competitive edge with this comprehensive guide. It also discusses types of data pipelines, their architecture, use cases, examples, and tools.
What is a data pipeline?
A data pipeline comprises end-to-end operations (or a series of steps) that collect raw data from sources and deliver insights unlocked from it to the target destination. The steps can involve:
- Filtering data
- Aggregating date
- Enriching data
- Analyzing date it in motion
- Storing or running algorithms against the data
The pipeline is made up of a set of tools, technologies, and activities that move data from one system with its method of storage/processing to another system where it can be stored and managed differently.
In short, each step delivers an output which is input for the next step. What happens to the data across all the pipeline steps depends on the final target destination and the business use case.
Ultimately, the data is transformed in a way that is primed for analysis and deriving business insights, which is the key aspect of a data pipeline’s utility. A well-organized data pipeline can lay a foundation for various data engineering projects – business intelligence (BI), machine learning (ML), data visualization, exploratory data analysis, predictive analysis, and more.
To understand in detail how a data pipeline works, let’s see what components it is made of.
Data pipeline process & components
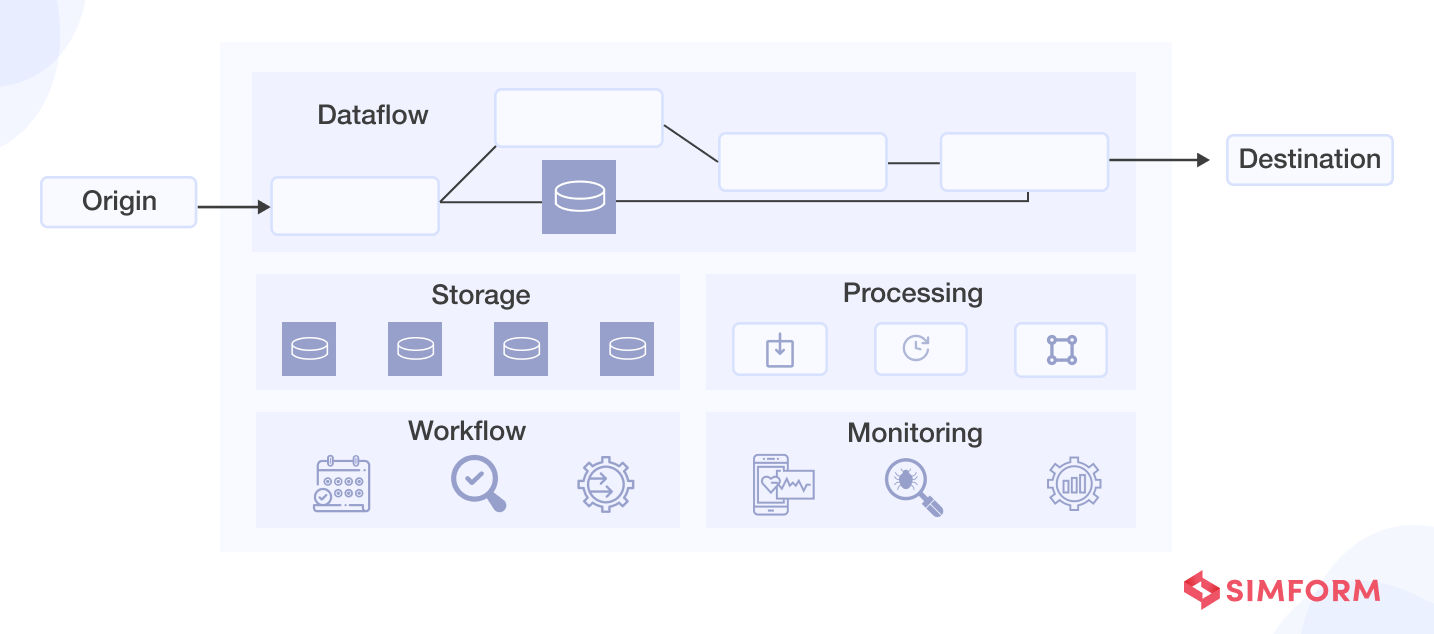
- Destination
It’s a little odd to start at the final point of the pipeline, but it helps design the pipeline by answering questions such as – where data is needed, why it is required, how fast it is needed, will the data be moved to a data store, are you providing data to a dashboard or analytics application, etc.
The destination depends on your business use cases. For instance, is the data sourced to power analysis (data visualization and analytical tools) or simply moved to storage (in a data lake or a data warehouse)?
- Origin
It is the point where data enters the pipeline. The data source may be internal or external and commonly include mobile or web apps, websites, IoT devices, SaaS apps, databases or other storage systems, business applications, etc.
Most data pipelines collect raw data from multiple sources via API calls, a push mechanism, a webhook, or a replication engine that pulls data at regular intervals. The data may be synchronized at scheduled intervals or in real time.
- Data flow
Once you know what goes into the data pipeline and what comes out, it is time to describe how the inputs will travel through the pipeline to become desired outputs.
Data flow is the sequence of processes and data stores through which the data moves to the destination from the origin. It can be challenging to choose as there are several data flow patterns (such as ETL, ELT, stream processing, etc.) and several architectural patterns (such as parallel, linear, lambda, etc.).
- Storage
It is where data is stored at different stages as it moves through the pipeline. The storage choices depend on numerous factors such as the volume of data, query requirements, users and uses of data, etc. However, a data flow may consist of processes that do not need intermediate data stores.
- Processing
It includes steps and activities performed to ingest, transform, and deliver the data. Together with data flows, processing works as the core of a data pipeline.
Data ingestion is performed mainly in batches or real-time (streaming), depending on the data source, type of data, and other factors. Data transformation changes the data to meet specific needs and goals, but mainly to get the right data in the right forms/formats for intended uses. More specific transformations may include formatting, aggregation, sorting and sequencing, de-duplication, etc. Lastly, the delivery processes depend on the destination and use of the data.
- Workflows
They define and manage the sequences and dependencies of the pipeline processes. For example, ensuring necessary upstream tasks or completing jobs successfully before executing a specific task or job.
- Monitoring
It involves observing the data pipeline to ensure it is healthy and performing as required. For instance, to confirm whether the pipeline maintains efficiency with growing data load or whether the data remains accurate as it goes through stages and no chunk is lost along the way.
