Picture this: You are a mobile game developer monetizing game levels by tracking player progress. You collect the SDK event code to identify which game levels players struggle with and offer in-app purchases or other in-game actions to help players progress. Using a commodity-hardware MySQL server works fine when you have a small player base. But if the game spikes overnight from a creator campaign or an app-store feature, your event stream can outgrow a single write path in hours.
The above scenario will present many challenges for your data pipeline. However, such scenarios are common in today’s data landscape, with data volumes and velocities growing faster than ever before. Plus, the data formats and fields keep changing with new and evolving data sources.
Thus, designing a robust data pipeline that scales as data volume increases and is flexible to meet the ever-changing data use cases is paramount. This article discusses in detail the principles and best practices to keep in mind for building effective data pipelines. Let’s start by talking a little more about the challenges.
Challenges of building and managing data pipelines
Broadly, data pipelines enable you to move data from sources into a destination after some data transformations. But it involves a far more complex chain of interconnected activities in practicality.
You must stitch together different tools for data ingestion, integration, data quality, orchestration, data governance, observability, and more. A pipeline welds multiple components and processes to reliably take raw data from one point A, perform simple or complex transformations, and deliver valuable analytics-ready data to point B. We have discussed in this blog, what are data pipelines. Below are common challenges you may face when developing and managing data pipelines.
1) Increase in data volume and new data sources
Data volumes are still growing fast, and most pipelines now ingest a mix of structured, semi-structured, and unstructured events. The issue isn’t just scale. It’s that volume, velocity, and schema change arrive together, which is what breaks brittle ingestion paths.
2) Integrating new data sources
Data pipelines collect data from multiple distributed devices and make it available in a single access point, solving data accessibility problems. However, as the number of data sources increases, it becomes difficult for data pipelines to integrate new sources and accommodate the data from those sources.
Common reasons for this difficulty include– new data sources may be entirely different from existing sources, the format of the data produced may not be compatible with pipeline standards, and the addition of new sources may overload the pipeline’s data handling capability.
3) Change in the structure of data
One of the key challenges with effectively managing data pipelines is the evolving data. A business will have multiple sources and various data types, which will continue to change and evolve over time. It presents challenges when it comes to processing and carrying this data to the destination, whether to a data warehouse, a data lakehouse, or the analytics layer.
4) Data drift
Data drift refers to unexpected and unplanned changes in data that can cause hours of rework and debugging for data pipelines. Even a tiny change to a row or table can require updating each stage in the pipeline and may result in the pipeline going offline for updates or fixes. Unplanned changes can also cause hidden breakages that take months of engineering time to uncover and fix.
5) Poor data quality
High-quality data is critical for excellent data products. However, you may face many data quality challenges, including missing data files, operational errors in non-automated parts of pipelines, data drifts, change in data distribution, data duplication, and more. Too many missing or invalid values mean those variables have no predictive power. Thus, data pipelines need to be updated frequently by changing the business logic according to the changes in data sources.
6) Lack of timeliness
Relatively older ETL technology can be code-heavy and bog down your process. A potential solution can be to switch to ELT, where data is extracted, loaded, and transformed on an as-needed basis (transforming only some data as needed). It can conflict with your data governance strategy, but it can be useful in developing a bigger picture of the data.
Building and debugging data pipelines takes time. You align with the schema, set sources and destinations, check your work, find errors, and go back and forth until you can finally go live, when the business requirements may have changed again. It can create a backlog of work.
Moreover, data pipelines are built with specific frameworks and processors for particular platforms. Changing any infrastructure technology to take advantage of cost savings or other optimizations can mean weeks or months of rebuilding and testing pipelines before deployment.
But pipelines are how businesses derive value from their data, and there are countless ways to deploy them. Below we have discussed engineering aspects and architectural best practices to keep in mind for building a future-proof data pipeline.
7 Key factors to consider when building data pipelines

-
Scalability
Most tools auto-scale, making it easy to add more nodes. But other factors can still create a bottleneck. During processing, data doesn’t always distribute evenly across the nodes you’ve added. And if the processing task can only run on a single node (such as aggregations and joins), it doesn’t matter how many nodes you have. Hot partitions, skewed keys, and expensive shuffles are usually the real scaling limit, not lack of nodes. How do you handle these types of scaling bottlenecks?
