The global data engineering services and big data market is projected to reach $87.37 billion by 2025 (from $39.50 billion in 2020) at a CAGR of 17.6% over this period. And as we continue to see more investment allocated to building data teams and infrastructure, data engineering tools have also evolved and increased in number.
Data engineering is a specialty that relies heavily on tools as they simplify and automate the process of data pipelines. Thus, it is essential to pick the right tools to enable fast and reliable business decision-making. This article provides a curated list of 25+ data engineering tools along with their key features for each layer of a data engineering infrastructure.
List of top data engineering tools
As shown below, a modern data analytics platform has six logical layers/stages, and composing each layer requires specialized tools.
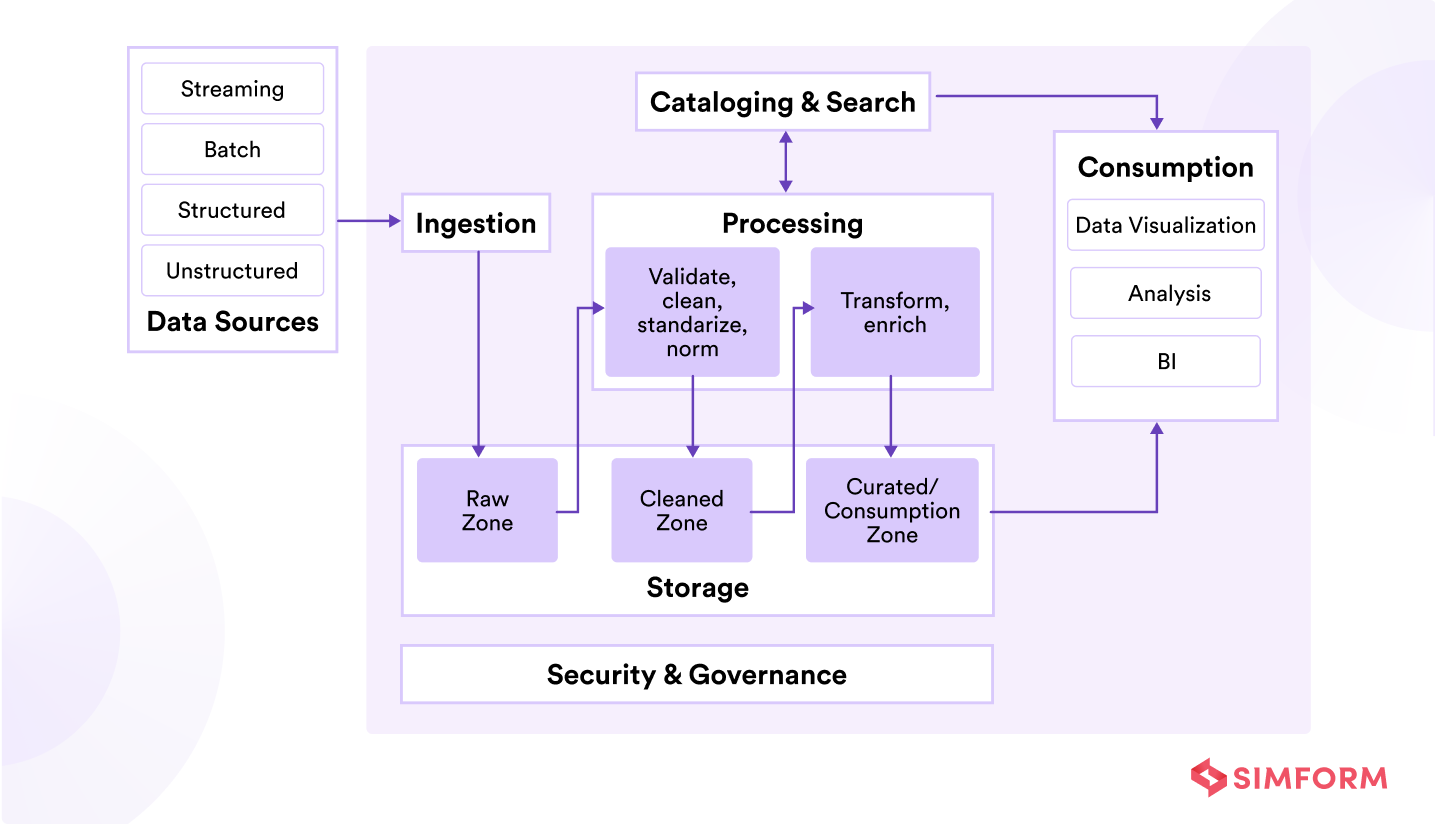 Below, we have discussed popular tools for each stage in a data engineering pipeline and popular programming languages.