- Technology
It includes all the tools and infrastructure that enable data flow, processing, storage, workflows, and monitoring.
Now that you know the what and how of data pipelines, let’s discuss why you should have one.
Data pipeline benefits
Data pipelines are a must if you plan to use data for different purposes. They offer a reliable infrastructure for organizations to consolidate and manage their data, supporting daily operations and powering analytical tools. Below are some more benefits of data pipelines.
- Data quality and reliability
There are many points during data flow where bottlenecks or data corruption can occur. But data pipelines help keep data organized at all times. They make data monitoring easy and accessible to all users. Moreover, it combines data residing in multiple systems and sources to make better sense. Thus, data pipelines help increase data quality, reliability, and availability.
- Flexibility and incremental builds
When data is gathered from varied sources, it comes with different features and formats. A data pipeline allows you to transform and work with different data irrespective of their characteristics. Moreover, such flexibility will enable you to create dataflows incrementally.
- Automation and efficiency
A data pipeline can be broken down into repeatable steps, which pave the way for automation. It minimizes the likelihood of human errors, enabling smooth data flows and processing at a greater speed. Moreover, it can also allow processing of parallel data streams simultaneously as redundant steps are eliminated or automated.
- Analytics
Data pipelines consolidate data from various silos in a way that is optimized for analytics, allowing quick analysis for business insights. It also enables real-time analytics, helping you make faster data-driven decisions.
- Value
Data pipelines allow you to utilize machine learning, business intelligence, and data visualization tools. It helps extract additional value from your data. You can conduct a deeper analysis to reveal hidden business opportunities, potential pitfalls, or ways to enhance operational processes.
Data pipeline architecture
From a conceptual perspective, here is what the data pipeline architecture should look like. It outlines all the processes and transformations a dataset undergoes from collection to serving.
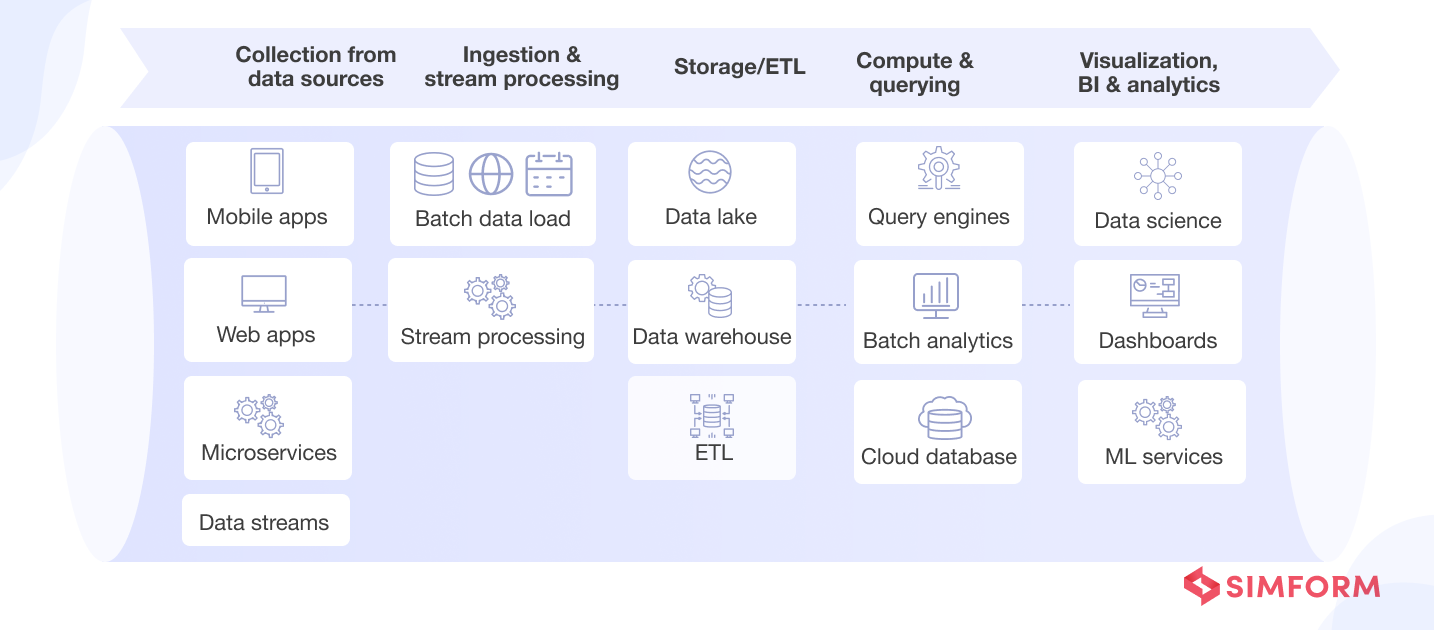
From an architectural perspective, it is an arrangement of tools and technologies (for components discussed above) that connects disparate data sources, data processing engines, storage layers, analytics tools, and other applications to deliver accurate, actionable business insights. Below is an example of a specific set of tools and frameworks for core steps that make up the data pipeline architecture.
