It’s family movie night – you have the popcorn ready, and everyone’s excited to watch that new superhero flick finally. You hit play and get the dreaded buffering symbol instead of action scenes. We’ve all felt the frustration of streaming failures. Now imagine that disappointment repeated for your customers. How quickly would they switch services?
But that’s where the best stands out of the rest. You’ll rarely see these kinds of blunders in Netflix and Prime Video. So, what’s their secret sauce to success? A resilient IT infrastructure built on AWS. By expertly utilizing auto-scaling groups across availability zones, intelligence services, and more, they ensure maximum uptime despite traffic spikes and outages.
You need that same availability and resilience in your AWS infrastructure to ensure high application performance. As your customer base grows, downtime means dissatisfied users. By following AWS best practices, you can architect systems as reliable as the streaming giants we rely on for entertainment. In this guide, we’ll unlock the methods industry leaders use to build resilient, always-available applications on AWS.
Understanding resilience in the context of AWS
The AWS Well-Architected Framework defines resilience as “The ability of a system to recover from a failure induced by load, attacks, and outages.” In the context of workloads running on AWS, a resilient workload is one that not only recovers from disruptions, but recovers within a desired timeframe to restore normal operations.
Resiliency is a core component of Reliability, one of the six pillars of the AWS Well-Architected Framework. It works together with other aspects of reliability, like testing for failures, scaling horizontally, and monitoring everything to enable rapid incident response.
To effectively architect resilient workloads on AWS, we must first answer a fundamental question – what resilience-related responsibilities belong to AWS and which ones belong to the customers?
Shared Responsibility Model for resiliency
The Shared Responsibility Model delineates what you and AWS are each responsible for when building resilient systems. AWS manages the underlying infrastructure resiliency while you architect and configure fault-tolerant applications.