Below, we have discussed popular tools for each stage in a data engineering pipeline and popular programming languages.
Data ingestion tools
Data ingestion tools are responsible for extracting data from a variety of sources and facilitating its transfer into the processing or storage layer. It can include various data types (batch and streaming) and formats (structured, semi-structured, and unstructured data). Moreover, data may be delivered to diverse targets such as data lakes, data warehouses, a stream processing engine, etc.
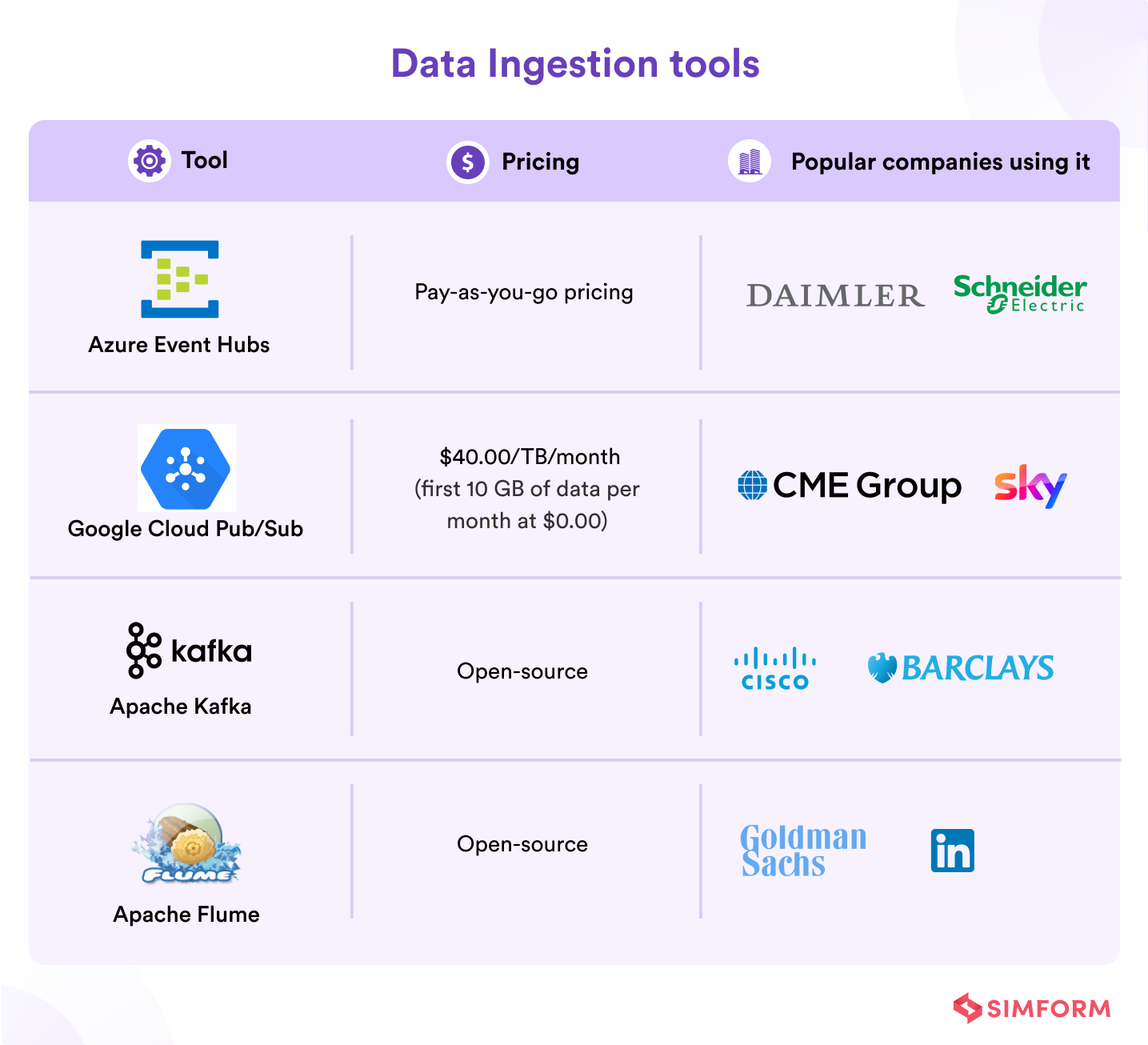 1. Azure Event Hubs
1. Azure Event Hubs
Azure Event Hubs is an event ingestion and processing service that collects and processes millions of events/data per second with low latency and high reliability. It enables real-time analytics, supporting various scenarios such as anomaly detection, application logging, transaction processing, etc. Moreover, data sent to event hubs can be stored and transformed using any batching/storage adapters or real-time analytics provider.