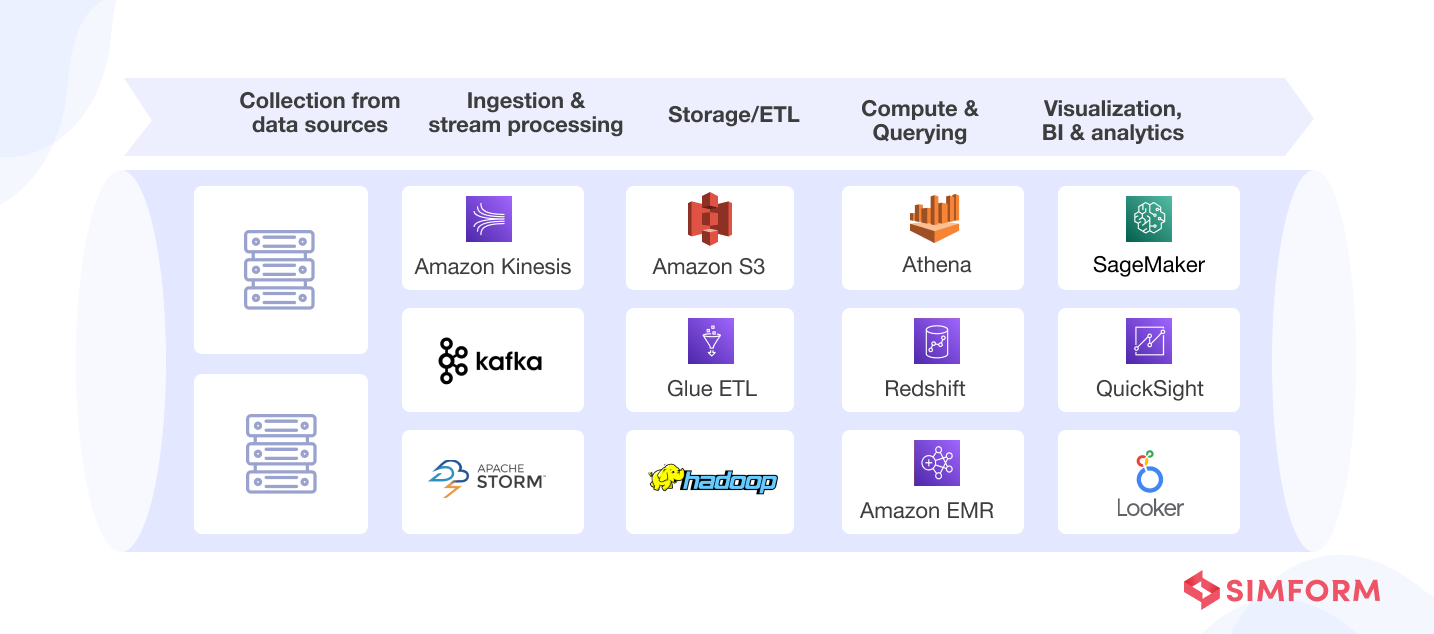
- Collection
As the first step, relevant data is collected from various sources, such as remote devices, applications, and business systems, and made available via API. Here, message bus systems (like Apache Kafka) are also used to capture event data and ensure that data is dropped or duplicated while in transit to their destination.
- Ingestion
Here, data is gathered and pumped into various inlet points for transportation to the storage or processing layer. It can be done in two forms – batch blobs and streams. Batch ingestion loads and ingests data into repositories at set time intervals in batches. In contrast, streaming ingests data as soon as it is generated at the source and processes it for real-time insights.
Additionally, there can be jobs to import data from services like Google Analytics. To know more, check out this detailed blog on data ingestion.
- Preparation
It involves manipulating data to make it ready for analysis. Data may be cleansed, aggregated, transformed (converting file formats), and compressed to normalization. It may also be blended to provide only the most valuable chunks to the users so that queries are quick and inexpensive.
- Consumption
Prepared data is moved to production systems for computing and querying. For example, to facilitate analytics, business intelligence (BI), visualization, and other decision-making engines or user-facing applications.
A series of other jobs are also executed during data transformation and processing. These jobs embed data quality checks, automation for repetitive workstreams, and governance to ensure data is cleansed and transformed consistently. Thus, there are additional aspects across the whole data pipeline as follows:
- Data quality check
It checks the statistical distribution, anomalies, outliers, or any other tests required at each fragment of the data pipeline.
- Cataloging and search
It provides context for different data assets. For example, events in the data lake, tables in the data warehouse, topics in message queues, etc. Data is profiled and cataloged to provide better visibility into the schema, lineage describing, and statistics (such as cardinality and missing values) for data scientists and engineers.
- Governance
Once collected, enterprises need to set up the discipline to organize data at a scale called data governance. It links raw data to business context, making it meaningful, and then controls data quality and security to fully organize it for mass consumption. Moreover, security and governance policies are followed throughout the data pipeline stages to ensure data is secure, accurate, available, and anonymized.
- Automation
Data pipeline automation handles error detection, monitoring, status reporting, etc., by employing automation processes either continuously or on a scheduled basis.
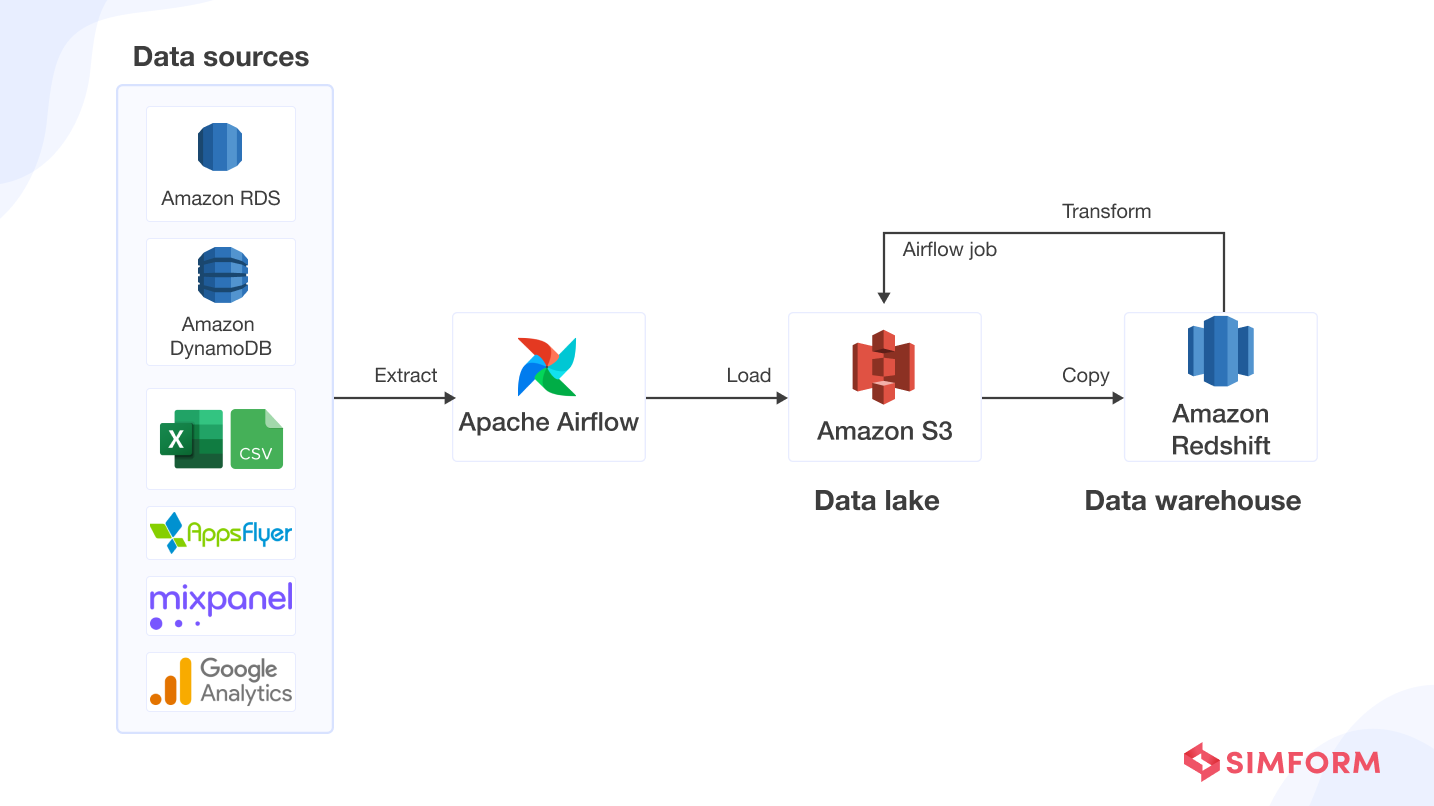
Now, to see these components come into play here is a more comprehensive data pipeline architecture example taken from AWS.
