Here’s an interesting (and most familiar) analogy for stream processing: it is human. Most activities we perform involve real-time stream processing. For instance, when crossing a street, we rely on absorbing the most up-to-date data, understanding it as it comes, and reacting to it in real-time. How would it go if it we relied on historical data?
Likewise, reliable and fast access to data-driven insights is crucial for businesses seeking to improve their competitive edge. Thus, they need to process vast amounts of incoming data in real-time to stay ahead of the curve. And stream processing makes this possible.
It is a technology that processes continuous data streams in real-time to deliver analytical insights. This blog discusses all you need to know about stream processing, how it works, its common use cases, examples, and popular frameworks.
What is stream processing?
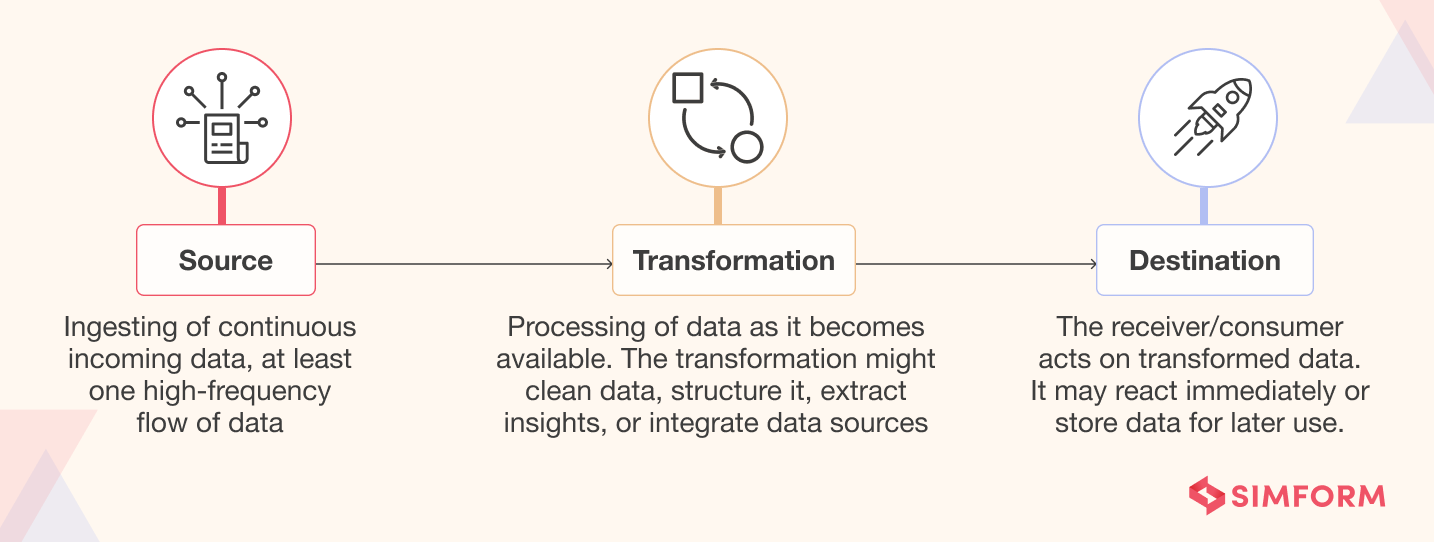
Stream processing (or real-time data processing) is a method that processes data on the fly. It encompasses:
- Ingesting a continuous flow of incoming data,
- Processing/transforming it as it arrives, and
- Delivering results to a destination for immediate action and/or storing them for later use.
The continuously generated data is referred to as streaming data. It is typically in high volumes, at high velocities, and unbounded (a dataset that is theoretically infinite in size).
