- In June 2024, a New York Stock Exchange glitch caused extreme price distortions and led Interactive Brokers to disclose a $48 million loss tied to the incident.
- In October 2025, AWS reported an outage that disrupted businesses worldwide, reminding teams that even mature cloud platforms can have failure modes with customer impact.
- In November 2025, a Cloudflare outage prevented thousands from accessing major platforms, showing how a single infrastructure layer can cascade into widespread service disruption.
These are some of the biggest software product engineering projects in the world. If these can fail, so can yours.
This blog outlines the key reasons software engineering projects fail and provides practical strategies to avoid these pitfalls.
First of all, what does a failing project look like?
A failing software product engineering project exhibits several red flags. Some of those might be:
- Missed deadlines and frequent schedule overruns
- Continuous scope creep and an inability to define clear project objectives
- Poor communication and lack of collaboration among team members
- High staff turnover and low team morale
- Consistently exceeding the allocated budget without clear justifications
- Frequent quality issues, including bugs and defects
- Inadequate stakeholder involvement and a lack of engagement
- Continuous changes in project requirements without proper assessment of impact
- Insufficient planning and risk management lead to unexpected setbacks
- Lack of accountability and responsibility for project outcomes
As you become familiar with the signs that indicate a failing project, it’s crucial to understand the underlying reasons behind such failures.
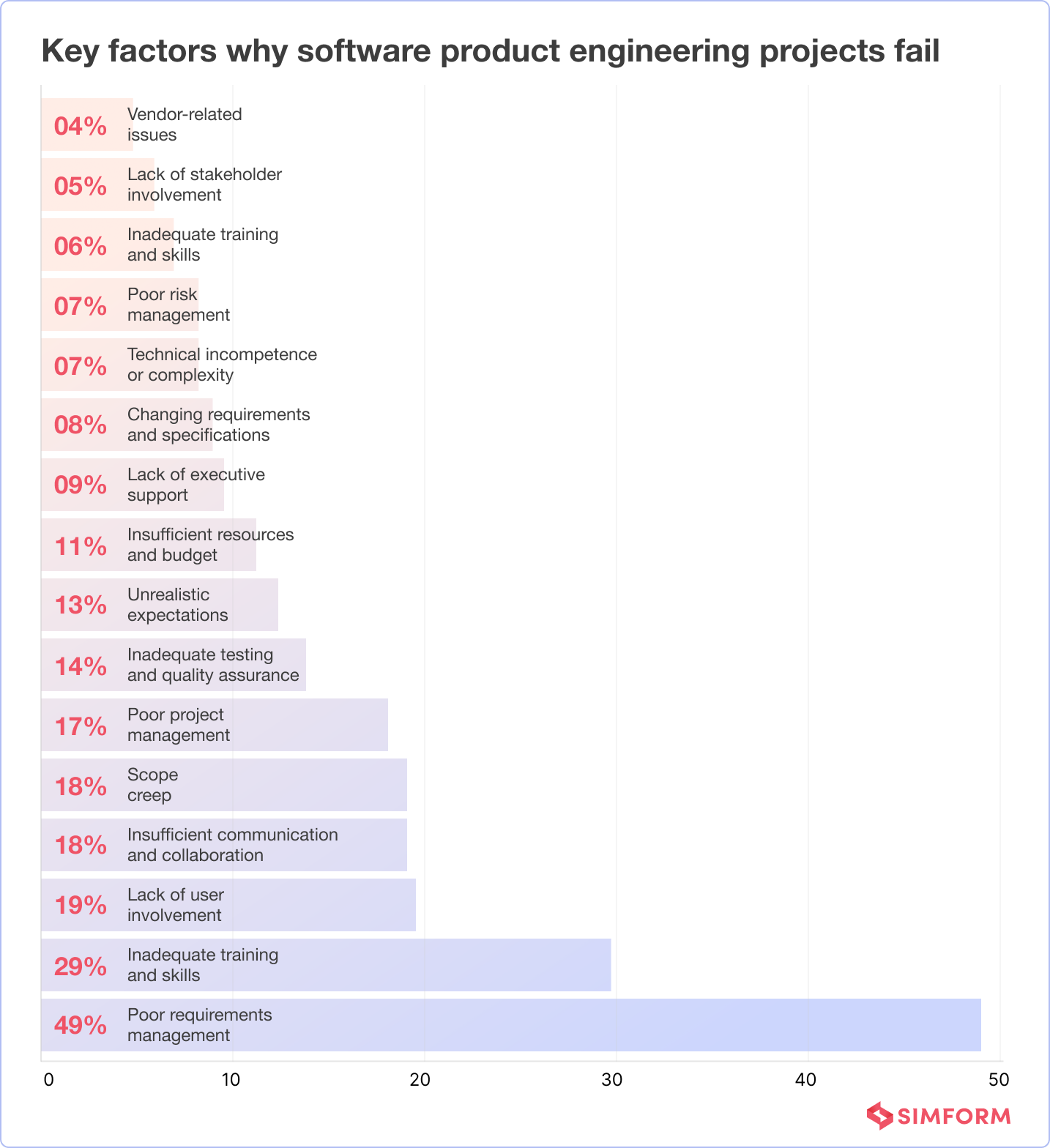
Reasons why software product engineering projects fail
The reasons behind software project failures are complex, often stemming from multiple contributing factors. These factors can range from issues related to project planning and communication to technical challenges and human factors.