Key features:
- Fully managed Platform-as-a-Service (PaaS) with little configuration or management overhead
- Elastic scaling
- Seamless integration with data and analytics services inside and outside of Azure
- Support for concurrent real-time and batch processing
2. Google Cloud Pub/Sub
Pub/Sub is a fully managed real-time messaging and ingestion service by Google Cloud. It allows you to send and receive messages between independent applications and services. Thus, it can be used for streaming analytics, event-driven systems, and data integration pipelines to ingest and distribute data.
Key features:
- Allows services to communicate asynchronously, with very low latencies (on the order of 100 milliseconds) and high availability
- No-ops scalable messaging/queue system
- Integrates with multiple Google Cloud services
- Provides some third-party and OSS integrations
- Offers fine-grained access controls, end-to-end encryption, and HIPAA compliance
3. Apache Kafka
Apache Kafka is an open-source, distributed stream-processing platform that ingests, processes, stores, and analyzes data at scale. It is popular for its high performance, low latency, and fault tolerance. It is employed by thousands of companies to support multiple use cases, including building performant data pipelines, streaming analytics, data integration across countless sources, and enabling operational metrics.
Key features:
- Elastic scaling
- Offers secure permanent storage
- Built-in stream processing
- Can integrate with hundreds of event producers(sources) and consumers
4. Apache Flume
Apache Flume is an open-source, distributed service for efficiently collecting, aggregating, and transporting large amounts of streaming event or log data. It can gather data from multiple systems and land into a centralized data store in a distributed fashion (like HDFS). Flume’s use is not limited to log data aggregation. Its customizable data sources can efficiently move unstructured event data, such as social media-generated data, network traffic data, and more.
Key features:
- Reliable and highly available
- Simple, flexible architecture based on streaming data flows
- Robust and fault-tolerant with many failover and recovery and tunable reliability mechanisms
Simform built a telematics-based solution for Tryg, the second-largest non-life insurance company in Scandinavia. The solution, Tryg-i-bil, tracks real-time vehicle parameters and analyzes this data to identify emerging health issues. To provide hot or real-time analytics, we used a Stream Analytics job to push messages to an Azure message queue (with Azure Event Hubs).
Explore how we transformed Tryg’s data infrastructure with Azure
Data processing tools
Data processing tools transform data into a consumable state through data validation, cleanup, normalization, aggregation, enrichment, and more. These tools also advance the consumption readiness of datasets along the landing, raw, and curated zones.
The processing layer comprises purpose-built data processing components to match the right dataset characteristic with the processing task at hand.

1. Azure Stream Analytics
Azure Stream Analytics is a fully managed stream processing service that processes and analyzes millions of events every second with ultra-low latencies. It can derive patterns and relationships from various sources such as sensors, devices, applications, clickstreams, social media, etc. This makes it suitable for numerous scenarios, such as anomaly detection, geospatial analytics, clickstream analytics, predictive maintenance, and more.
Key features:
- Allows real-time processing with low latency and high throughput
- Rapid and elastic scaling
- Compatibility with cloud and intelligent edge environments
- Integrates with Azure services for an end-to-end solution
- Supports reliability, security, and compliance requirements
2. Google Cloud Dataflow
Dataflow is Google Cloud’s fully managed data processing service that can unify both stream and batch data processing in an efficient and scalable way with low latencies. It is ideal for use cases including stream analytics, sensor and log data processing, etc. It also has real-time AI capabilities, enabling intelligent solutions for predictive analytics, real-time personalization, anomaly detection, and other advanced analytics use cases.