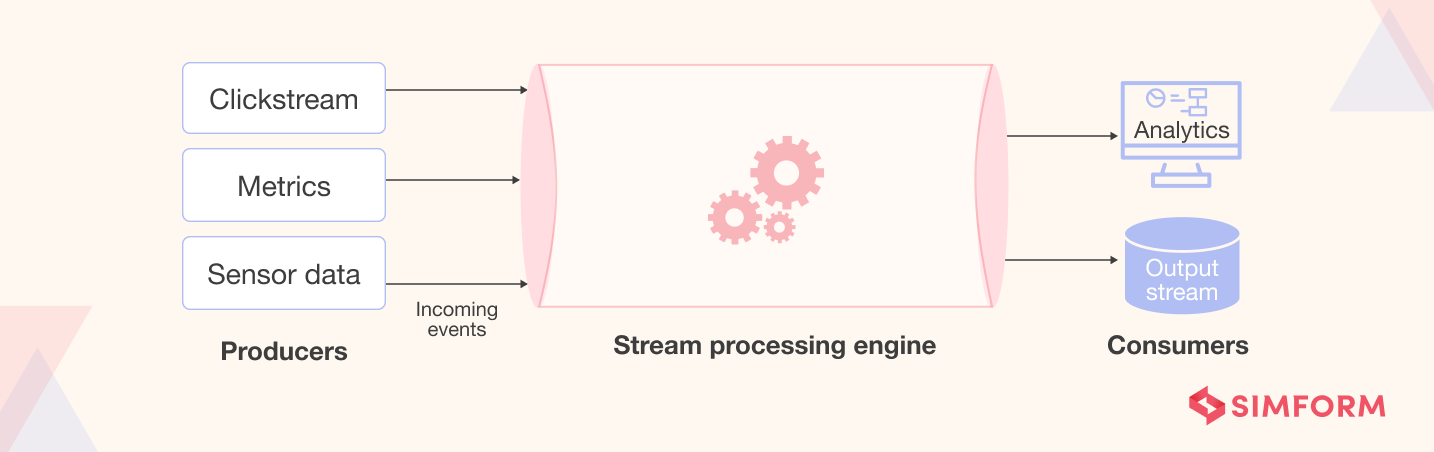
The stream processing system collects data streams from various sources, such as clickstreams, social media networks, in-game player activities, e-commerce purchases, sensor data from IoT devices, and more. Moreover, it can arrive in different formats (unstructured or semi-structured formats, such as JSON).
The goal is to capture the unbounded stream of input data in real-time and process it with minimal latency (in milliseconds or seconds) to enable real-time consumption (by generating reports in real-time, near-real-time, or with automated responses).
The processed data is often written to analytical data stores where it is optimized for visualization and analytics. It can also be ingested directly into the analytics and reporting layer for analysis, BI (business intelligence), and real-time dashboard visualization.
Stream processing vs. batch processing
While batch processing is a traditional approach, stream processing is relatively new.
Batch processing collects data, stores it, and then feeds it into an analytics system, mainly focusing on processing historical data. For example, end-of-cycle processing such as settling overnight trades, generating end-of-day or month reports, or payrolls.
In contrast, stream processing has become a must-have for modern apps. It collects, analyzes, and delivers data as it moves. It can also entail a diverse set of tasks performed in parallel, in series, or both, for real-time analysis.
For example, a soft drinks company wants to boost brand interest after it aired a commercial during a sporting event. It will feed social media data directly into an analytics system to assess audience response and decide how to boost their brand messaging in real time. Here, processing and querying are done continuously.
To read more, check out this blog on how to build a real-time streaming data pipeline to analyze social media data.
However, data streams can also be a source for historical data collection. In that case, an additional warehouse can store data to be formatted and further used for analysis or BI. Below is a summary of stream processing vs. batch processing.
| Batch processing | Stream processing | |
| Frequency | Infrequent jobs that produce results once the job has finished running | Continuously running jobs that produce constant results |
| Performance | High latency (minutes to hours) | Low latency (milliseconds to seconds) |
| Data sources | Databases, APIs, static files | Message queues, event streams, clickstreams |
| Analysis type | Complex analysis, ideal for very large data sets and projects that involve deeper data analysis | Relatively simpler analysis including aggregation, filtering, enrichment, event detection, etc. |
| Processing | Collects data over time and sends it for processing once collected | Continuously collects data and processes it fast, piece by piece |
| Use case | Generally meant for large data quantities that are not time sensitive | Typically meant for data needed immediately |
How stream processing works
Before we dive deep into how stream processing works, let’s look at some common stream processing terms which include – events, publisher/subscriber (commonly referred to as pub/sub), and source/sink.
Events refer to any number of things in a system, such as user activities on a website, application metrics, or financial transactions.
In a typical stream processing application, events and data are generated by one or multiple publishers/sources (also called producers). The data is then enhanced, tested against fraud detection algorithms, and transformed, if necessary. The system then sends the data to a subscriber/sink (also called consumers), which may include Apache Kafka and big data repositories like Hadoop.