Cloud-based data pipelines offer scalable and elastic architecture that allows users to automatically scale compute and storage resources up or down. This architecture distributes compute resources across independent clusters, allowing clusters to grow quickly and infinitely while maintaining access to the shared dataset. Data processing time is easier to predict with this architecture as new resources can be added instantly to support spikes in data volume.
Elastic data pipelines also allow businesses to quickly respond to trends without having to plan weeks ahead. Many companies are now using cloud platforms to obtain on-demand scalability at affordable prices, freeing administrators from having to calibrate capacity exactly and overbuy hardware incessantly. Elasticity also spawns many types of applications and use cases.
-
Automation
Data pipelines are made of many jobs performing different functions. Scheduling and orchestration involves determining when each task should be executed, in what order, and how they should interact with one another. It can involve scheduling tasks to run at regular intervals or in response to certain events, such as arrival of new data from a particular data source.
Tools such as Apache Airflow, dbt, and Azure Data Factory Pipelines are useful in managing scheduling and orchestration, helping automate and streamline the process of coordinating tasks within a pipeline. Many teams also standardize on dataset-level tests and contracts so schema change is detected before it reaches production dashboards.
If you’re standardizing on Microsoft Fabric, Data Factory in Fabric and Fabric pipelines can cover orchestration patterns while keeping governance and lineage closer to the lakehouse.
Moreover, automated metadata injection and schema detection help in creating an adaptable architecture for data pipelines. Metadata injection is a key function of data catalogs that profiles and tags data as it’s ingested and maps it to existing data sets and attributes. It can be used to detect changes in source schema and identify the impact of changes on downstream objects and applications.
Automations should also apply to data transformations and monitoring, with mechanisms for error detection and correction. Monitoring mechanisms should be in place to ensure smooth performance, maintain data integrity, and facilitate advanced analysis. Moreover, end-to-end visibility ensure consistency, proactive security, and error-free data integration.
-
Reliability
The reliability of a data pipeline refers to its ability to perform its intended function correctly and consistently, as well as the ability to operate and test the pipeline through its entire lifecycle. To ensure high reliability, modern data pipelines are designed with a distributed architecture that provides immediate failover and alerts users in the event of node or application failure.
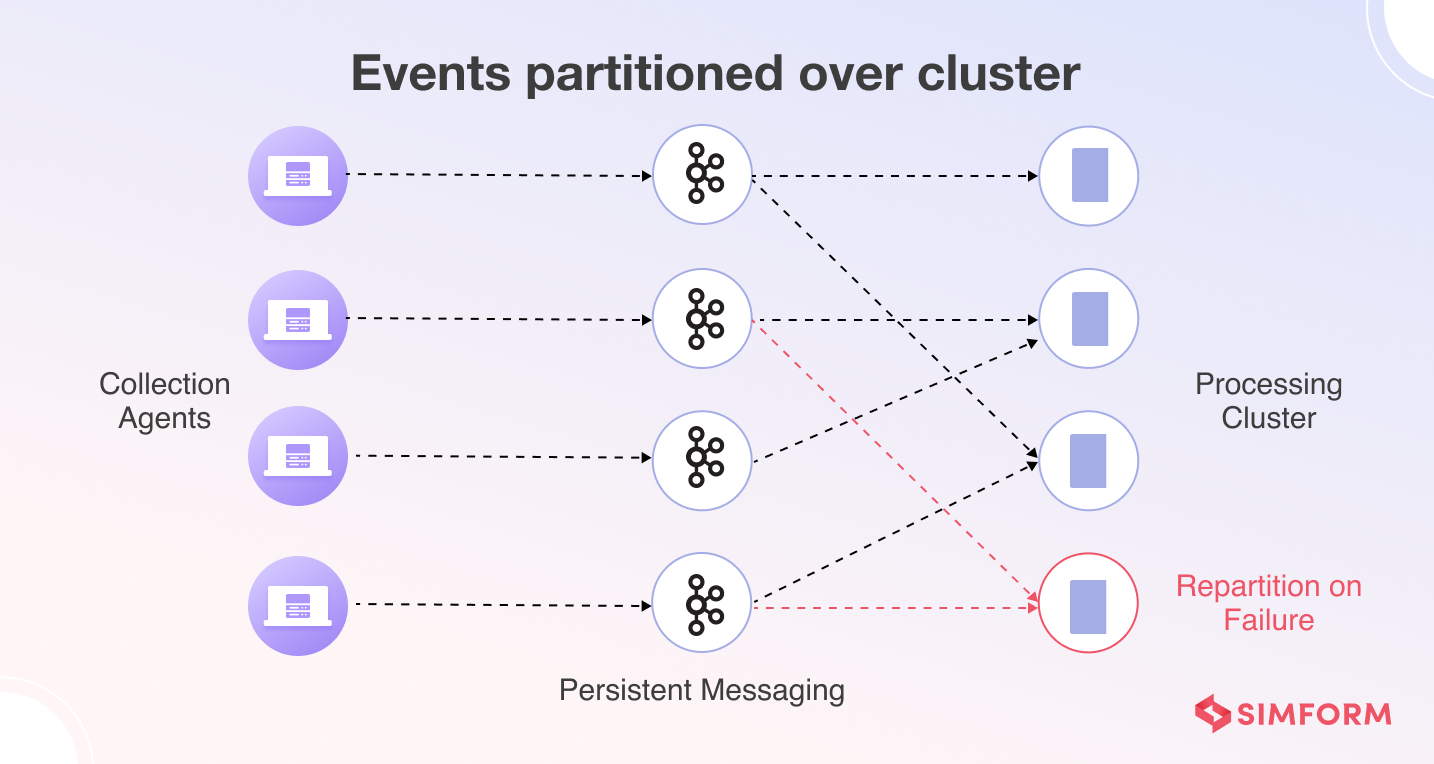
Modern pipelines also have advanced checkpointing capabilities that ensure events are not silently dropped and can be safely replayed without duplicating downstream business facts. Checkpointing keeps track of the events processed, and how far they get down various data pipelines. With persistent messaging, it can prevent data loss and duplication, while also reducing the time to re-execute failed pipelines.