Key features:
- Automates infrastructure provisioning and auto-scaling of resources as data grows
- Smart diagnostics and automatic recommendations to identify and tune performance and availability issues
- Inline monitoring for troubleshooting
- Security with customer-managed encryption keys, VPC service controls, and private IPs
3. Apache Flink
Apache Flink is a distributed processing engine that excels at stateful computations over bounded and unbounded datasets at any scale. It can handle massive data streams and deliver high throughput with low latency. With its extensive feature set, it can be an excellent choice for developing and running various applications such as stream and batch analytics, data pipelines, ETL, and more.
Key features:
- Unifies stream processing and batch data processing
- Configured for high availability with no single point of failure
- Easy-to-use and expressive APIs and libraries.
- Custom memory management
4. Apache Spark
Apache Spark is a distributed computing engine for large-scale data processing and analytics. It is simple but widely popular as one of the fastest stream-processing and data-management frameworks. It allows you to execute data engineering, data science, and ML at scale on single-node machines/clusters. It also enables you to perform multiple operations on the same data, such as data transformation and aggregation.
Key features:
- Unifies batch processing and real-time streaming using your preferred language (Scala, Java, Python, R, or SQL)
- Support for various data sources
- In-memory computation
5. Apache Storm
Apache Storm is a distributed real-time computing engine that allows you to easily and reliably process unbounded data streams. Moreover, its inherent parallelism enables it to process very high throughputs of messages/data with very low latency. It can be ideal for many use cases, such as real-time analytics, online ML, continuous computation, ETL, etc.
Key features:
- Programming language agnostic
- Horizontal scalability
- Guaranteed at-least-once processing
- Integrates with the database and queueing technologies you already use
Data storage tools
Data storage tools provide durable, scalable, and secure services to store vast amounts of data. The storage supports unstructured data and various other structures and formats. Moreover, components from other layers may require easy integration with the storage layer for better efficiency.
 1. BigQuery
1. BigQuery
BigQuery is a fully managed and serverless data warehouse and analytics platform by Google Cloud. It consolidates siloed data into one location so you can perform data analysis and get insights from all of your business data. Thus, it can help you make decisions in real-time, streamline business reporting, predict opportunities, data exploration, and more.
Key features:
- Scales with your data (petabyte scale)
- Supports all data types, allows multi-cloud analytics, and has built-in ML and BI– all within a unified platform.
- Built-in capabilities that ingest streaming data and make it immediately available to query
- Integration with security, governance, and privacy services from Google Cloud
2. Azure Data Lake Storage
Azure Data Lake Storage is a secure and massively scalable data lake designed for high-performance and enterprise big data analytics workloads. It is optimized for performance, as you don’t need to copy or transform data as a prerequisite for analysis. Moreover, it offers features to lower costs as it is built on top of the low-cost Azure Blob Storage.
Key features:
- Eliminates data silos with a single storage platform
- Optimized costs with tiered storage and independent scaling of storage and compute
- High availability/disaster recovery capabilities.
- Multiple mechanisms and capabilities for robust security
- Integrates with Azure services for data ingestion, processing, and visualization
3. Apache Hadoop
Apache Hadoop software library is an open-source framework that provides a way to store and process big data across a distributed computing environment (clusters of computers) using various data processing tools and techniques. Its core components include Hadoop Distributed File System (HDFS) for data storage and the MapReduce programming model for data processing. Hadoop is widely used for big data applications due to its scalability, fault tolerance, and flexibility.
Key features:
- Parallel processing
- Data locality
- Supports various formats including structured (MySql Data), semi-Structured (XML, JSON), and unstructured (Images and Videos) efficiently
- Detects and handles failures at the application layer, delivering highly-availability
4. Cassandra
Apache Cassandra is a NoSQL database that is fast and can manage massive amounts of data. It includes support for replication across multiple data centers, providing fault tolerance and lower latency. Moreover, both read and write throughput increase linearly as new machines are added. Thus, there is no downtime and interrupting applications, making it ideal for mission-critical data.
Key features:
- Distributed, multi-master with no single points of failure
- Elastic scalability
- Flexible schema
- Security and observability features
5. Apache Hive
Apache Hive is a data warehouse that enables analytics at a massive scale, data summarization, and ad hoc querying. One of its key features is Hive Metastore(HMS), a central metadata repository that can be easily analyzed to make informed, data-driven decisions. It has become a vital component of many data lake architectures that utilize diverse open-source software, such as Apache Spark, Kafka, and Presto.