As an example, let’s consider SenTMap, a sentiment-based analytics engine Simform built as an example of stream processing. SenTMap is a scalable real-time analytics application that analyzes news data to determine the trends in sentiments and stock price movements.
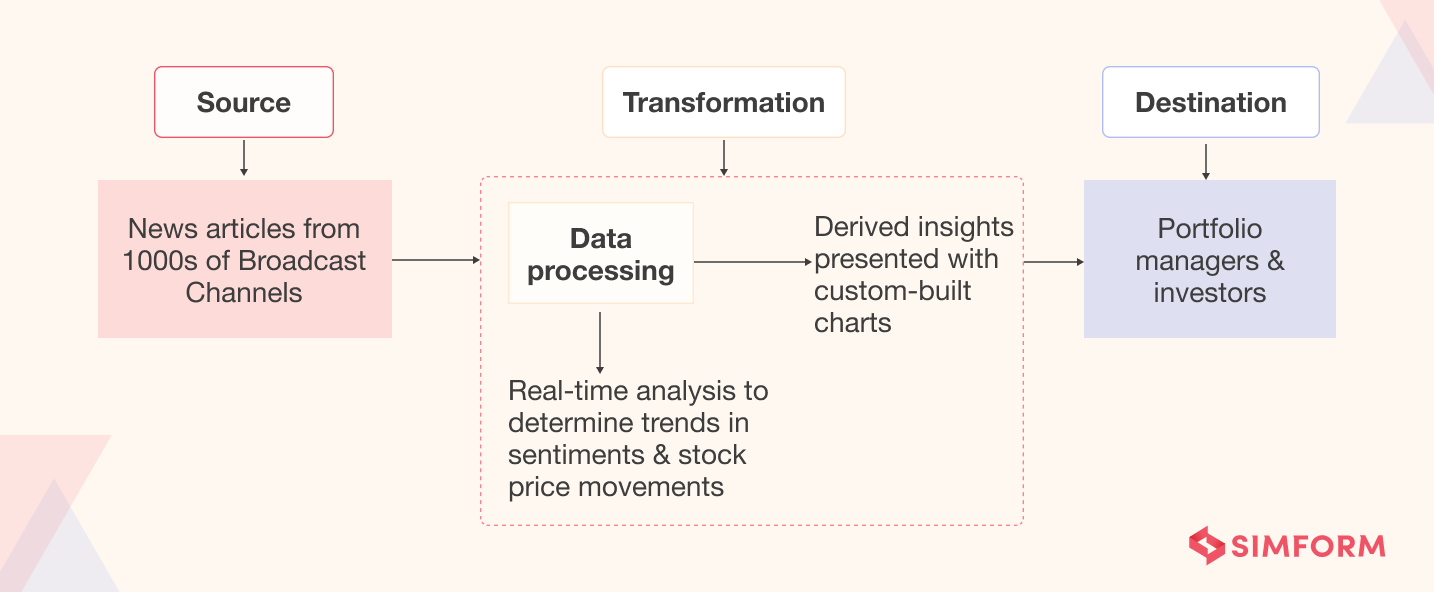
The process begins when the system ingests data coming from thousands of news broadcast channels constantly. We used Azure Event Hubs to ingest this firehose of data with low latency and configurable time retention, ensuring a reliable and scalable data pipeline. After operating on the data, it presents meaningful insights to portfolio managers and investors to help them understand the bearish or bullish trend of the market in real-time.
The data is not stored anywhere as it is processed in real-time. To accommodate this, we built a backend system with high processing power, ensuring no article or news leaked as it can lead to wrong market sentiment. Moreover, SenTMap required custom-built charts to display processed data (sentiments) in a way that required minimum visual processing.
Check out the full case study on SenTMap to know more
Note: It is essential to note that stream processing signifies the notion of real-time analytics but it is relative. Real-time could mean billionths of a second for a physics researcher, millionths of a second for an algorithmic stock trading app, or five minutes for a weather analytics app.
The above notion points to how a stream processing engine packages bunches of data for different applications. It organizes data events arriving in short batches to present them to other applications as a continuous feed. It also simplifies the logic for developers who combine and recombine data from different sources and time scales.