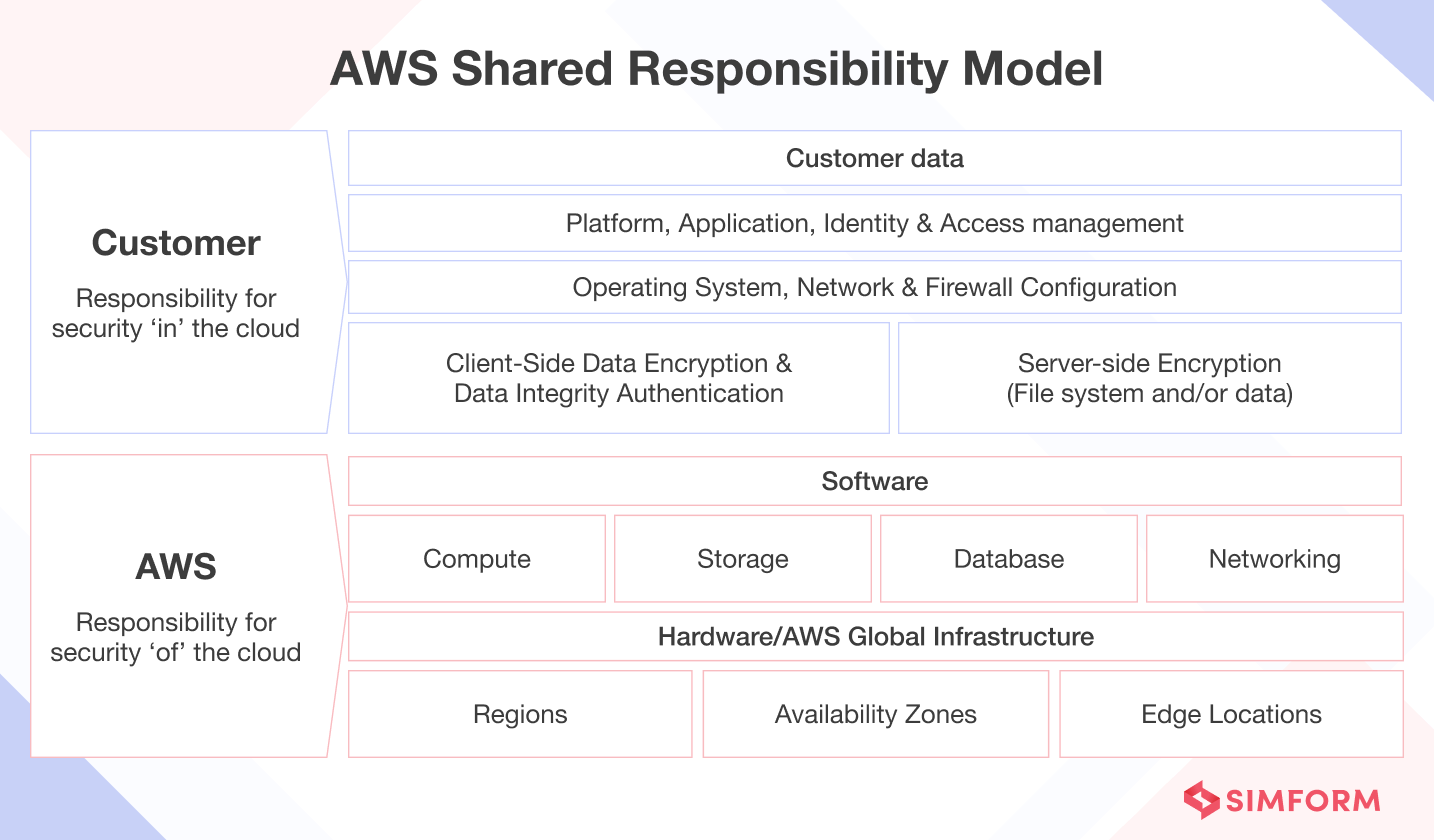
AWS responsibility – Resiliency of the cloud
AWS is responsible for the resiliency of its cloud infrastructure, including hardware, software, networking, and facilities that run AWS Cloud services. They have designed their Global Cloud Infrastructure with these considerations:
- Regions are fully isolated and Availability Zones (AZs) are physically separated partitions of infrastructure within a Region. This isolates faults within specific AZs.
- AZs are interconnected through high throughput, low latency dedicated metro fiber rings for synchronous replication.
- All networking between distinct AZs is encrypted for security.
- Cross-AZ networking capacity supports replicating applications and data across multiple zones for high availability.
- Distributed applications across zones safeguards against power outages, natural disasters, and other localized disruptions impacting single AZs.
- With AWS handling resiliency considerations behind the scenes, you can architect cloud-based solutions knowing the infrastructure is redundant and reliable.
Customer responsibility – Resiliency in the cloud
As the customer, your responsibility for the resiliency of workloads in the cloud is determined by the AWS services you use. While AWS provides resilient infrastructure and services, you must architect and deploy fault-tolerant solutions.
For example, for Amazon EC2 instances, you are responsible for deploying across multiple Availability Zones, configuring auto scaling for self-healing, and architecting resilient workloads. For managed services like S3 and DynamoDB, AWS operates the underlying infrastructure while customers manage resiliency of their data via backup, versioning, and replication.
Overall, AWS gives you building blocks and intelligent services, but how you assemble resources impacts recovery objectives.
In essence, you can achieve highly resilient cloud workloads by leveraging AWS’s resilient infrastructure and services and making sound architectural decisions. However, identifying and closing potential resiliency gaps requires specialized expertise and a set of best practices.