Moreover, downtime can be costly and time-consuming to resolve, so data engineering teams are increasingly relying on DevOps and software engineering best practices to build stronger tooling and cultures that prioritize communication and data reliability.
Finally, in a modern data architecture, resilience, high availability, disaster recovery, and backup/restore capabilities are crucial, especially in cloud environments where outages are commonplace. But the good news is that many cloud providers offer built-in redundancy and failover with good SLAs and allow companies to set up mirror images for disaster recovery in geographically distributed data centers at low cost.
-
Performance
Performance efficiency in data pipelines ensure that the data presented is timely (with ultra low latency) and relevant to support business decisions. Moreover, real-time data processing and analytics are critical for modern data pipelines as they enable businesses to quickly find and act on insights.
One of the key factors affecting the performance of a data pipeline is its ability to ingest and deliver data without delay from a variety of sources, including databases, IoT devices, messaging systems, and log files. To achieve this, organizations often use change data capture (CDC) techniques that capture updates based on triggers, time stamps, or logs.
Another important aspect is the parallelization and distribution of the data pipeline architecture to handle increased loads or demands. This requires developers and engineers to compartmentalize and buffer sensitive operations to mitigate bottlenecks.
In addition, modern data architectures should be adaptable and designed to manage the flow of data from source systems to business users like water. The architecture should create a series of interconnected and bidirectional data pipelines that serve various business needs using base data objects (data snapshots, data increments, data views, reference data, master data, etc.). These data objects serve as building blocks that are continuously reused, repurposed, and replenished to ensure the steady flow of high-quality, relevant data.
-
Security
A modern data pipeline should be a fortress– providing authorized users ready access to data while keeping hackers and intruders at bay. Efficient security protects data, systems, and assets while taking advantage of cloud technologies to improve security.
Securing a data architecture involves cataloging the data, applying privacy controls, compliance with regulatory standards, using ELT pipelines with encryption, etc. It also involves compliance with privacy regulations by encrypting data, masking PII (personally identifiable information), and tracking data lineage, usage, and audit trail.
Security and compliance are key when storing sensitive customer, client, and business data. Organizations must comply with regulatory standards to ensure no personal information is stored or exposed within their data pipelines. Pipelines with process isolation and robust security features, such as data encryption in transit and at rest, can ensure compliance while providing superior performance.