Furthermore, stream processing can be stateless or stateful.
Stateless stream processing: Here, the processing of current data/events is independent of previous ones. The data is evaluated as it arrives without consideration for state or previous knowledge.
Stateful stream processing: It is concerned with the overall state of data. Meaning, the past and current events share a state. The context of preceding events helps shape the processing of current events.
For example, stateless processing applies if you need a real-time feed of the temperature of an industrial machine without concerning how it changes. But a stateful stream processing system is ideal if you want to forecast future temperature based on how it has changed over time.
Components of a stream processing architecture
Architecturally, building a streaming system can be complex. It is a framework of software components, and you can architect a common solution to handle most, if not all proposed use cases.
So what are the components that are building blocks of a streaming architecture? Below, we will discuss them and review where and how each component type fits in the architecture.
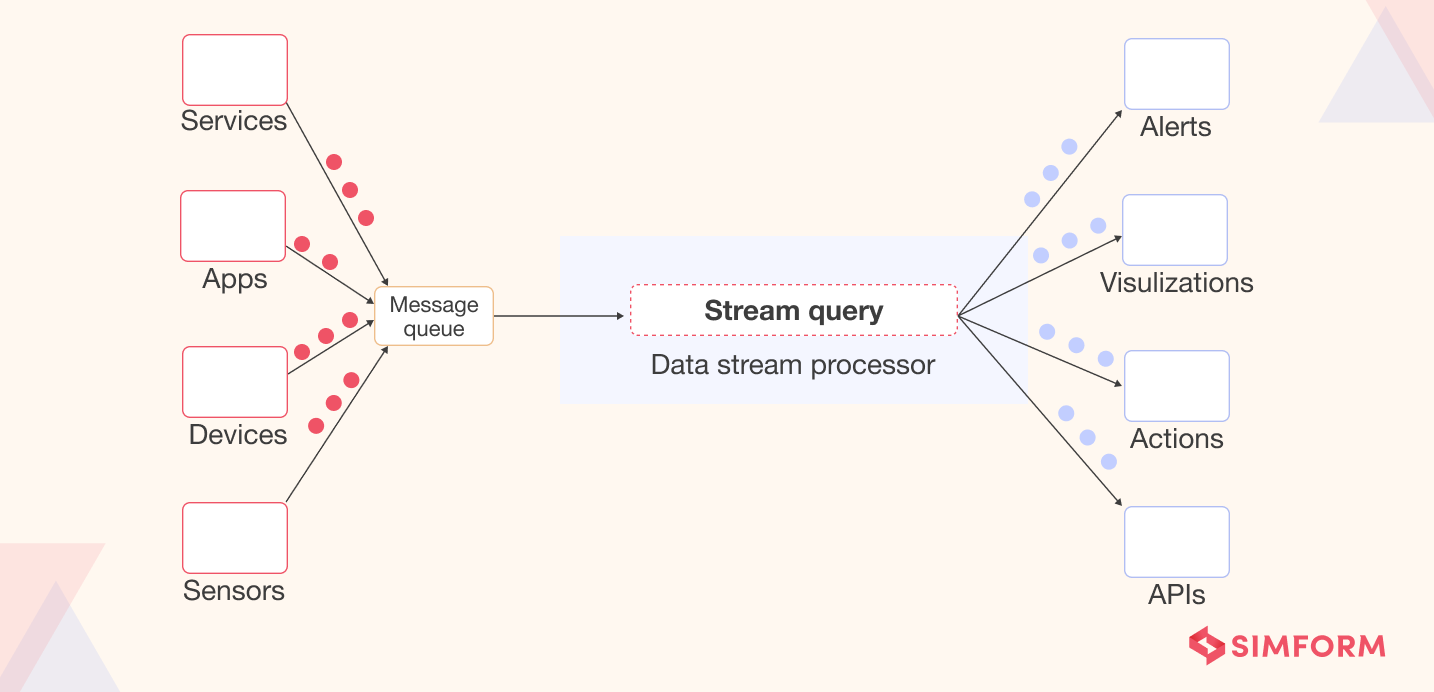
Stream processor or message broker, to collect data and redistribute it
A stream processor or message broker uses an API to fetch data from producers. The processor converts the data into a standard messaging format and streams the output continuously to consumers.