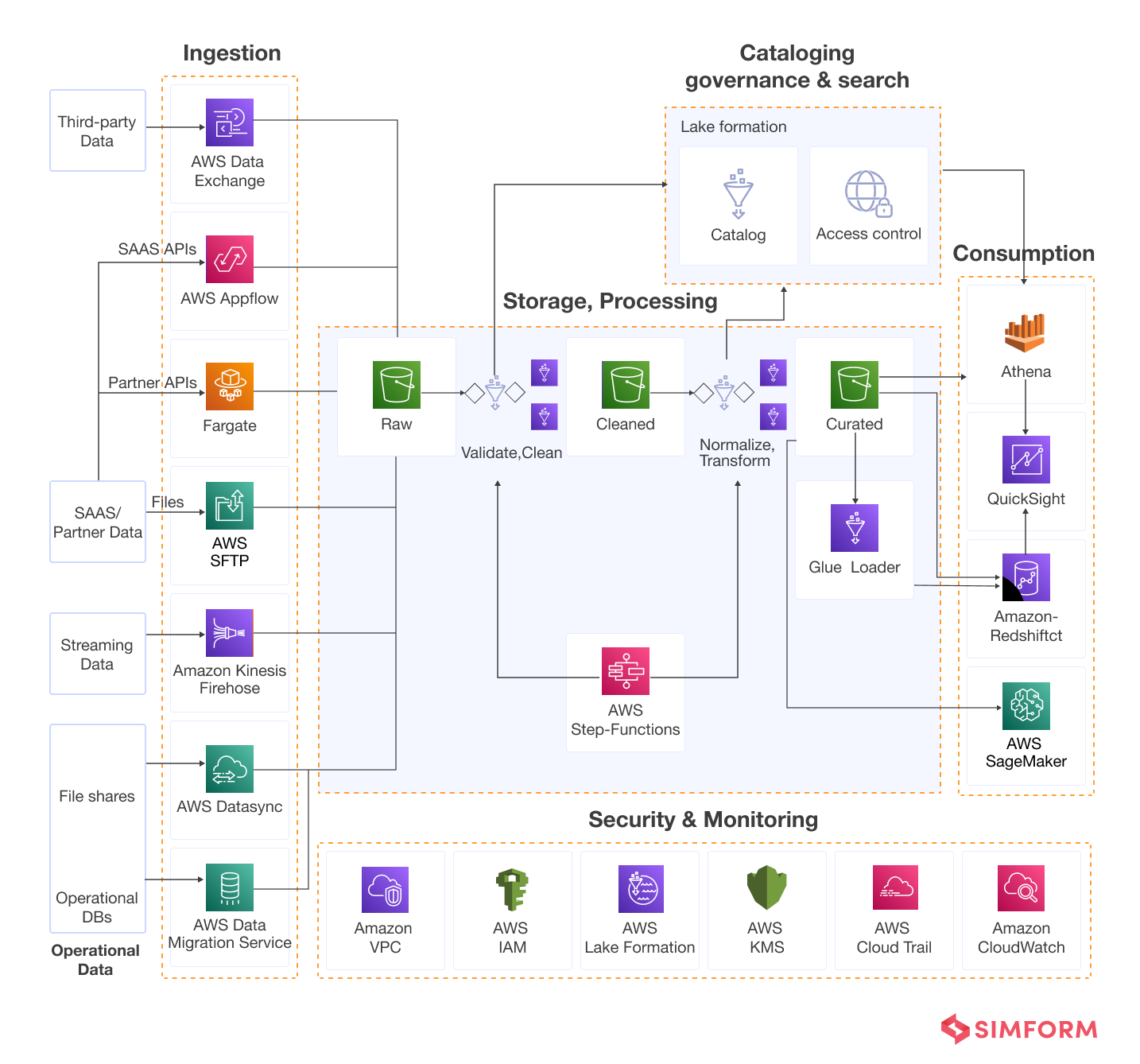
Data pipeline considerations
You can build a data pipeline in numerous ways, as there is no one-size-fits-all architecture. However, now that you are familiar with the basics of building data pipelines, you can better understand the tradeoffs associated with architecture decisions. Here are a few considerations required (but not limited to):
- Will your pipeline handle streaming data?
- What is the size, velocity, and frequency of your data?
- How much and what types of processing will happen in the pipeline?
- Do you plan to build the data pipeline with microservices?
- Are there specific technologies or tools your team is already well-versed in programming and maintaining?
A major consideration will also be where to implement your data pipeline, and the options are discussed below.
Implementation options for data pipelines: cloud or in-house?