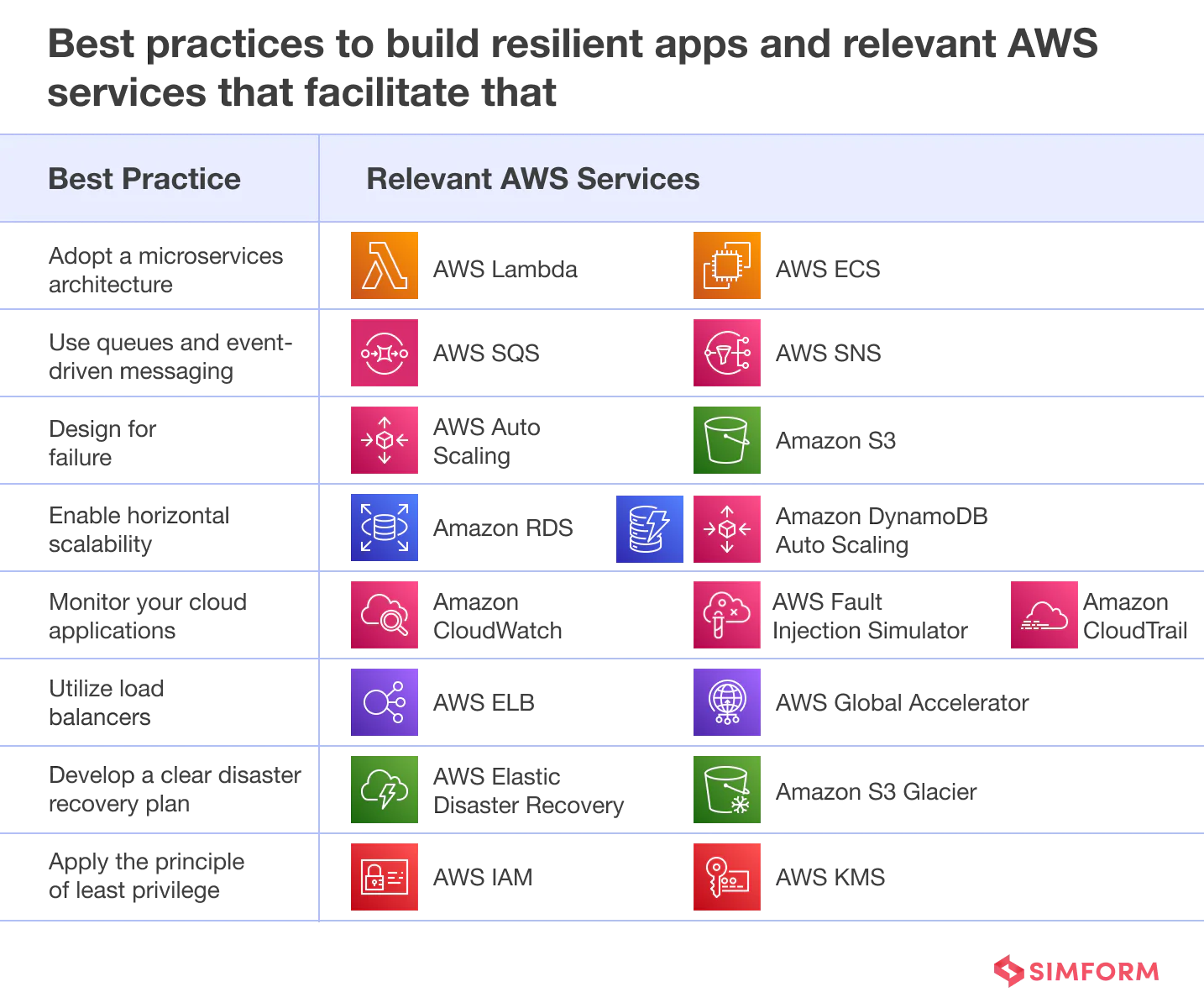
Best practices to build and maintain resilient applications
With extensive real‑world experience architecting resilient cloud applications on AWS, guided by AWS Well‑Architected Framework principles, Simform has developed a core set of availability best practices spanning infrastructure, data, and application layers. Drawing on years of helping enterprises adopt AWS, we ensure these practices are tailored for your unique reliability and performance requirements.
1. Adopt a microservices architecture
Embracing a microservices architecture enhances resilience by breaking your system into small, independent services. Each microservice operates autonomously, limiting the impact of failures to specific components rather than the entire application. This decentralized structure ensures that faults are isolated, preventing cascading system failures.
Additionally, microservices are smaller, simpler, and allow differentiation of availability needs for different services. Resources can be focused on the services needing the highest availability.
For example, an Amazon.com product page invokes hundreds of microservices, but only a few with price/product details must have high availability. If other services like photos or reviews are unavailable, customers can still view products and make purchases. Overall, microservices enable selectively prioritizing availability where it is most critical.