The first generation of message brokers, such as Apache ActiveMQ and RabbitMQ, relied on the MOM (Message Oriented Middleware) paradigm. Later, hyper-performant messaging platforms (called stream processors) emerged and are more suitable for a streaming paradigm. Some popular stream processing tools are Apache Kafka, Amazon Kinesis Data Streams, Azure Event Hubs, and Google Cloud PubSub.
Stream processing and data transformation tools (ETL, ELT, etc.), to ready data for querying
Once the message broker deposits data, stream processing tools aggregate, transform and structure the data, ensuring it is ready for analysis. The transformations can include- normalization, mapping relevant fields to columns, compacting, enrichment (combining data points with other data sources to create more context and meaning), partitioning, and more. The result may be an action, an API call, a visualization, an alert, or a new data stream in some cases.
Analytics and query engines, to extract the business value
Once the data is prepared for consumption, it can be analyzed to unlock its value. There are various approaches to streaming data analytics, depending on the use case. Here are some examples of tools and techniques: query engines (Athena, Redshift), text search engines (Elasticsearch), etc. Azure Stream Analytics can also be used for real-time processing, querying, and generating alerts or dashboards from streaming data using an SQL-like interface.
Data storage
It can include cost-effective storage (file storage and object storage) for high volumes and multi-structured nature of streaming data. Moreover, it can also include data stores to hold output data generated after processing for further use later.
For instance, if you are storing your streaming data on Snowflake, it lets you perform real-time analytics with dashboards and BI tools. These data stores can be a flexible integration point as tools outside the streaming ecosystem can access the data. Moreover, with scalable and cost-effective options like Azure Blob Storage, many organizations now store their streaming event data for long-term for analytics and downstream processing within the Azure ecosystem.
Benefits of stream processing
Today, finding a company without an app or website is difficult. And the growth in such digital assets increases the need for complex and real-time analytics. Moreover, the explosive growth in IoT, SaaS, and machine learning has encouraged companies to adopt streaming analytics with modern data infrastructure.
So here’s how stream processing can provide several benefits that other data management techniques cannot.
Ability to deal with never-ending data streams
Some data is naturally structured as a never-ending stream of events, which stream processing handles effectively. For example, it naturally fits with time series data, and most continuous data series are time series data such as traffic sensors, transaction logs, health sensors, activity logs, etc. Plus, almost all IoT data today is time series data. Hence, it is ideal to use stream processing to unlock insights from these data.
Real-time or near real-time processing
Real-time analysis can also be done with high-performance database systems. But it is more efficient and fluent with stream processing models as they collect massive amounts of data arriving from diverse sources at high velocity and analyze it reliably and with minimal latency.
Handles the latest data sources
With the rise in IoT and SaaS apps, a lot of streaming data is generated from various sources. And it will grow further with the increasing use of IoT. Thus, the inherent architecture of stream processing seems to be the ideal solution for these sources.
Easy data scalability
The volume of data today is increasing exponentially, making it challenging to store it. A batch processing system requires you to provide more resources or modify the data architecture. But stream processing lets you handle the growing data volumes “firehose style”. It deals with vast amounts of data per second as soon as it arrives and does not let it build up. So, there’s no need for infrastructure changes or investing in costly storage.
Other benefits of stream processing include:
- Enables the development of adaptive and responsive applications
- Helps enterprises improve real-time business analytics
- Accelerates decision-making
- Improves decision-making with increased context
- Improves the user experience
Stream processing use cases
Did you know financial companies first adopted stream processing to process new information in real-time, such as trades or prices? But today, it is crucial in all modern, data-driven organizations. And it is applied for a wide variety of use cases across various industries, as discussed below.
IoT and sensor data
Sensor-powered IoT devices send and collect large amounts of data quickly, which is valuable to organizations. For instance, they can measure various data, such as temperature, humidity, air quality, air pressure, etc.
Once the data is collected, it can be transmitted to servers for processing. With millions of records generated every second, you might also need to perform actions on the data, such as filtering, discarding irrelevant data, etc. When data is collected from multiple sources, it may require actions like aggregation and normalization.
For example, hundreds of industrial fan sensors constantly feed their rotational speed and temperature into a logging database. Stream processing can quickly capture and evaluate this data (before it is stored in the database) to give the management an immediate heads-up in case a fan is failing.