- In-house/On-premise
With an in-house data pipeline, you buy and deploy software and hardware for your on-premise data center. In addition, you maintain it yourself and take care of aspects such as backup, recovery, pipeline health checks, increasing capabilities, etc. It is time-consuming and resource-intensive, but it will give full control over the data pipeline.
However, on-premise data pipelines also come with challenges. For instance, different data sources have different APIs involving different technology types. So, developers need to write new code for every new data source added or rewrite it if a vendor changes their API. Other challenges may include speed, scalability, low latency, elasticity, and continuous efforts for maintenance.
- Cloud
Modern data pipelines may require an architecture that handles workloads parallelly with resources distributed across independent clusters. The clusters can also grow in size and number quickly.
Here, relying on the cloud can enable organizations to scale storage and compute automatically. In addition, predicting data processing times is easier as new resources are added instantly to support a data volume spike. Other pros can include data security, near-zero downtime, agility, etc.
However, there may be cons, such as vendor lock-in and the cost of switching vendors if a solution doesn’t meet your needs.
Data pipeline vs. ETL
Terms such as data pipeline and ETL are used interchangeably sometimes. However, ETL is a subset of data pipelines, and below are their other distinguishing features.
- ETL stands for extract, transform, load, and follows the specific sequence.
Extract: pulls the raw data from the sources.
Transform: converts the format of raw data to match the format of the target system.
Load: places the data into target systems such as a database, data lake, or application.
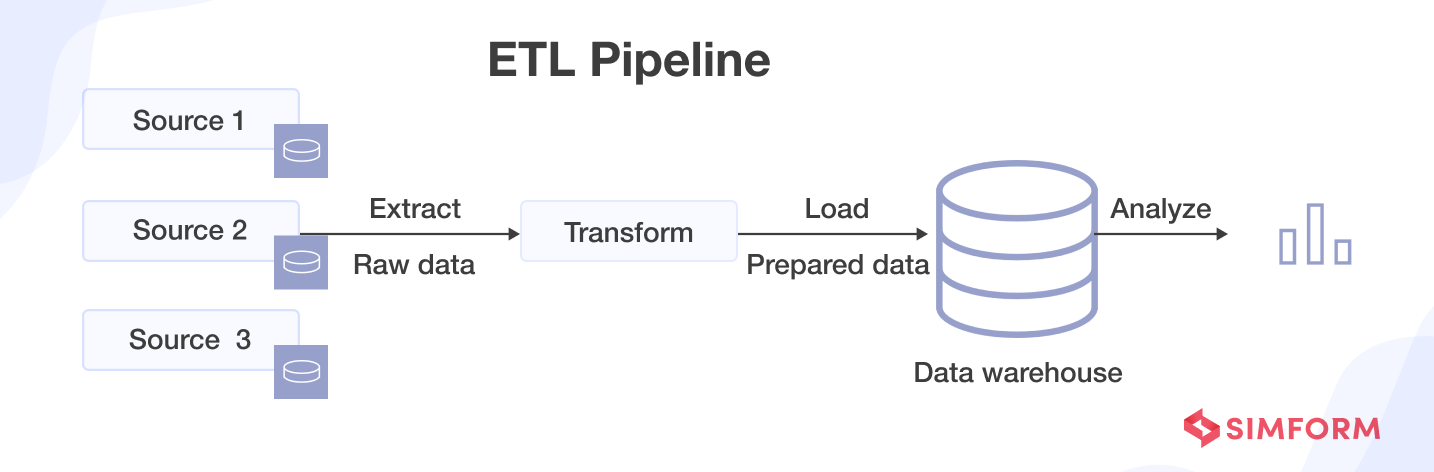
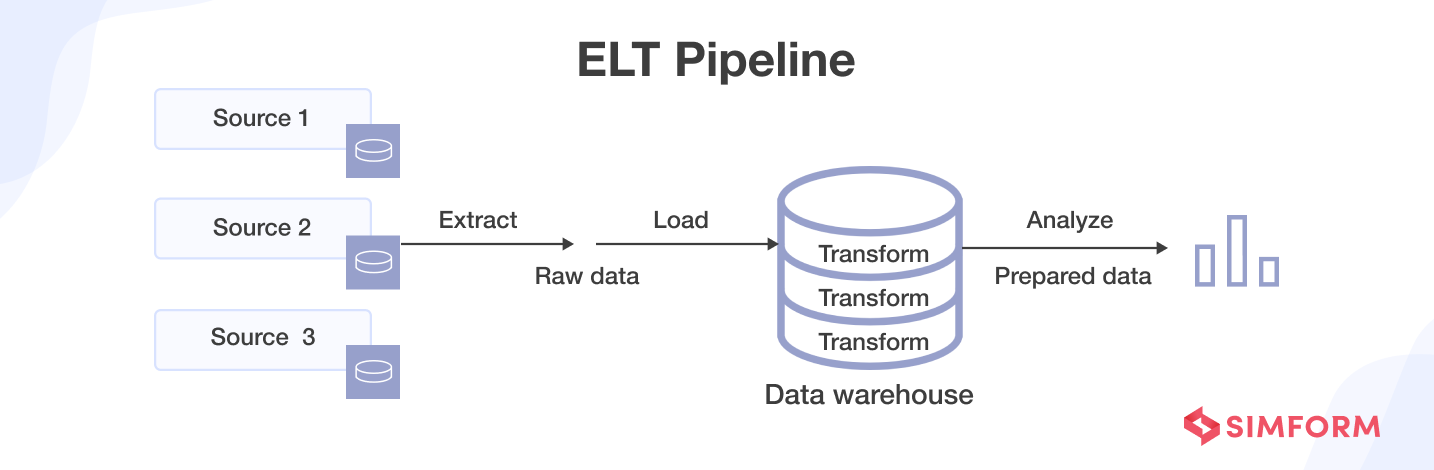
However, all data pipelines do not necessarily follow this sequence. ELT(extract, load, transform) is one such example. ELT pipelines have become popular with the arrival of cloud-native tools.
- ETL usually implies the use of batch processing
ETL can support use cases that rely on batching and historical data. It is also appropriate for small data sets that require complex transformations. But as we discussed above, data pipelines have a broader scope and can also include stream processing.