Key features:
- Fault-tolerant
- Facilitates reading, writing, and managing of petabytes of data in distributed storage using SQL
- Built on top of Apache Hadoop
- Supports other storage such as Google Cloud Storage
6. Snowflake
Snowflake is a cloud-based data warehousing platform. It allows you to store, manage, and analyze large amounts of data in a scalable, efficient way. It separates compute and storage, enabling automatic performance optimization, data sharing, concurrency, etc., making it suitable for a wide range of workloads. Thus, it helps streamline data engineering activities like ingesting, transforming, and delivering data for deeper insights.
Key features:
- Managed infrastructure, automatic clustering, and on-the-fly scalability
- Supports structured and semi-structured data
- Easy and secure data access and sharing
- Integrates with various third-party tools and other languages
- Available on multiple cloud providers, including AWS, Azure, and GCP
We built a scalable platform for an Amazon marketplace aggregator to consolidate data and streamline reporting. Using Snowflake, Python, Looker, and other tools, it supports operational efficiency across analytics and inventory systems. Check out the full case study to learn how we re-engineered the data platform.
Data cataloging & search tools
Cataloging and search tools store business and technical metadata about datasets hosted in the storage layer. They provide the ability to track schema and the granular partitioning of dataset information in the data lakes. It is crucial to help track versions of changes to the metadata and enable the discovery of data in the data lake with search capabilities.
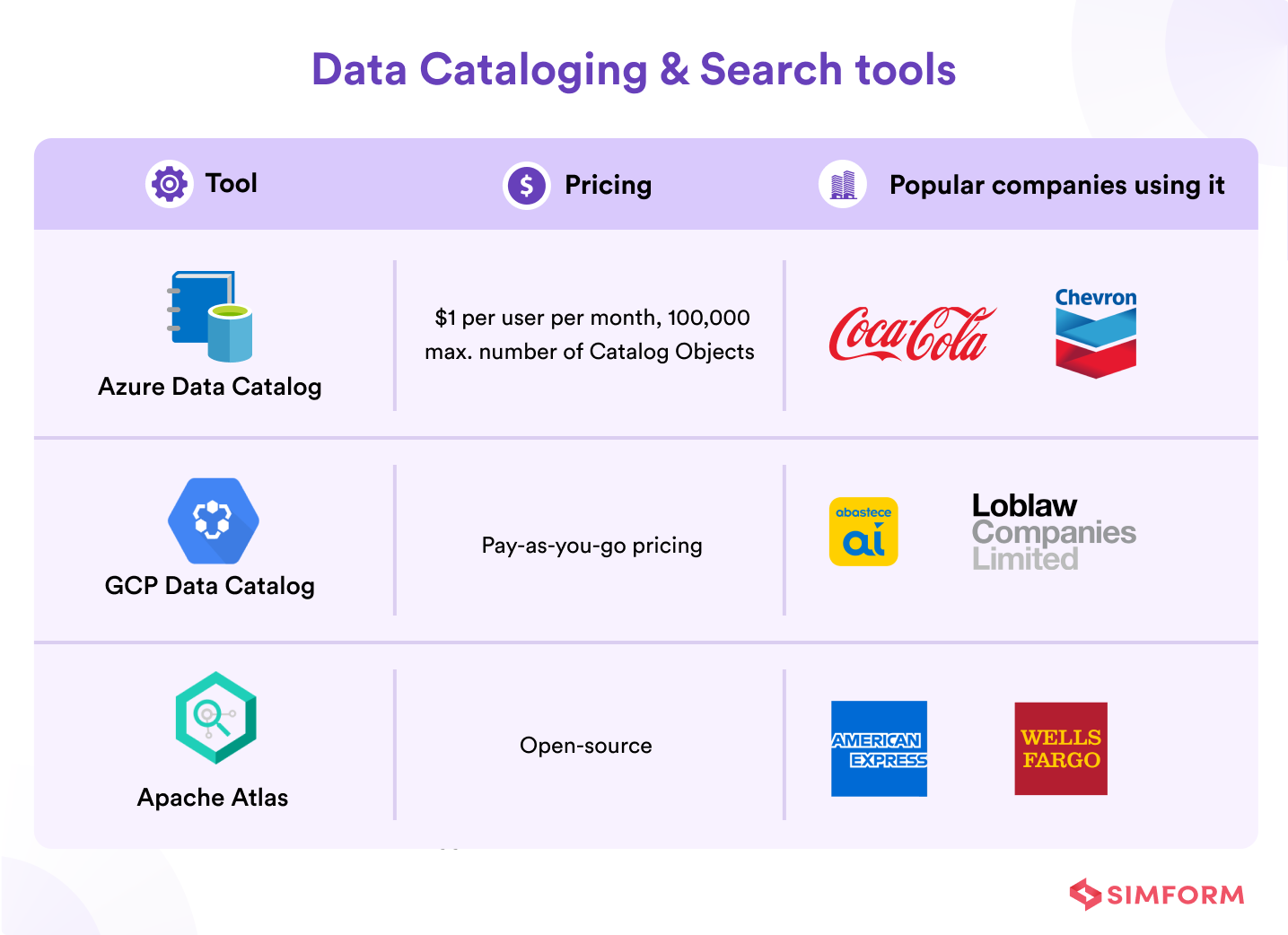 1. Azure Data Catalog
1. Azure Data Catalog
Azure Data Catalog is an enterprise-wide metadata catalog by Microsoft Azure that makes data asset discovery easy for users of all levels, from analysts to data scientists to data developers. It is a fully managed service that allows users to register, enrich, discover, understand, and consume data and provides a centralized platform for storing and managing metadata about data assets.
