Pixis: A codeless AI infrastructure to nitro-boost your marketing.
Category: AI-powered solutions
Services: DevOps, Cloud Architecture Design and Review, Managed Engineering Teams.

- 99.996% uptime
- 25% cost-reduce.
- 60+ production deploy/day
Problem statement
The client was facing various challenges with their infrastructure, including a lack of containerization, no standardized process for cost tracking and infrastructure management, no DevOps practices, and high costs. They wanted to develop a new infrastructure with continuous deployment and cost-effectiveness in mind.
Additionally, there were issues with scaling and background tasks, and some services still needed to be migrated to the new infrastructure. The overall goal was to improve the efficiency and cost-effectiveness of the client’s infrastructure while ensuring scalability and reliability.
Proposed solution
Simform’s team used AWS EKS for containerization and to simplify deployment, management, and scaling of services. With EKS, each product could have its own EKS cluster, which would be more cost-effective and easier to manage than cluttered infrastructure.
The Simform team has set up new infrastructure with infrastructure as code practice using terraform. We have implemented the DevOps and SDLC practices on infrastructure creation such as versioning,PR review, CI/CD etc for infrastructure code.
Simform used AWS EKS to optimize costs, as it offers more cost-effective management of infrastructure. We also used AWS S3 in the solution for storing static content, ML models, and data sets, and using tagging policies to monitor costs.
Simform proposed migrating all services to AWS EKS, including the legacy sync and SAAS Chrome extension services.
Simform proposed using AWS EKS to improve the scalability and reliability of the client’s infrastructure. Simform suggested que-based scaling solutions for background tasks and Redis for caching.
EKS managed nodegroups, k8s taints, and affinity can help ensure that each service only uses the necessary resources. For example, certain ML services require CPU and GPU-intensive machines only when generating recommendations or adding text to videos. To implement queue-based scaling on EKS, we suggested the client to use KEDA. When a new message is queued, a new pod will be launched, and the EKS cluster autoscaler will spin up and down nodes based on the number of queued messages.
Our team has set up a scalable and fault-tolerant api endpoint with the help of NLB and Nginx ingress controller. This ensured that the services could handle large workloads and traffic spikes without performance issues.
Our team has built a CI-CD pipeline for each microservice running on EKS cluster.
Finally, we set up monitoring and alerting logging using Grafana, Prometheus, and cloudwatch, which helped the team in monitoring and resolving issues proactively.
Key Metrics
- After migrating to AWS EKS and implementing Simform’s proposed cost optimization solutions, infrastructure costs have been reduced by 25%.
- Before migrating to AWS EKS, system uptime was 95%. After migrating to AWS EKS and implementing Simform’s proposed solutions, system uptime has reached 99.996%.
Architecture diagram
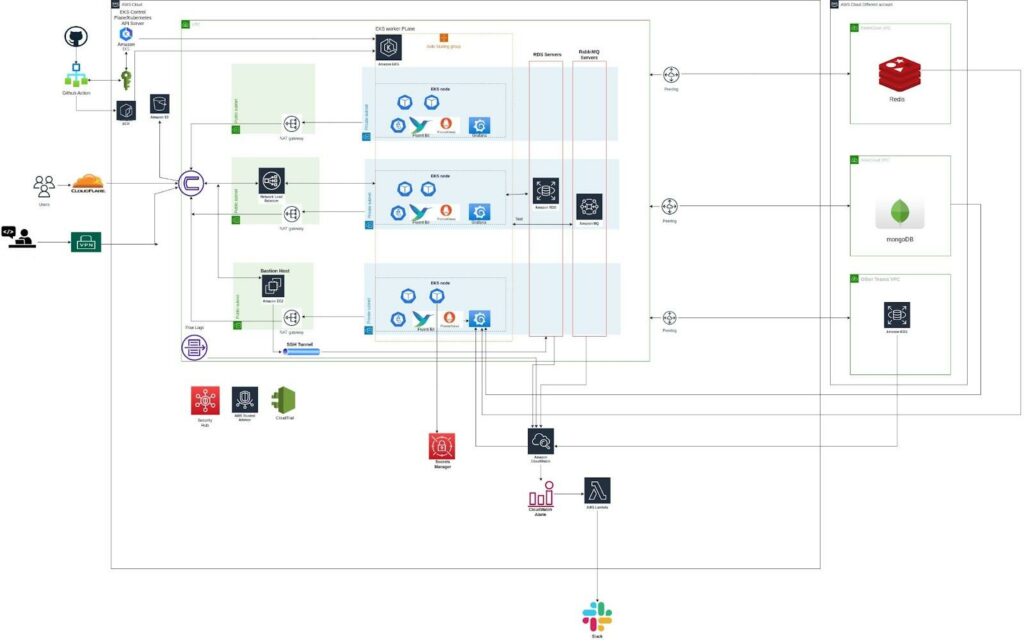
Services used
- Amazon RDS: We leveraged Amazon RDS as our primary storage solution for various types of data including campaign data, ad accounts, cross-platform engagement score, ML datasets, tenant data, and more. By using Amazon RDS, we were able to easily manage and scale our relational databases while ensuring high availability and durability.