Check out how we built a scalable ETL architecture for a big data & analytcis solution for school distrcits
While data ingestion still occurs first with ETL pipelines, transformations are also applied after the data has been loaded into the cloud data warehouse in other cases. This approach ELT – extract, load, transform – differs from ETL in the sequence of processes. It can be appropriate when large, unstructured datasets are involved, and speed and timeliness play a key role.
Data pipeline examples & use cases
Data pipelines can be architectured in many different ways. Mainly, there are batch-based data pipelines, real-time streaming pipelines, or a mix of both. Common examples for each type of pipeline are explained below.
Batch data pipeline
Batching or batch processing pipelines move data from sources to destinations in blocks (batches) on a one-time or regular scheduled basis. Once ready for access (after storing/transformation), batches are queried for data exploration and visualization. Typically, batches are scheduled to occur automatically or triggered by a user query or an application.
Below is what a batch processing pipeline architecture would look like:
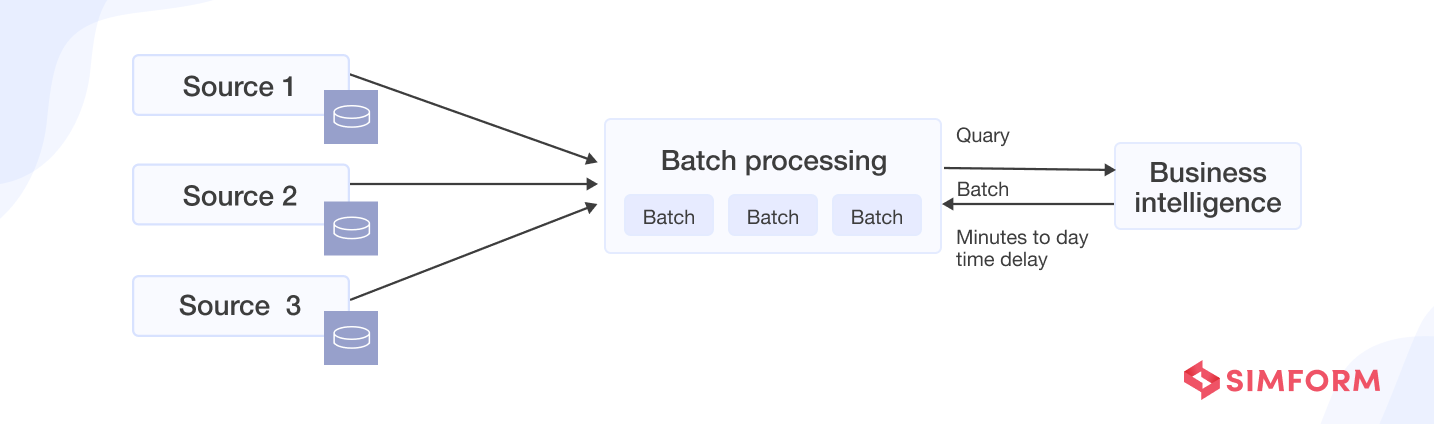
Depending on the size of the batches, the pipeline can be executed in intervals of a few minutes to a few hours and even a few days. Moreover, batches are loaded into a repository per set intervals during periods of low user activity (such as nights, weekends, and off-peak business hours) to avoid overloading source systems.
Use cases for batch data pipelines: Batch processing jobs tend to work well for
- Large volumes of datasets
- Complex analysis of large datasets
- BI and analytics to explore and gain insights from information/activities that happened in the past
- When there is no immediate need to analyze specific datasets
- When time sensitivity is not an issue, such as payroll or billing. Or low-frequency reports that use historical data
To give a real-life example, Halodoc, a healthcare application based in Indonesia, uses batch pipelines to migrate all relevant data (sensitive and primarily transactional) of millions of users to their data warehouse periodically. The combinedly stored and transformed data is then used for analysis and quick decision-making. Below is Halodoc’s batch pipeline architecture:
Streaming pipeline
Streaming pipelines enable real-time analysis with a continuous collection of data from various sources, such as change streams from a database or events from messaging systems and sensors. It also updates metrics, summary statistics, and reports in response to every next available event.
A streaming-based pipeline will have the following architecture:
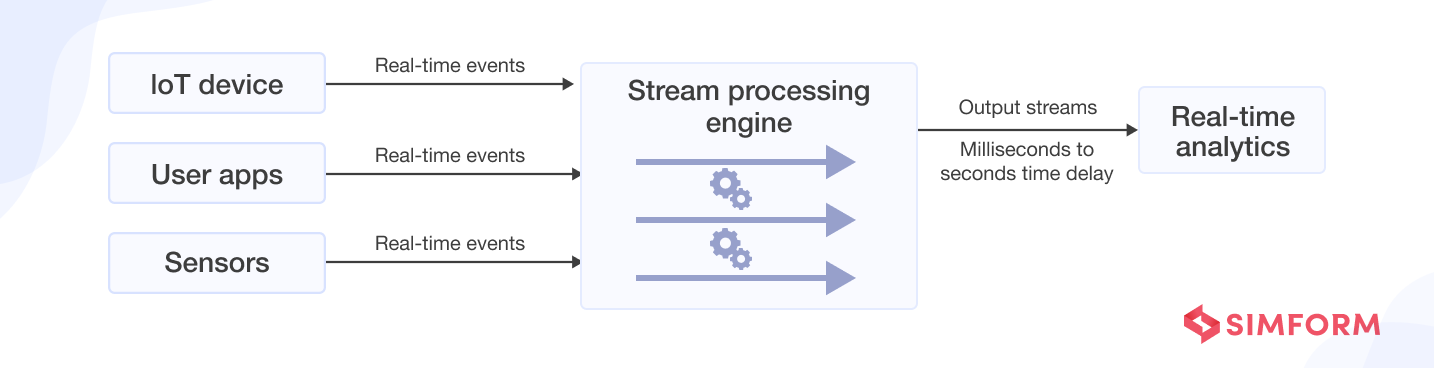
Use cases for streaming data pipelines: They are optimized to process data as soon as it is generated at the sources. Thus, it enables
- Real-time analysis, BI, and decision making
- Smart, real-time monitoring of infrastructure performance to avoid lags, such as in a fleet management business operating telematics systems
- Data to be continuously updated (such as for apps or point-of-sale systems that need real-time data to update inventory and sales history of their products)
- When data freshness is mandatory for organizations to react instantly to user activity or market changes
- Other use cases like fraud detection, log analysis, database migration, sensor data, online advertising, etc.