#1. Poor architectural design
Poor architectural design can undermine productivity and profitability in many ways:
- A lack of architectural foresight often leads teams down the path of least resistance, resulting in technical debt accumulation and slow feature development.
- When you tweak one part of the code, seemingly unrelated components break, causing endless debugging and rework. This undermines your product’s stability.
- It limits your ability to adapt to changing requirements or technologies. You’re forced to patch rather than innovate, making your product increasingly outdated.
- Lack of observability: when teams cannot trace failures across services, MTTR grows and release confidence drops.
Correcting these issues is crucial for achieving profitability and preventing software failure. So, invest in a robust, flexible architecture to secure your software’s future success.
The FAA’s NOTAM system outage was traced to a damaged database file, and it contributed to a nationwide ground stop.
The incident is a clean reminder that architecture is not just structure. It is resilience at the core data layer.
If a single critical data dependency can fail without graceful degradation, the result is systemic downtime rather than a contained incident.
How to design the right architecture?
- Clearly define the system requirements and goals before designing the architecture.
- Use a modular and component-based approach to promote reusability and maintainability.
- Apply the principle of separation of concerns to ensure that each component has a clear and specific responsibility.
- Design with flexibility in mind to accommodate future changes and enhancements.
- Document the architecture thoroughly to facilitate communication and understanding among team members.
- Conduct regular architecture reviews and evaluations to identify potential issues and make necessary improvements.
#2. Inefficient testing and quality assurance
When the quality assurance strategy for a software project lacks thorough planning and meticulous execution, it leads to a significant number of undetected bugs, security vulnerabilities, and usability issues in the application. Ultimately, the software gets released with critical flaws that impact user experience and functionality. Customer satisfaction drops, and the project owner’s reputation suffers a serious blow.
A common failure pattern is shipping a feature that changes access, permissions, or communication defaults without testing real-world scenarios. It works in the happy path, but creates unexpected exposure, abuse vectors, or workflow breakage once real users interact with it at scale. When acceptance criteria and permission scenarios are not validated before release, the cost shows up in production.
How to ensure efficiency in software testing?
- Start testing early in the software development lifecycle to catch defects at the earliest possible stage.
- Define clear and measurable quality objectives for the software project.
- Develop a comprehensive test plan that covers all aspects of the software.
- Invest in automated testing tools and frameworks to maximize coverage and efficiency.
- Implement proper defect tracking and management processes to monitor and resolve issues identified during testing.
- Regularly review and update the test cases and test scripts to align with changing requirements and enhancements.
#3. Lack of scalability planning
Not planning for scalability in your software can cause big problems. A lack of scalability in your software can stem from:
- Bad database design: If your database isn’t set up right, it will slow down as it grows.
- Picking the wrong technology: Choosing technologies that don’t scale well can limit your system’s growth. For example, using a non-scalable database or the wrong web server can cause problems.
- Poor code architecture: Using an inflexible system can make it difficult to scale. It’s better to use a flexible approach that lets you grow specific parts of your software easily.
- Skipping load balancing: Without load balancing, heavy traffic can cause your server to crash. Distributing requests across multiple servers helps keep everything running smoothly.
- Ignoring asynchronous processing: Some tasks should be done separately from the main application to avoid slowing things down. Remember to decouple these tasks to prevent bottlenecks.
- Dependency limits: third-party APIs, rate limits, and quota ceilings often become the real bottleneck at scale.