- MQ: In our solution, we utilized MQ with RabbitMQ as a message broker to enable communication and coordination between our microservices. We configured it to handle long-running background tasks, such as processing recommendation data, image and video rendering, and other computationally intensive tasks, allowing for smoother and more efficient workflow management.
- AWS Trusted Advisor: In our solution, we are using Trusted Advisor to identify overprovisioned resources and improve our security posture. By regularly running Trusted Advisor checks, we are able to stay on top of potential issues and ensure that our infrastructure is optimized for performance, security, and cost.
- AWS CloudTrail: AWS CloudTrail enables auditing, security monitoring, and operational troubleshooting by tracking user activity and API usage. The AWS CloudTrail logs, continuously monitors, and retains account activity related to actions across our AWS infrastructure.
- AWS ECR: In our solution, we utilized AWS ECR to securely manage and scan the Docker images of our microservices. This helped us maintain the reliability and security of our system while ensuring the high performance of our services.
- NAT gateway: In our solution, we used NAT gateway to allow our resources in private subnets to securely access the internet and other AWS services, without exposing them directly to the public internet.
- AWS Lambda: We used AWS Lambda to trigger and run machine learning pipelines and alerts.
- Redis: We leveraged Redis to store user sessions, which allowed us to easily retrieve session data and provide a better user experience. Additionally, Redis helped us reduce data access latency by caching frequently accessed data in memory, which reduced the need for costly database queries.
- Amazon EKS: We leveraged Amazon EKS to easily manage and scale our microservices and background jobs on a containerized infrastructure. EKS provided us with a managed Kubernetes environment, allowing us to focus on application development and deployment without worrying about the underlying infrastructure. We used EKS to easily deploy, manage, and scale our containerized applications, and to automate container deployments and updates.
- Amazon CloudWatch: We used AWS cloudwatch to generate alarms and for application log generation and as a monitoring solution to monitor the resource utilization metrics.
- Amazon S3 buckets: We leveraged Amazon S3 buckets as a highly scalable and secure storage solution for storing various types of data in our system, including configuration files and customer data files. With S3’s ability to store and retrieve any amount of data from anywhere on the web, we were able to easily manage, secure, and retrieve files whenever required.
- AWS SecurityHub: We utilized Security Hub to get a comprehensive view of our security state in AWS and to ensure our environment adhered to security industry standards and best practices.
- AWS NLB: We utilized AWS NLB as our load balancer to distribute incoming traffic across multiple targets in different availability zones. This helped us achieve higher availability and fault tolerance for our application.
- AWS Cloudwatch alarm: In our solution, we set up CloudWatch alarms to monitor various metrics such as CPU utilization, memory usage, and network traffic for our AWS resources. Whenever a metric crossed a threshold, an alarm was triggered and sent notifications to our team via email or SMS.
- Amazon CloudWatch: In our solution, we used CloudWatch for logging and monitoring of various AWS native services such as Amazon RDS and Amazon MQ. We were able to set up customized metrics, dashboards, and alarms to monitor the health of our infrastructure and quickly respond to any issues.
- AWS secrets manager: In our solution, we used AWS Secrets Manager to store and manage the secret data of our microservices, including database credentials, API keys, and other sensitive information. This helped us keep our secrets secure and easily manage and retrieve them when needed.
- Fluent bit: We deployed Fluent Bit as our log processor and forwarder to collect, process, and forward logs from our microservices to AWS CloudWatch. This helped us gain real-time visibility into our application and infrastructure logs and make informed decisions based on the insights provided by the log data.
- Grafana: We used them for infrastructure and service monitoring. Using these tools, we help the client monitor various data points related to the infrastructure and applications, such as:
- Number of containers running
- ML pipeline status
- CPU percentage
- RAM usage at a cluster level
- Services running currently
- Node-level monitoring
- Network traffic
- Disk I/Os
Using these monitoring tools, Simform can proactively identify and resolve issues before they impact end-users, ensuring a high level of performance and availability for the client’s microservices-based architecture.