Cybersecurity
Using streaming data to detect anomalies can allow you to identify security issues in real-time to isolate or neutralize them. For example, you can identify a DDoS attack if you spot a suspicious amount of traffic from a single IP address.
Personalization for marketing and online advertising
Stream processing can allow you to track and evaluate user behavior, clicks, reactions to content, and interests in real-time to promote personalized, sponsored ads for each user timely. It also helps make fast, targeted decisions about what to serve your customers or visitors and drive conversions and leads.
Log analysis
It is a process that engineering and IT teams use to identify bugs by reviewing computer-generated records called logs. Stream processing improves log analysis by collecting raw system logs, structuring them, and converting them into a standardized format at lightning speed. Thus, it is easier for teams to detect bugs and fix them faster.
Fraud detection
Stream processing can quickly go through time-series data to analyze user behavior and identify suspicious patterns. For example, a retailer can identify credit card fraud during points of sale with real-time streams. The processing system can correlate customer interactions with different transactions and channels, and review them instantly if the system discovers an unusual or inconsistent transaction.
Here are some more use cases for stream processing:
- Tracking behavior in digital products to evaluate UX changes, understand feature use, increase usage, and reduce abandonment
- Cloud database replication using CDC (change data capture) to maintain a synced copy of a transactional database in the cloud and enable advanced analytics
- Collecting and immediately reacting to customer interactions and orders in mobile apps in retail, hotel, travel industry, etc.
- Monitoring patients in hospital care and predicting changes in condition to ensure timely treatment in emergencies
- Algorithmic trading and stock market surveillance
- Processing payments and financial transactions in real-time, such as in stock exchanges, banks, and insurance companies
- Tracking and monitoring cars, trucks, fleets, and shipments in real-time in logistics and the automotive industries
- Predictive analytics and predictive maintenance
Now that we have discussed how it can be applied to business use, let’s examine real-world examples of how companies utilize stream processing to benefit from real-time analytics.
Real-world streaming processing examples
Tryg
Simform built a telematics-based solution for the second-largest non-life insurance company in Scandinavia. It is a real-time fleet management and tracking solution for fleet operators and drivers to get insights into vehicle and driving behaviors. Insurers also get deeper insights into the claims and vehicle health, allowing them to be proactive.
The solution tracks different vehicle parameters in real-time and analyzes this data to find emerging health issues. It allows fleet managers to plan for any maintenance in advance. The solution runs a Stream Analytics job to push messages to an Azure message queue to provide hot or real-time analytics.
Check out the full case study on Tryg-i-bil to know more
Uber
Uber app deals with two real-time instances. Tracking the location of drivers and clients and the continuous data flow coming from Uber users making payments directly through the app. Financial transactions require monitoring, and there is also a high risk of fraud.
Uber’s Chaperone, an auditing data system, was built to address these two issues. It uses Apache Kafka as a messaging service and performs high-speed auditing, detects duplicate or data loss, and more. Performing audits between multiple data centers has allowed Uber to decrease error rates, improve fraud detection, and avoid data loss.
Popular stream processing frameworks
A stream processing framework is an end-to-end system that provides a dataflow pipeline to accept streaming inputs for processing and generating useful, real-time analytics. These frameworks simplify the development of a stream processing system as developers can include functions from existing libraries without dealing with lower-level mechanics and write a system from scratch.
Tools like Apache Storm and Samza have been around for years, but are now joined by newcomers like Apache Flink and managed services like Azure Stream Analytics. Let’s look at some of the popular stream processing frameworks today.
Azure Stream Analytics
It offers a powerful, fully managed service for real-time data processing. It lets organizations ingest and analyze large volumes of streaming data from sources such as IoT devices, applications, and infrastructure logs. This makes it particularly effective in industries like manufacturing, transportation, and logistics, where timely insights into system performance and operations are critical.
With built-in integration across the Azure ecosystem, it allows teams to trigger alerts, automate responses, or feed processed data into dashboards and storage systems. Its scalable architecture ensures consistent performance under fluctuating workloads, while its SQL-based query language simplifies development for analysts and engineers alike.