During Hulu’s first Oscars livestream in March 2025, the stream faced major issues under peak demand and even cut off before the final awards due to a scheduling system problem.
This is a modern scalability failure pattern: the system works on normal days, but it was not engineered for the worst demand window and live-event edge cases where timing and load spike together.
How to plan for scalability?
- Start scalability planning early in the software development process.
- Conduct thorough performance testing to understand system limitations and identify potential scalability issues.
- Design the system with modularity and loose coupling to allow for easier scalability.
- Use cloud-based infrastructure and services that offer scalability options.
- Monitor system performance and user metrics to proactively identify scalability needs.
#4. Insufficient backup and disaster recovery planning
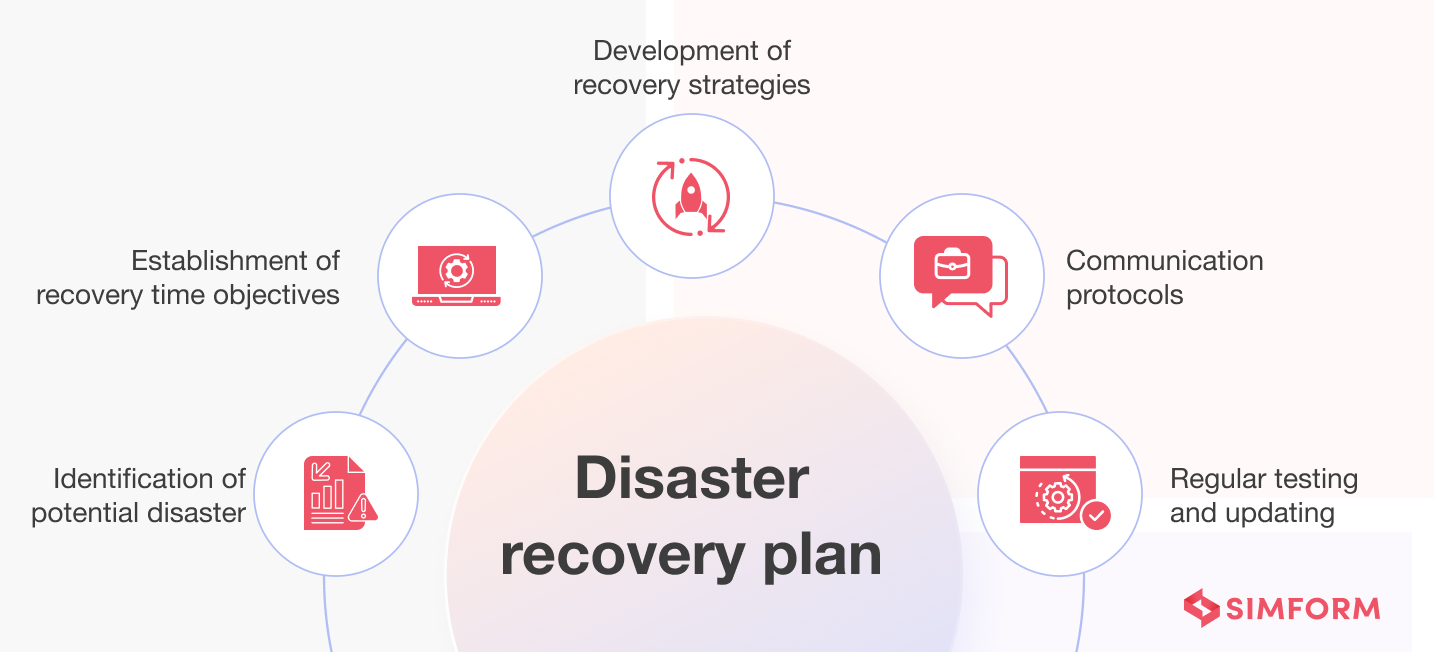
Insufficient backup and disaster recovery planning can spell trouble for software product engineering. Suppose your company is developing a cutting-edge product, but disaster strikes. A server crashes, data gets corrupted, or even worse, a natural disaster hits your data center. Without a backup and recovery plan, you could lose crucial data, delay product development, and lose customers’ trust. It’s like building a sandcastle without a moat to protect it.
In May 2024, UniSuper lost access to services after Google Cloud accidentally deleted UniSuper’s private cloud account due to an “unprecedented misconfiguration.”