Key features:
- Makes data asset discovery straightforward and democratizes it
- Helps you discover and work with data where you want in your choice of tool for an intuitive user experience
- Business glossary management and ability to automate tagging of data assets with glossary terms
2. GCP Data Catalog
Google Cloud’s Data Catalog is a fully managed and scalable metadata management service within Dataplex. It allows organizations to quickly discover, manage and understand all their data in Google Cloud. It improves data management to increase efficiency and productivity, supports data-driven decision-making, and accelerates the time to insights by enriching data.
Key features:
- Simple, easy-to-use search interface for data discovery
- Flexible and powerful cataloging system for capturing technical and business metadata
- Auto-tagging mechanism for sensitive data with DLP API integration
3. Apache Atlas
Apache Atlas is a scalable and extensible metadata management and governance framework. It enables organizations to effectively classify, manage, govern, and collaborate on their data assets on Hadoop clusters. Moreover, it allows integration with the whole enterprise data ecosystem.
Key features:
- Centralized platform for capturing and managing metadata about data assets
- Customization as per the specific needs of an organization
- Provides end-to-end lineage tracking for data assets
- Integration with other governance tools to automate data compliance and security
- Creates and maintains business ontologies
- Data masking
Data visualization, analysis, & BI tools
The consumption layer comprises data visualization, analysis, and BI tools that enable and support several analysis methods, including SQL, batch analytics, BI dashboards, reporting, and ML. These tools must also integrate with the storage, cataloging, and security layers. Moreover, they must be scalable and performant to gain insights from the vast data to enable swift decision-making for businesses.
 1. Azure Synapse Analytics
1. Azure Synapse Analytics
Azure Synapse Analytics is a fully managed, limitless analytics service that unifies data ingestion, preparation, transformation, and exploration across data warehouses and big data systems. It accelerates time to insight by enabling organizations to serve and analyze data in near real-time, making it ideal for powering immediate BI needs–all without the complexity of managing infrastructure.
Key features:
- Unified workspace
- Serverless & dedicated SQL pools
- Spark & Data Explorer engines
- Built-in ETL/ELT pipelines
- Lake-warehouse analytics
- Power BI & ML integration
- Advanced security & compliance
2. Power BI
Microsoft Power BI is an end-to-end BI platform that enables you to connect to and visualize any data to help uncover more powerful insights and translate them into impact. It also includes AI-powered features (such as natural language queries) that enable users to get fast, accurate answers to their business questions. Moreover, users can share reports and dashboards with others and work together on the same data.
Key features:
- Unified, scalable platform for self-service and enterprise BI
- Extensive data connectors
- Connects directly to hundreds of on-premises and cloud data sources
- Creates reports personalized with your brand and KPIs
3. Looker
Looker is a cloud-based BI and analytics platform that was acquired by Google Cloud. It is an SQL-based analytics tool that displays dimensions, aggregates, and calculations in a database while allowing users to create visualizations and graphs for each data set. It enables engineers to communicate and share information effectively with their colleagues and customers.