Apache Kafka
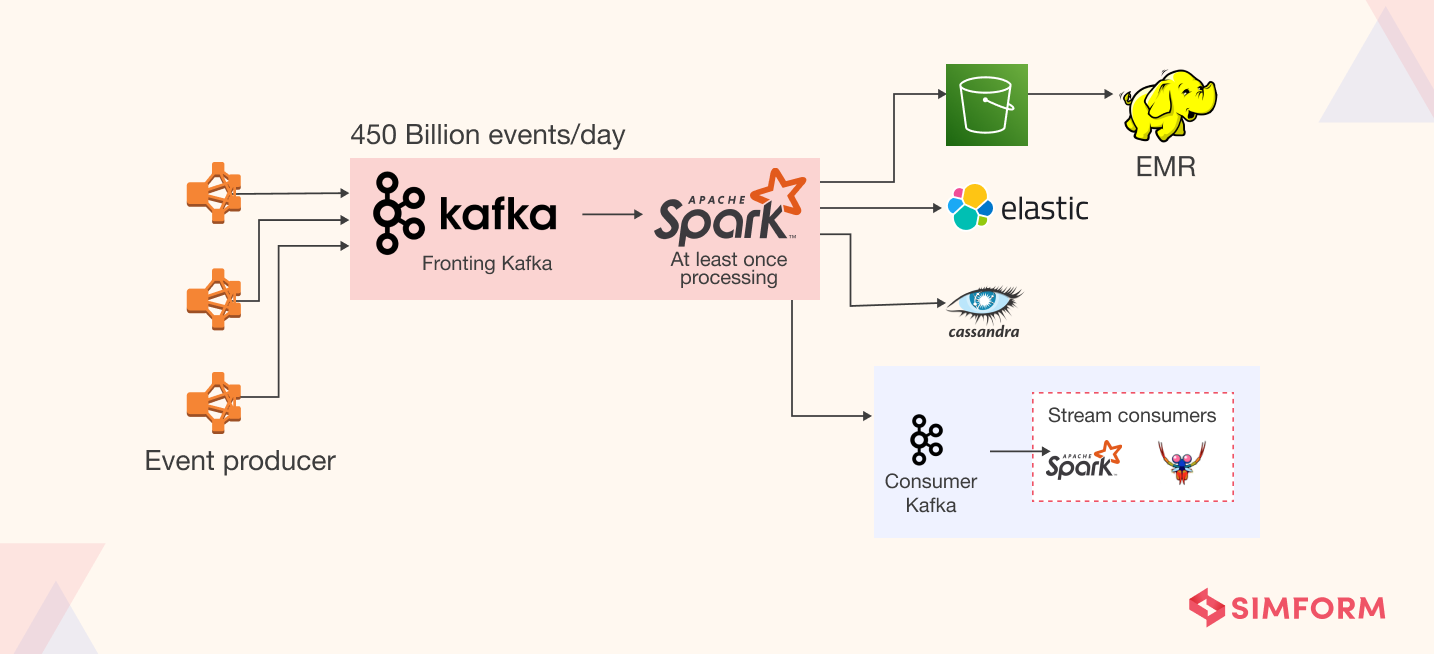
It is an open-source message queuing and stream processing platform that can scale to handle millions of messages per second from multiple producers and route them to multiple consumers. It integrates applications and data streams via an API. It has been popularized by giants such as Netflix and Uber because of its ability to run concurrent processing and quickly move large amounts of data. Below is an example of Netflix’s big data ingestion platform using Kafka.
Apache Spark
It is an open-source, distributed, general-purpose cluster computing framework. Its declarative engine (calculates the Directed Acyclic Graph (DAG) as it ingests data) is used by developers to chain stream processing functions. They can specify the DAG explicitly in their code, and the Spark engine will optimize it on the fly. Moreover, its in-memory data processing engine executes analytics, ML, ETL, and graph processing on data in motion or at rest. And it offers high-level APIs for specific programming languages such as Python, Java, Scala, R, and SQL.
Build streaming data pipelines with Simform
To sum up, how you ultimately architect your stream processing system depends on technical factors (such as engineering culture, the experience of teams, etc.) and business factors (such as use case, budget, and the metrics) you want to achieve. But the less you worry about the how of your stream processing, the more you can focus on using the results for the growth and innovation of your business.
Simform is dedicated to building robust data pipelines that leverage the power of tech and align with your business objectives, as we saw in the case of SenTMap and Tryg. If you are looking for teams with the expertise to solve your data engineering problems, reach out to us today!