Recovery succeeded because UniSuper had external backups and could restore services. The lesson is direct: backup is not a checkbox. DR only works when backups are independent, restoration is practiced, and recovery paths are designed before the incident.
How to ensure robust disaster recovery planning?
- Conduct a thorough risk assessment to identify potential disasters and their potential impact on the business.
- Establish a clear and comprehensive disaster recovery plan that outlines roles, responsibilities, and procedures for various disaster scenarios.
- Regularly back up critical data and systems, ensuring off-site storage or cloud-based backups for redundancy.
- Engage with external experts or consultants to assess the effectiveness of the disaster recovery plan and provide recommendations for improvement.
#5. Scope creep
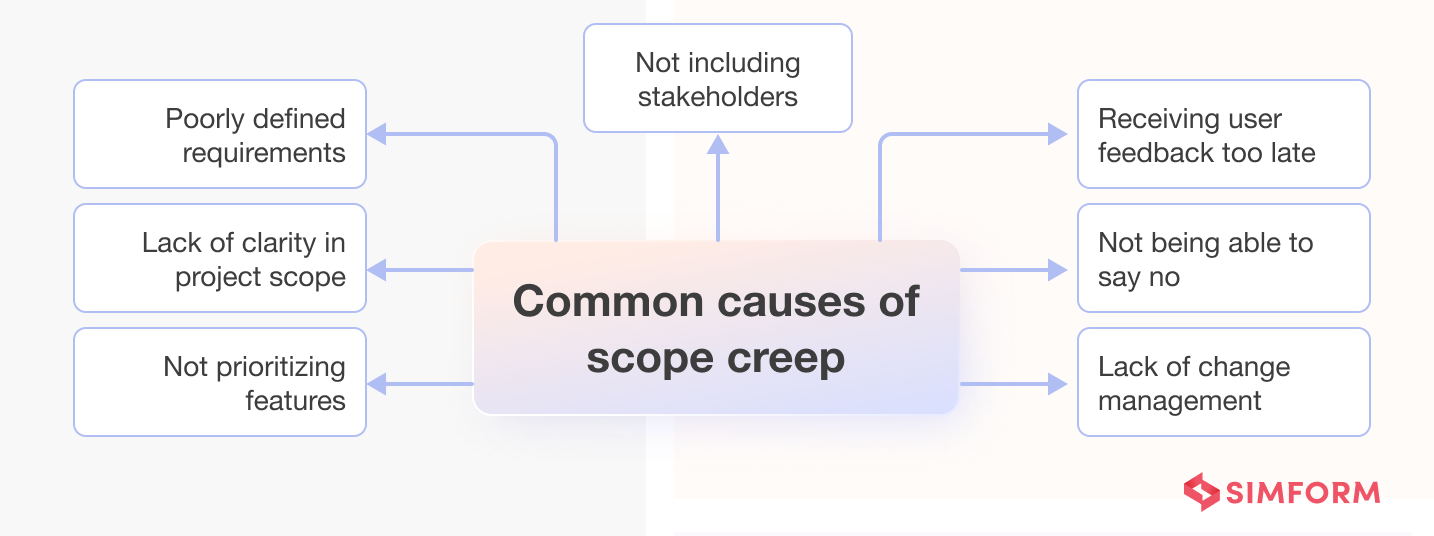
Scope creep happens when new features or requirements get added to a project without proper evaluation or control. It may initially seem harmless, but it can snowball into a disaster. Tight deadlines get extended, costs soar, and resources get stretched thin.
One common reason for scope creep is inadequate requirements gathering. When you, as a project stakeholder, don’t clearly define and document your software’s features and functionalities, it opens the door for ambiguous interpretations and additions. This ambiguity can result from unclear user stories, vague acceptance criteria, or incomplete use cases.
Another factor contributing to scope creep is the lack of change control procedures. Without established processes for assessing, approving, and documenting changes, developers may implement adjustments on the fly, leading to an uncontrolled expansion of the project’s scope.
The Denver International Airport’s (DIA) baggage handling system faced a catastrophic failure, largely due to scope creep. The primary issue was the decision to automate the baggage handling system entirely, a bold move. The project started with a modest scope, but additional features and requirements were added. It became a big, complicated setup with many conveyor belts, sorting gadgets, and tons of motors, sensors, and controls.
To accommodate these changes, software had to be continually updated, increasing the risk of malfunctions. Coordination among various teams became increasingly challenging as the scope expanded. The scale and complexity of the project led to unforeseen technical issues, such as software bugs and mechanical failures, creating a nightmare for troubleshooting.