For instance, if you want to capture live IoT data streams to perform analytics for corrective actions and alert notifications, below is what a serverless data pipeline in AWS will look like. Data is continuously ingested in Snowflake with tools such as Amazon Kinesis Data Streams, Amazon Kinesis Firehose, etc.
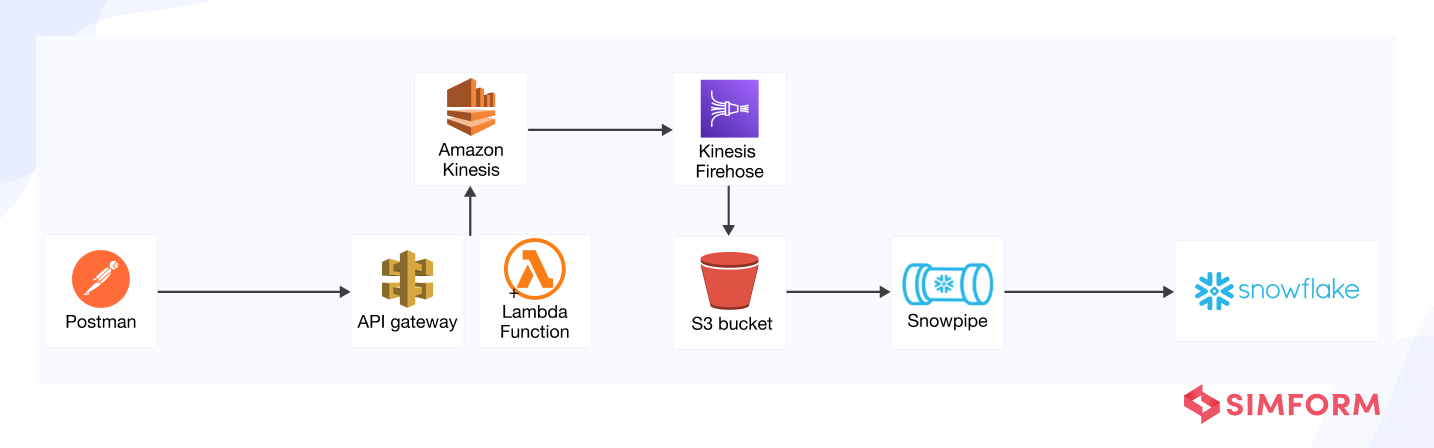
To give a real-life example, Simform built a tweets-driven market intelligence solution for the pharma industry. We needed to capture and analyze millions of raw tweet data of KOLs based on multiple factors and sentiments to provide real-time insights and time-saving analysis.
So, we integrated Twitter Historical PowerTrack API that gives access to the entire historical archive of public Twitter data. And we designed a system to capture this data in batches of 500 tweets every 2 hours, keeping the data up to date. Read the full case study to find out how we successfully build a real-time analytics solution to achieve the desired results.
Lambda architecture
Popular in big data environments, Lambda architecture uses a hybrid approach enabling both historical batch analysis and real-time use cases. To facilitate this, it has a data ingestion consumption layer, batch layer, and streaming or speed layer. Further, it has a service layer where combined results from both batch and streaming layers provide unified desired results.
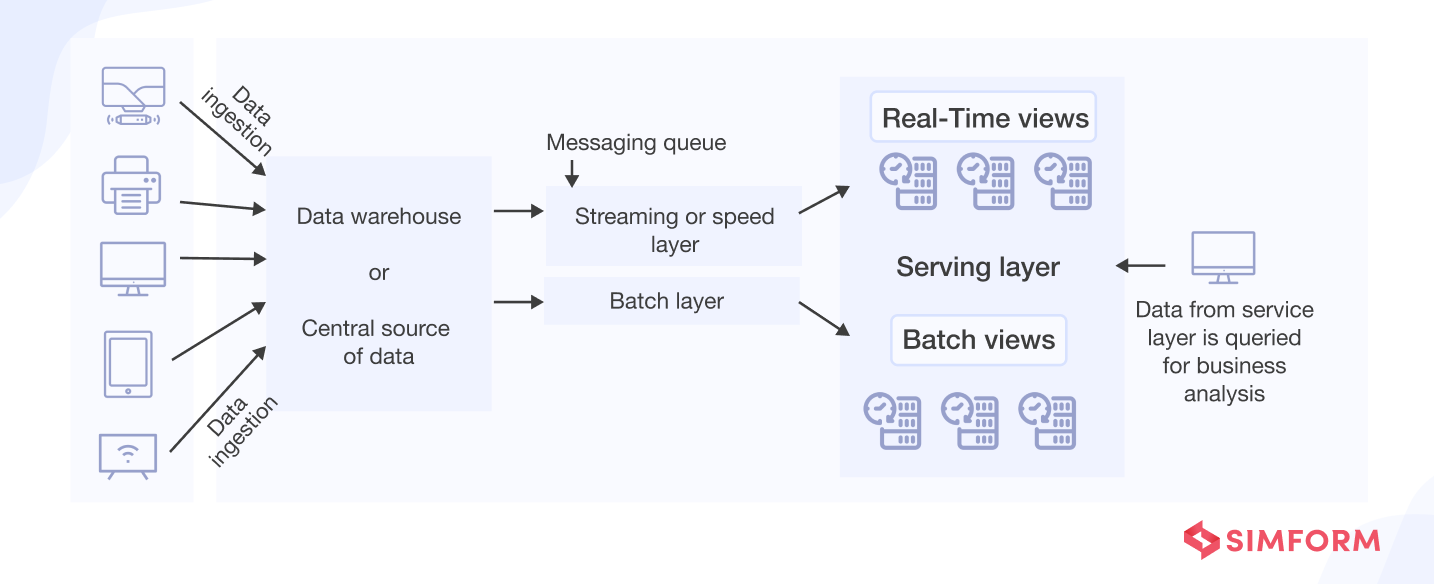
Another key aspect of Lambda architecture is that it encourages storing data in raw format. Thus, you can continually run new pipelines to correct any errors in the prior pipelines or add new data destinations to enable new types of queries.