AWS services to adopt a microservices architecture
- AWS Lambda:
As a serverless compute service, Lambda enables you to focus solely on writing code without provisioning or managing servers. This abstraction from infrastructure allows you to create lightweight, independent functions that can be orchestrated into microservices.
Each Lambda function you create operates in isolation, automatically scaling to demand and experiencing no downtime. This serverless architecture inherently enhances resilience, as you can distribute functions across multiple availability zones. With Lambda handling the underlying infrastructure, you can build highly resilient applications comprised of distributed functions that scale independently to meet demand.
- Amazon Elastic Container Service (ECS):
Amazon ECS enables you to run tasks and services across multiple AZs to make your applications resilient. By specifying placement constraints and launch types when configuring ECS services, you can distribute identical application containers across distinct AZs.
ECS handles underlying infrastructure dependencies, allowing you to focus solely on deploying application containers across zones. If an AZ experiences an outage, ECS will redistribute containers to maintain desired counts. Leveraging ECS for multi-AZ deployments provides inherent redundancy and high availability without needing to manage separate infrastructures independently.
2. Use queues and event-driven architectures
A queue acts as a durable buffer that persists messages even if producing or consuming applications fail. Producers simply add messages to the queue without any dependency or awareness of which consumer applications will process them. This loose coupling isolates failures – if a consumer crashes, the queue preserves any unpublished messages while the consumer recovers.
Queues also smooth traffic spikes as they absorb additional messages during peak loads without slowing producers. By providing asynchronous messaging persistence and abstraction between components, queues limit blast radius of failures across distributed systems.

Event-driven architectures further boost the resilience that queues provide. With this design, applications don’t make direct requests to each other. Instead, they communicate by generating event messages about changes happening in the system and putting them on queues. Other applications subscribe to events they are interested in from these queues. This loose coupling isolates failures.
By linking components only via events on durable queues, failures stay localized. This prevents a failing component from cascading issues across the whole system.
AWS services for queues and event-driven messaging
- AWS Simple Queuing Service (SQS):
SQS provides a fully-managed, highly scalable message queuing service that reliably stores messages sent between producers and consumers, even if receiving systems are disrupted. This durable buffering of messages across loosely coupled components enables building fault-tolerant workflows and prevents cascading failures.
- AWS Simple Notification Service (SNS):
AWS SNS delivers real-time alerts, ensuring immediate awareness of problems like system failures or performance issues. With SNS, developers can swiftly respond to incidents, minimizing downtime and improving overall application reliability.
How did Itaú Unibanco strengthen its resilience posture by moving to AWS?
Itaú Unibanco, a prominent financial institution from Brazil, bolstered its resilience and availability on AWS through strategic utilization of queues and event-driven messaging. Facing the challenge of enhancing their resilience posture, they implemented Amazon SQS and Amazon SNS to optimize their system’s reliability. By adopting SQS, the bank successfully decoupled components of its architecture, reducing dependencies and enhancing overall system reliability.
3. Design for failure
The idea behind “design for failure” is to architect your solutions assuming that failures will happen, rather than trying to prevent them completely. This means baking resiliency capabilities into your applications from the start.
Some tips when adopting a design for failure approach on AWS:
- Build in redundancy – Deploy critical components like databases across multiple Availability Zones so there is backup capacity if one zone goes down.
- Automate healing – Script reboots, failovers, and recovery workflows so when failures occur your system can self-correct with no human intervention.
- Test failure scenarios – Engineer controlled failures through chaos testing to uncover weaknesses and prove out your resiliency measures.
- Degrade gracefully – When non-critical functions fail, critical paths should stay functioning, even if at lower performance.
Building in recovery workflows upfront ultimately reduces downtime and disruption when the inevitable issues crop up down the line.
AWS services that help to design for failure
- AWS Auto Scaling:
AWS Auto Scaling enables resilient application design by automatically adjusting instances to match demand and distributing traffic across multiple instances. It promptly replaces unhealthy instances during failures, ensuring continuous availability. The tool’s proactive approach optimizes performance, enhancing fault tolerance and minimizing the impact of potential failures.