How to avoid scope creep?
- Clearly define and document project requirements at the beginning, ensuring all stakeholders have a shared understanding of the project scope.
- Establish a change management process that requires formal approval for any changes to the project scope.
- Conduct thorough analysis and impact assessments before approving any scope changes, considering the time, resources, and potential risks associated with them.
- Regularly communicate and engage with stakeholders to manage expectations and address any scope-related concerns or requests early on.
#6. Technical debt
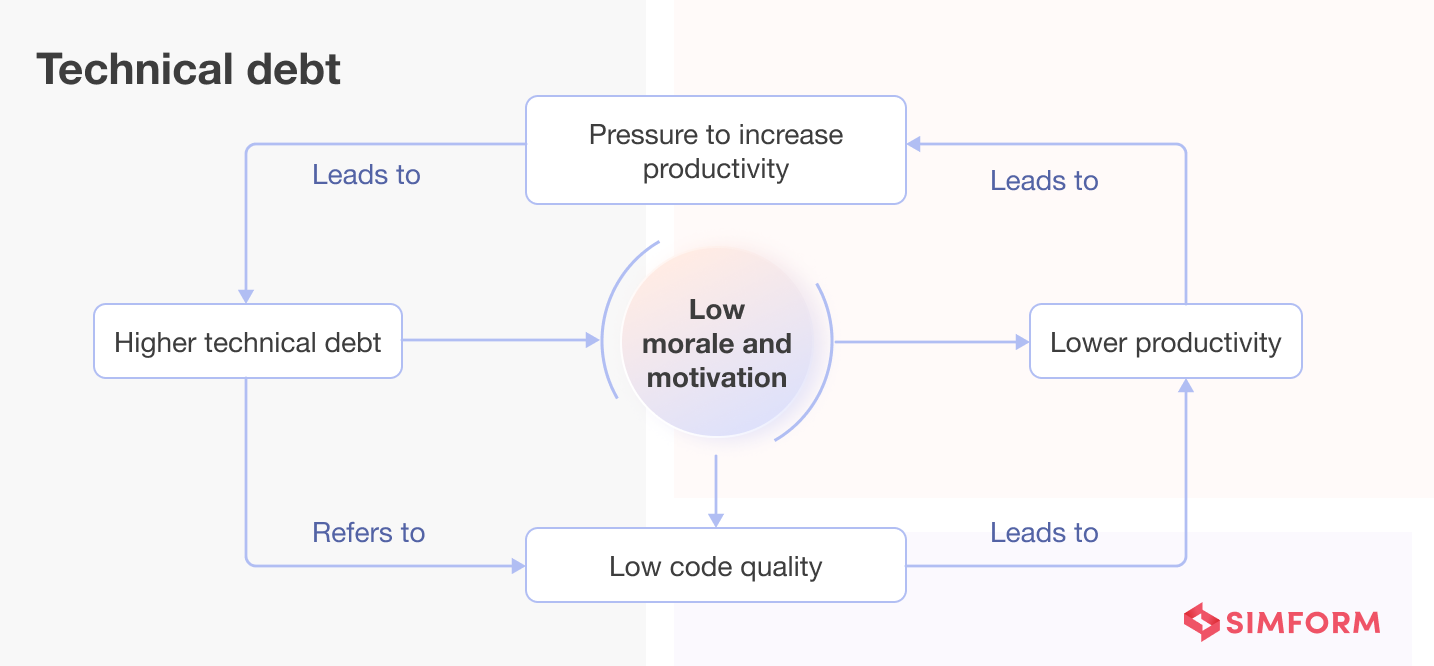
Technical debt refers to accumulated shortcuts, poor coding practices, and unfinished work within the software. These shortcuts may lead to lower code quality and readability, which in turn, make it harder for developers to understand and modify the codebase. As technical debt accumulates, it becomes more challenging to implement new features or fix bugs, slowing down development and reducing productivity. Moreover, the need to constantly work around existing issues increases maintenance costs over time.
Knight Capital Group lost a whopping $440 million, all thanks to technical debt. A software update to their trading system introduced a new algorithm for handling stock orders. However, due to technical debt and a lack of proper testing, an old dormant piece of code, previously used for testing, was left in the production environment. This code caused the new algorithm to execute incorrectly and generate a massive volume of incorrect trades within minutes. It was a nightmare they could’ve avoided if they had dealt with their technical debt sooner.