Key features:
- Scales effortlessly to meet data and query volumes
- Modern BI and analytics
- Dynamic dashboards for more in-depth analysis
- Works with your existing BI setup
- Secure governance across data
4. Tableau
Tableau is a leading BI and data visualization tool that allows users to create interactive and visually appealing dashboards and reports for analyzing and sharing data. With its drag-and-drop interface and robust data connectors, Tableau makes it easy to connect to various data sources, blend data, and create insightful visualizations. It helps anyone– from data scientists to business users– uncover insights faster with accessible ML, natural language, statistics, and smart data prep.
Key features:
- Intuitive interface
- Connects to all your data, no matter where it resides
- Powerful and advanced analytics
- Enterprise-grade security and governance models
5. Apache Superset
Apache Superset is a modern data visualization and exploration platform that allows users of all skill sets to visualize and explore their data, from simple line charts to highly detailed geospatial charts. It is also highly scalable, leveraging the power of your existing data infrastructure without adding yet another ingestion layer.
Key features:
- Simple no-code viz builder and state of art SQL IDE
- Modern architecture
- Rich visualizations and dashboards
- Integrates with a wide range of popular and modern databases and data sources
We built a centralized system for Mission Rabies to track vaccinations and streamline operations, integrating advanced analytics to support better decision-making. Using Power BI, we designed custom dashboards for smart data visualization– enabling more effective team coordination and project oversight. Our solution supported successful campaigns across multiple regions and helped optimize critical operations like data collection, remote program management, and monitoring. Read the full case study to see how data and dashboards drove impact on the ground.
Data security and governance tools
Data security and governance tools protect the data in the storage layer and the processing resources in other layers. They provide mechanisms for encryption, access control, network protection, usage monitoring, and auditing. Moreover, the security layer monitors the activities of all components in other layers and generates a detailed audit trail. Thus, the components of all other layers must integrate with the security and governance layer.
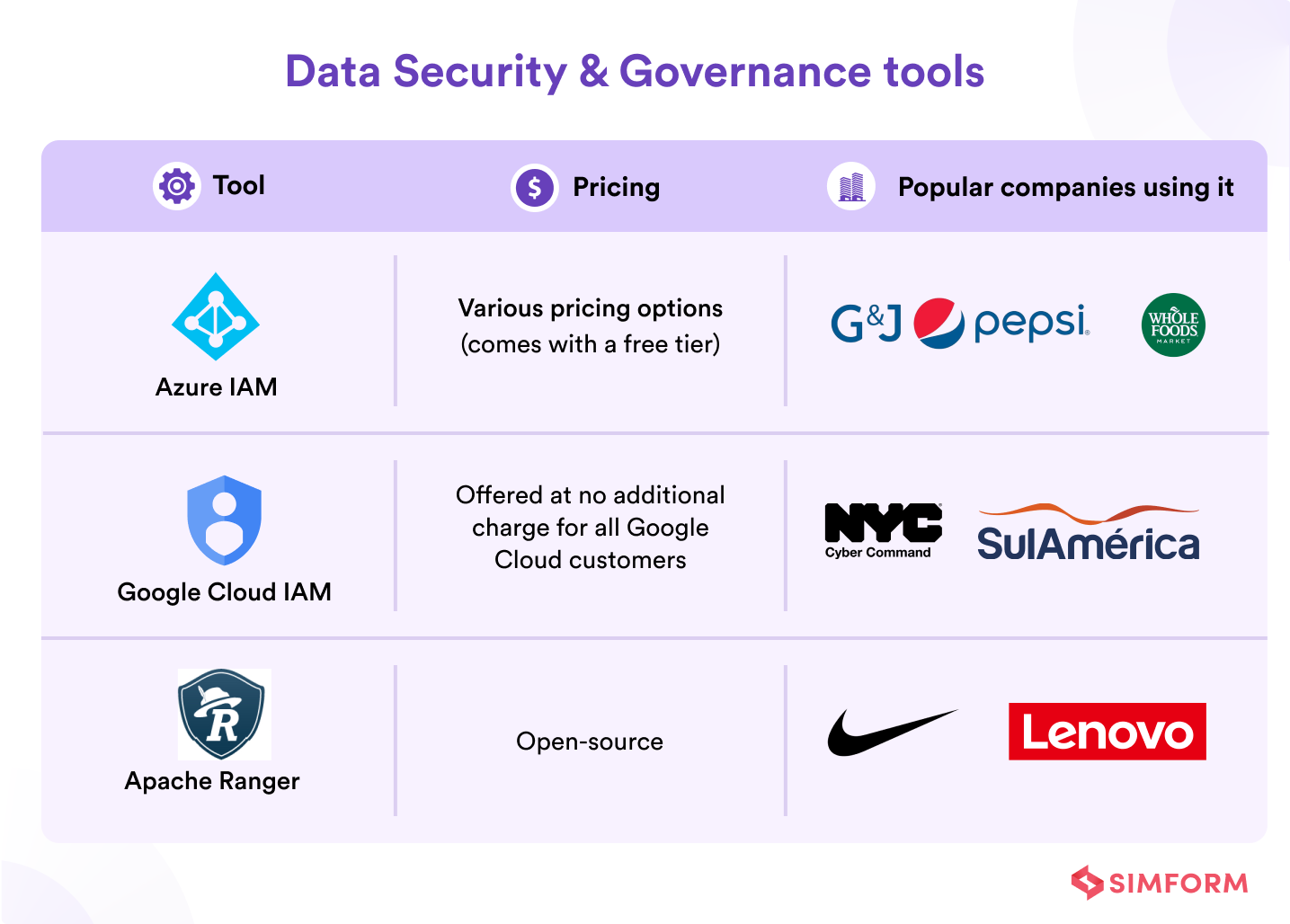 1. Azure Identity and Access Management (IAM)
1. Azure Identity and Access Management (IAM)
It includes a set of solutions to secure access to your Azure resources and protect your data at the front gate. For instance, if you want to provide identity and access management for cloud and hybrid environments, you use Azure Active Directory (Azure AD). Azure IAM solutions help defend against malicious login attempts and protect credentials with risk-based access controls, strong authentication options, and identity protection tools– all without disrupting productivity.
2. GCP Identity and Access Management (IAM)
Google Cloud’s IAM provides fine-grained access control and visibility for centrally managing cloud resources. It lets administrators authorize who can take action on specific resources, giving them full control and visibility to manage Google Cloud resources centrally. Moreover, it provides a unified view of security policy across the entire organization, with built-in auditing to ease compliance processes for enterprises with complex organizational structures and hundreds of workgroups.