-
Cost-efficiency
As data volumes and data sources increase, your data engineering costs can easily go above the roof. Cost-efficiency requires continuously refining and improving a data system throughout its lifecycle to minimize costs. It involves choosing the right solution and pricing model, building cost-aware systems, and identifying data, infrastructure resources, and analytics jobs that can be removed or downsized over time.
To do this effectively, it is essential to understand the cost at each individual data processing step. Understanding the costs at granular level helps decide where to focus engineering resources for development, and to perform a return on investment (ROI) estimation for the analytics portfolio as a whole.
-
Sustainability
A sustainable architecture focuses on reducing resource usage, especially energy consumption, and maximizing utlilization of existing resources. This can be a tall task given the diversity of the requirements and the complexity of components in today’s data architecture.
But a simple architecture may benefit an organization with small data. For example, it may be better served by a BI (business intelligence) tool with a built-in data management environment rather than a massively parallel processing (MPP) appliance or Hadoop system. Practically, sustainability often comes from reducing unnecessary recomputes, minimizing data duplication, and right-sizing warehouses and streaming jobs.
To reduce complexity, organizations should strive to limit data movement and data duplication and advocate for a uniform database platform, data assembly framework, and analytic platform.
As a Microsoft Solutions Partner for Data & AI, Simform’s data engineering best practices draw on the Azure Well‑Architected Framework principles to build reliable, secure, efficient, and cost‑effective data systems on Azure.
Explore how we turn fragmented supply‑chain data into insights–read the case study
Best practices for building data pipelines
Here are some additional best practices and tips to keep in mind for building a winning data pipeline.
- Understand the engine you’re running
Azure Databricks, Azure Data Factory, Google Dataflow, or Apache Spark – you must understand the underlying engine to scale your jobs significantly. For instance, Spark handles many tasks, including memory management, garbage collection, shuffling data between nodes, etc. But these functions start to fail or degrade as the amount of data being processed increases. Moreover, it means your data engineers need expertise in Spark to configure and tune these functions to handle the load and make their code as efficient as possible.
Also, while the actual coding is relatively straightforward, how the code is executed differs from engine to engine. If you don’t understand how the engines work, you can’t optimize your code to improve performance and deal with errors/issues.
- Know the skill level of your target users
Organizations are shifting towards an open-core approach by leveraging open-source technology to avoid lock-ins and save costs. However, working with open source can be challenging without a proper understanding of the technology. And ultimately, the talents/skills you have or are willing to acquire in-house will dictate the tools you use. Moreover, choosing a programming language for data pipelines is crucial as it impacts accessibility, portability, and ease of testing and automation.
- Maintain data context
It is essential to keep track of the specific uses and context around data throughout the data pipeline. Because as soon as a piece of data loses its connection to the business concept it represents and becomes just a row, it becomes irrelevant and potentially misleading.
Therefore, let each unit define what data quality means for each business concept. Apply and enforce those standards before data enters the pipeline. Then the pipeline will ensure that data context is maintained as the data flows through the various stages of processing.
- Establish consistency in data
Establishing consistency is crucial as access to the correctly formatted data is important for correct analysis results. You can establish the consistency of data sources in two ways. Firstly, check-in all code and data into a single revision control repository. And secondly, reserve source control for code and build a pipeline that explicitly depends on external data being in a stable, consistent format and location.
- Ensure reproducibility by providing a reliable audit trail
To ensure reproducibility of your data analysis, three dependencies need to be locked down– analysis code, data sources, and algorithmic randomness. It ensures that the entire analysis can be re-run by anyone. Moreover, it thoroughly documents the analysis, providing a reliable audit trail which is critical for data-driven decision-making.
How Simform can help
There are numerous methods for implementing a data pipeline, and thus, there are many options enterprises must consider before designing a solution. This article detailed a few (but not limited to) factors you can consider to meet your design and organization’s goals. It is also crucial to consider whether your team resources have the experience to implement a scalable, robust data analytics or big data solution.
Simform’s data engineering services will help you put in place a solution that meets your business objectives as well as your organizational architecture principles. Our data and analytics experts can help you define the processes and technology for a solid data engineering solution, so contact us today!