How to deal with technical debt?
- Practice good coding and development practices, including code reviews, refactoring, and adhering to coding standards and best practices.
- Conduct regular technical debt assessments and prioritize their resolution based on their impact on the project.
- Allocate dedicated time and resources to address technical debt as part of the development process.
- Document and track technical debt items, including their impact and priority, in a central repository or issue tracking system.
- Ensure proper planning and estimation of development tasks to avoid shortcuts and rushed solutions that contribute to technical debt.
- Invest in continuous integration and automated testing to catch and fix issues early in the development cycle.
- Use feature flags and progressive delivery so risky changes can be contained and rolled back without full-scale blast radius.
#7. Large, disjointed teams
Large, disjointed teams can substantially contribute to software product failure due to several technical challenges exclusive to their size. Firstly, communication breakdowns become more pronounced as the team grows. Large teams often struggle with effective information sharing, leading to misunderstandings, misaligned goals, and a lack of synergy.
Moreover, coordination and decision-making become complex in large teams. Team members may lack a clear understanding of the overall project architecture, causing suboptimal design choices and integration problems. Lastly, accountability becomes elusive in large teams, making it difficult to trace responsibility for specific issues or failures.
Spotify has adopted a Squad model, wherein each squad is a self-contained, cross-functional team responsible for a specific area or feature.
By breaking down into smaller, cross-functional squads, development cycles become more focused and streamlined, allowing quicker software releases and updates. It also encourages innovation. Squads are granted autonomy, enabling them to experiment, adapt, and innovate independently.
Moreover, communication and knowledge-sharing within squads are highly efficient. With clear ownership and responsibility, squads eliminate silos and foster direct, productive collaboration. And the model is easy to scale. Squads are grouped into tribes, chapters, and guilds, ensuring that as Spotify grows, the organization remains agile and adaptable.
How to maximize team efficiency in software engineering?
- Clearly define the objectives and scope of the project to identify the specific roles and skills required for the development team.
- Select team members with complementary skills and expertise, ensuring diverse capabilities covering the necessary technical areas.
- Keep the team size small to promote effective communication, collaboration, and decision-making.
- Empower team members with autonomy and responsibility to make decisions and take ownership of their work.
- Implement agile methodologies and frameworks, such as Scrum or Kanban, to facilitate iterative development, adaptability, and continuous improvement.
#8. Working with a project mindset instead of a product mindset
A project mindset tends to focus on short-term goals and deliverables, often neglecting the long-term vision and sustainability of the software product. Without a clear product mindset, teams may prioritize quick wins or immediate deadlines over building a robust, scalable, and maintainable product. This can result in a software solution that lacks the necessary flexibility, extensibility, and adaptability to meet evolving user needs or market demands.
Nokia’s focus on individual projects rather than a holistic approach to product development hindered cohesive, long-term planning.
Nokia became entangled in a web of conflicting projects, diluting resources and diverting attention from core products. The lack of a unified vision resulted in fragmented efforts, with each project competing for resources. This internal discord hindered innovation and responsiveness to market changes.
The smartphone revolution highlighted these issues. While rivals swiftly adapted to evolving consumer preferences, Nokia lagged behind, clinging to outdated projects. As a result, Nokia failed to meet changing market demands and lost significant ground to more strategic, responsive competitors.
How to foster the product mindset in your organization?
- Clearly communicate the vision and goals of the product to the development team, ensuring everyone understands the purpose and value it aims to deliver.
- Encourage a customer-centric approach by emphasizing the importance of understanding user needs, pain points, and desired outcomes.
- Promote cross-functional collaboration and communication, breaking down silos and encouraging knowledge sharing between different roles and disciplines.
Prevent failures and build robust products with our expertise
Product engineering failures are rarely caused by one mistake. They compound through unclear ownership, weak quality gates, fragile architecture, and unmanaged change. The fix is disciplined engineering: clear requirements, scalable design, strong testing, visible reliability signals, and continuous improvement that prevents small issues from becoming systemic failures.
With Simform, you gain access to experienced project managers, skilled developers, and industry experts who employ best practices to develop reliable and scalable digital products. We prioritize thorough testing, continuous monitoring, and iterative improvements to address vulnerabilities and enhance product performance. Feel free to connect for a free tech consultation and get one step closer to building great software.