3. Apache Ranger
Apache Ranger is a comprehensive security framework that enables managing and enforcing fine-grained access control policies across the Hadoop ecosystem. It also enables creating, managing, and enforcing security policies across other data platforms such as Apache Kafka, Apache Solr, and Apache Cassandra. Some key features of Apache Ranger include centralized policy management, support for role-based access control (RBAC) and attribute-based access control (ABAC), dynamic policy generation, and auditing of access requests and policy changes.
Popular programming languages for data engineering
1. Python
Python is a high-level object-oriented programming language commonly used to develop websites and software. But it has been gaining popularity as a language for data engineering due to its simplicity, versatility, and large number of libraries and frameworks available.
It provides extensive support for data processing, transformation, and visualization, making it an ideal choice for data engineering tasks. Additionally, Python can be used to build ETL (Extract, Transform, Load) pipelines and work with Big Data technologies such as Hadoop, Hive, and Impala. Popular data engineering frameworks that support Python include Apache Airflow, Apache Spark, and Pandas.
2. SQL
SQL (Structured Query Language), a core skill required for data engineering, is used to manage and manipulate data in relational databases. It is used to perform various tasks such as creating and modifying database schemas, querying and analyzing data, and transforming data using ETL (Extract, Transform, Load) pipelines. It is a powerful and widely used language that can handle large datasets and integrate with other data technologies.
3. Scala
Scala has also become a popular programming language for data engineering due to its functional programming capabilities and interoperability with Java. Its concise and expressive syntax enables developers to write complex data processing pipelines, handle large datasets, and scale processing across distributed systems. Popular data engineering frameworks that support Scala include Apache Spark and Apache Flink.
Wrapping up
Before selecting any data engineering tools, starting by understanding business needs and designing the data engineering architecture is ideal. As Joe Reis and Matt Housley coined the approach “architecture first and technology second” in Fundamentals of Data Engineering– Architecture design is a must before selecting any tool. Think of architecture as a strategic guide that answers the 3Ws (What, Why, and When) and tools as an implementer of that architecture.
Some other criteria you can use to evaluate the best tools are– is the tool’s UI clean and intuitive? How easy are the tools to learn and master? How long will the tool take to set up? What integrations it offers, and what extensibilities can it support? Lastly, tools should be selected in a way that adds value to your business or data solution while being cost-efficient and future-oriented. Contact our experts to get the best advice on data engineering tools and services tailored to your specific needs.