- Amazon Simple Storage Service (S3):
Amazon S3 minimizes potential failures by distributing data across servers and locations. Automatic replication enhances durability, reducing data loss risk. S3’s scalable infrastructure adapts to varying workloads, optimizing performance. Features like versioning and cross-region replication empower proactive management and recovery, ensuring a robust application architecture.
4. Enable horizontal scalability for varying loads
When you scale horizontally, you add more machines or nodes to your system, distributing the workload efficiently. This approach enhances resilience by preventing a single point of failure and optimizing resource utilization.
Dynamically adjust resources based on demand to accommodate traffic fluctuations, ensuring consistent performance. With this flexibility, your application can gracefully handle increased user activity or unexpected surges without compromising stability.
AWS services that enable horizontal scalability
- Amazon Relational Database Service (RDS):
Amazon RDS facilitates horizontal scalability by offering features like Read Replicas and Multi-AZ deployments. Read Replicas distribute read traffic across multiple database instances, easing the load on the primary database. You can scale your application by diverting read queries to these replicas.
Additionally, Multi-AZ deployments ensure resilience by automatically replicating data to a standby instance in a different Availability Zone. In case of a failure, it seamlessly switches to the standby, minimizing downtime.
- Amazon DynamoDB Auto Scaling:
By automatically adjusting capacity based on demand, Amazon DyanamoDB Auto Scaling ensures optimal performance even during unpredictable traffic spikes. This eliminates the need for manual intervention, saving time and minimizing the risk of under-provisioning.
5. Define SLA and monitor your cloud applications
Defining Service Level Agreements (SLAs) for cloud applications establishes clear performance and availability expectations. By monitoring metrics such as minimum uptime, recoverability objectives, maximum failover duration, etc., you can proactively identify deviations from expected performance. This real-time visibility into your application’s health allows for swift responses to potential issues, ensuring that the system remains resilient to unexpected challenges.

Continuous monitoring is crucial for resilience as it enables organizations to detect and respond to potential threats or disruptions in real time, minimizing downtime and impact on operations.
Organizations typically employ a combination of network monitoring tools, performance monitoring, and incident detection systems to proactively identify anomalies, vulnerabilities, and potential points of failure, so they can implement timely measures to enhance system resilience.
AWS services for continuous monitoring and chaos engineering
- Amazon CloudWatch:
Amazon CloudWatch provides observability across metrics, logs, and events for both infrastructure and services in an AWS environment.
For resilience, CloudWatch allows establishing alarms and triggers based on critical operational metrics like latency, error rates, CPU loads etc. These alarms can automatically trigger actions like failing over instances or scaling capacity when defined thresholds are breached.
- AWS CloudTrail:
By capturing API calls and related events across AWS services, CloudTrail provides a comprehensive audit trail. You gain real-time insights into user activity, resource changes, and potential security threats. This transparency lets you quickly detect and respond to issues, enhancing your application’s reliability.
- AWS Fault Injection Simulator:
With this tool, you actively inject faults into your system, simulating real-world scenarios to identify vulnerabilities and enhance your application’s robustness. You gain valuable insights into your application’s behavior under stress by orchestrating controlled disruptions, such as network latency or instance failures. This firsthand knowledge enables you to preemptively address potential weaknesses, bolstering your system’s overall reliability.
6. Utilize load balancers to distribute workloads across multiple Availability Zones
Load balancers ensure even distribution among various server instances, optimizing performance and preventing any single point of failure. This approach increases fault tolerance; if one Availability Zone experiences issues, traffic seamlessly gets redirected to others.
Load balancing also enhances scalability to efficiently utilize resources by accommodating fluctuating demand across zones. This proactive distribution of workloads minimizes downtime, improves user experience, and supports a resilient IT infrastructure.
AWS services for load balancing
- AWS Elastic Load Balancing (ELB):
With robust cross-zone load balancing capabilities, ELB intelligently directs traffic to healthy instances across multiple zones, preventing overload on any one server. By equiping cloud applications with ELB and integrating it tightly with auto scaling groups, architects can ensure high availability and consistent responsiveness.