Use cases for Lambda architecture: It can be effectively utilized to balance throughput, latency, scaling, and fault tolerance for achieving accurate and comprehensive views from batching and analyzing data on the fly.
Here is what a Lambda architecture will look like with data pipeline tools.
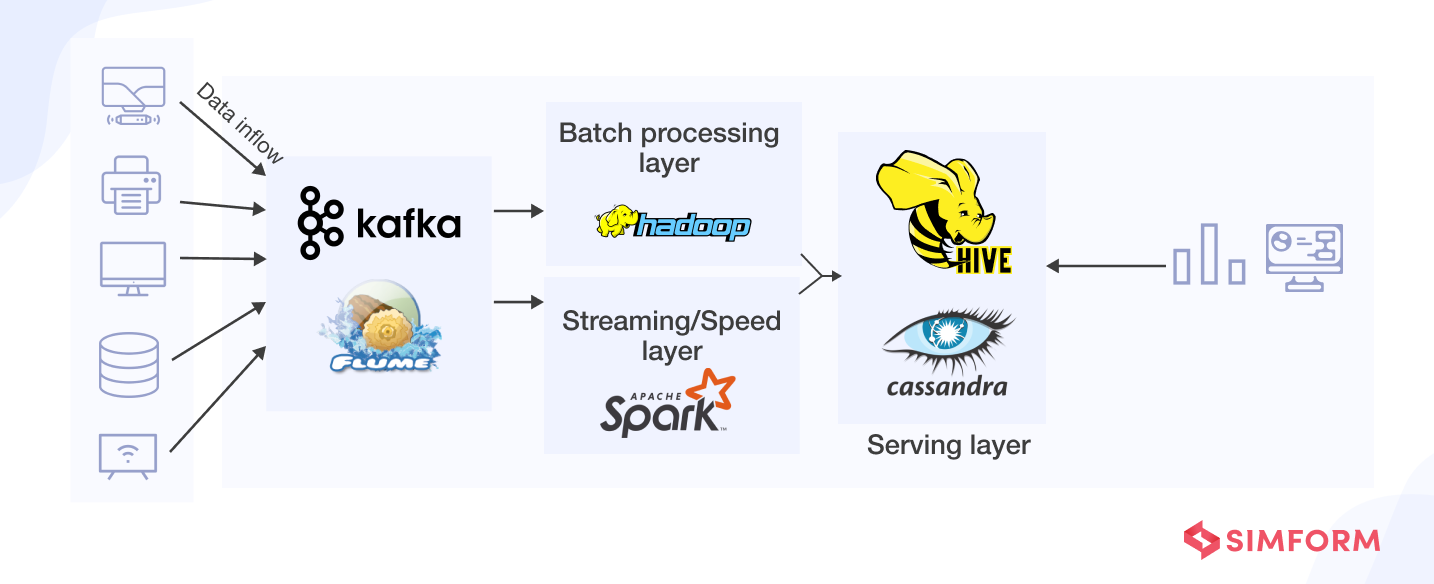
Use cases of data pipelines
Here are other broad applications of data pipelines within a business:
- Data visualization
It represents data via graphics such as graphs, plots, charts, maps, even animations, and more. Such visual displays of information help understand and communicate complex data relationships and data-driven insights easily.
- Exploratory data analysis (EDA)
Data scientists use it to investigate and analyze data sets and summarize their main characteristics (often employing data visualization). It helps them determine how to best manipulate the data sources to get required answers. Thus, data scientists can quickly discover patterns, test a hypothesis, spot anomalies, check assumptions, etc.
- Machine Learning (ML)
It is a branch of computer science and AI (artificial intelligence) that uses data and algorithms to imitate how humans learn, gradually improving its accuracy. The algorithms are trained through statistical methods to make classifications or predictions and uncover critical insights in data mining projects.
Data pipeline tools
A data pipeline may be designed for a simple extraction and loading process. Or it can be designed to handle data in a more advanced manner, such as to train datasets for machine learning. The choice of tools and tech depends on various factors like data volumes, use cases for the pipeline, organization size and industry, budget, etc. Here are some popular data pipeline tools.
- Data ingestion tools
The ingestion or consumption layer can include Apache Kafka, Flume, HDFS, Amazon Kinesis, etc. For instance, Amazon Kinesis Firehose is a fully managed AWS service that easily loads streaming data into data stores (or data lakes, etc.) and scales automatically.
- ETL tools
It can include data preparation and integration tools such as AWS Glue, Talend Open Studio, Pentaho Data Integration, and many more. For instance, Glue is a fully managed extract, transform, and load (ETL) service that efficiently extracts and loads data for analytics.
- Real-time streaming tools
It includes tools such as Apache Storm, Kafka, Amazon Kinesis, Google Data Flow, Azure Stream Analytics, and more. For example, Kinesis Data Streams helps collect, ingest, and analyze real-time streaming data to react quickly.
- Batch workflow schedulers
It includes tools like Luigi. Developed by Spotify, Luigi enables the orchestration of different types of tasks such as Hive queries, Spark jobs, etc.
- Data warehouses
It includes repositories to store data transformed for a specific purpose, such as Amazon Redshift, Google BigQuery, Azure Synapse, Snowflake, and more.
- Data lakes
It stores raw data in its native formats until needed for analysis. Major cloud service providers (AWS, Microsoft Azure, Google Cloud, etc.) offer data lakes for massive data volumes.
- Big Data tools
It comprises tools from all groups mentioned above that support end-to-end big data flows. It can include Spark and Hadoop and platforms for batch processing, Apache HBase and Cassandra to store and manage massive amounts of data, and many other tools. For example, Apache Airflow can easily schedule and operate complex data or ETL pipelines using its workflow engine.
Check out how we used Apache Airflow for a data-driven automation platform for auto dealerships
Build robust data solutions with Simform
As data volume, velocity, and variety continue to grow, the need for scalable data pipelines is becoming increasingly critical to business operations. While the aspects we discussed above barely scratch the surface of the many potential complexities of data pipelines and their architecture, each implementation has its own set of dilemmas and technical challenges.
Simform houses highly experienced data and BI experts that can help you put together a data pipeline to bridge the gap between your data and the business value it can unlock. So if you’re struggling to evaluate which tools and architectural options are right for your business, contact our data engineering experts today!