- AWS Global Accelerator:
AWS Global Accelerator enhances your application’s global availability and fault tolerance by intelligently distributing traffic across multiple AWS endpoints. It employs Anycast IP addresses that route users to the nearest AWS edge location, minimizing latency and improving user experience.
With built-in, scalable load balancing, Global Accelerator dynamically adjusts traffic distribution based on endpoint health, efficiently steering users away from unhealthy instances.
7. Develop a clear disaster recovery plan
A Disaster Recovery (DR) plan is essential to ensure continuity in the face of unforeseen events. It safeguards against data loss, system failures, or natural disasters, minimizing downtime and protecting critical operations.
Creating a DR plan involves identifying potential risks, assessing their impact, and swiftly outlining steps to mitigate and recover from disruptions. You must establish communication protocols, designate responsibilities, and regularly test the plan to guarantee its effectiveness.
AWS services for disaster recovery
- AWS Elastic Disaster Recovery:
By leveraging this service, you can seamlessly replicate your critical data across AWS regions, ensuring swift recovery in case of disruptions. With real-time monitoring and automated health checks, AWS Elastic Disaster Recovery enables proactive identification of issues, promoting a responsive and resilient application architecture.
- Amazon S3 Glacier:
With Amazon S3 Glacier’s low-cost storage and flexible retrieval options, you can efficiently store backup data, ensuring rapid recovery during a disaster. By seamlessly integrating with Amazon S3, Glacier enables you to build resilient applications with redundant data storage.
How did CloudWave modernize EHR disaster recovery by moving to AWS?
CloudWave is a provider of cloud and managed services for healthcare organizations. They previously hosted disaster recovery and EHR systems in two separate on-premises data centers, which was expensive to maintain. To reduce costs and improve efficiency, CloudWave migrated these systems to AWS. By leveraging AWS services like S3 and S3 Glacier, CloudWave streamlined its disaster recovery strategy.
Implementing AWS S3 allowed CloudWave to achieve scalable and durable data storage, ensuring rapid access to critical healthcare information during emergencies with an 83% reduction in return–to-operation time. S3 Glacier, with its cost-effective archival storage, enabled CloudWave to manage long-term data retention requirements, helped them save $1 Million annually, and reduced storage costs by 25%. Ultimately, CloudWave’s adoption of AWS resulted in a resilient, cost-effective, and modernized disaster recovery solution for their EHR system.
8. Apply the principle of least privilege
Applying the principle of least privilege (PoLP) enhances resilience by minimizing the potential impact of security breaches and system failures. By granting users and processes only the permissions necessary for their specific tasks, you reduce the attack surface and limit the damage that could occur in the event of a compromise.
For instance, a web server should only have read access to the necessary files and directories, not full system control. In the event of a security incident, the impact is contained because the compromised entity has limited privileges. This approach mitigates the cascading effect of a single point of failure, making the overall system more robust.
AWS services for applying the principle of least privilege
- AWS Identity and Access Management (IAM):
AWS IAM enables granting minimal, granular permissions to users and workloads through security policies aligned with the principle of least privilege. Instead of broad access, IAM allows defining fine-grained privileges scoped down to specific resources and API actions. By restricting overentitled permissions through IAM’s attribute-based access control, blast radius is limited if credentials or workloads get compromised.
- AWS Key Management Service (KMS):
AWS Key Management Service (KMS) enables creating and controlling encryption keys used to protect data and workloads. Instead of sharing master keys widely, individual workloads can be granted precisely scoped permissions to decrypt using specific KMS keys. This restrictive key control and management facilitated by KMS ultimately boosts resilience by constraining blast radius if vulnerabilities are exploited.
While these best practices equip teams to construct resilient AWS architectures, real-world implementation on enterprise-grade workloads can prove challenging without deep AWS expertise. This is where a cloud consulting provider with proven AWS experience, like Simform, comes in.
How has Simform helped enterprises build resilient applications?
With over a decade of perfecting cloud reliability solutions, Simform has established proven AWS expertise, validated through stringent AWS technical and experience audits.
Backed by 200+ AWS certifications including availability specialty certifications, Simform’s highly skilled cloud architects design solutions capable of high performance even amidst disruption. Our team keeps pace with the latest AWS resilience services through continuous education, ensuring customers benefit from cutting-edge capabilities.
Let’s explore some case studies of how Simform has enabled organizations to leverage the Agility, Reliability and Innovation of AWS while optimizing for performance targets, continuity needs, and compliance obligations unique to complex multinational businesses.
1. The International Hockey Federation ensured zero downtime and managed 100K+ concurrent visitors without compromising performance by partnering with Simform
The Hockey World Cup was the most significant event for the International Hockey Federation, with over 3 million viewers in Asia alone. They wanted to launch a more robust web presence before the event to be the digital companion of the viewing experience.
Challenges:
The client required a dynamic front-end for enhanced adaptability–a system that seamlessly supports diverse content types, widgets, and dynamic content page creation. Emphasis was placed on a smarter content management and publishing system to alleviate developer workload and enhance app performance.
Given the high daily traffic on the public domain website, managing spikes in user activity while maintaining optimal performance posed a challenge. Additionally, a swift deployment was crucial to meet the impending deadline for the hockey World Cup, just months away from project initiation.
Solutions:
Our developers employed a modern architecture approach, utilizing a headless CMS to construct a dynamic front end capable of adapting to various content types. We implemented server-side rendering, caching strategies, lazy loading, and other measures to ensure scalability and performance.
For optimized content delivery and a smarter content management system, we deployed the solution on AWS EC2, utilized S3 for media content storage, and leveraged Cloudfront to serve content to a daily global audience of 100,000 visitors. This strategy proved effective in managing traffic spikes while maintaining peak performance. To expedite deployment, we integrated CI/CD pipelines using Jenkins and automated infrastructure creation through AWS CloudFormation for faster delivery.
Key Results:
- 200% reduction in time to first render from 3 to 1 second.
- 0% downtime during new deployments.
- 100% scalable platform with the capacity to serve 100,000+ visitors concurrently.
2. A 360-degree marketing analytics platform for eCommerce reduced the system’s latency and infrastructure cost by 30% by partnering with Simform
A 360-degree marketing analytics platform for eCommerce needed improvement in terms of scalability, availability, integration, and security.
Challenges:
The client was experiencing limitations in terms of scalability, availability, integration, and security due to the fact that its cloud infrastructure was hosted on DigitalOcean, which lacked these qualities for large-scale projects.
As the platform grew and required more resources, it started experiencing performance issues and limited global coverage. Additionally, the platform faced challenges integrating with other services and ensuring data security, which hindered its ability to serve its customers effectively.
Solutions:
We implemented Amazon EKS for a scalable and reliable solution, effectively managing and orchestrating containerized applications. The platform achieved high availability, scalability, and security by leveraging its built-in features. The seamless integration of Amazon EKS with RDS, Lambda, and KMS enabled the creation of a fully integrated and secure environment.
To establish a scalable and fault-tolerant infrastructure, we utilized Karpenter for auto-scaling and Nginx ingress for load balancing. It ensured that the platform could handle traffic spikes without compromising performance. AWS KMS handled encryption for data security, while AWS IAM managed access control.
Key Results:
Why choose Simform for building resilient applications on AWS?
By combining deep AWS Well-Architected Framework implementation experience with cloud-native offerings, platform expertise, and emphasis on measurable reliability, Simform has emerged as a trusted choice for realizing resilience on AWS.
- Over a decade of expertise with AWS cloud infrastructure enables us to architect optimized, future‑proof AWS environments.
- With 200+ AWS-certified professionals on staff, including solution architects and engineers, we provide comprehensive cloud implementation guidance.
- Our complete lifecycle services, from advisory and development to migration and management, deliver continuity through resilience best practices for AWS projects.
- We build security at every layer, conducting rigorous reviews, penetration testing, and remediation to enable regulatory compliance.
- Our focus on availability and scalability empowers innovation and growth with cloud-native, serverless, and containerized architectures.
- Our automation enables self-service agility while maintaining governance, freeing clients to focus on core business goals.
Want to leverage these benefits for your enterprise? Request a free consultation call with our AWS resilience experts.