CIOs in all fields have a hard time getting control of the growing amount of data their organization works with. One of them is where to store all the information about their business so they can perform data analytics in the most efficient way possible.
Traditionally, there have been two ways to store data: data warehouses and data lakes.
Data warehouses store mostly transformed, structured data from operational and transactional systems. They are used for fast, complex queries across this historical data.
Data lakes store all kinds of data, including semi-structured and unstructured data, in a way that is similar to a dump. They make advanced analytics possible, like streaming analytics for processing live data or machine learning.
In the past, it was expensive to set up a data warehouse because you had to pay for both storage space and computing resources, as well as the skills to keep them running. As the cost of storage has gone down, so has the price of data warehouses. Some experts think that data lakes, which used to be a cheaper alternative, are now dead while some believe that data lakes are still cool. Others, meanwhile, are talking about data lakehouses, which are a new type of hybrid data storage solution.
This blog looks at the main differences between data warehouse vs data lake vs data lakehouse, as well as popular use cases of each storage type. It will help you choose the best storage technology for your business.
Different types of data to be stored
Before we get into the details of each storage solution, let’s quickly go over the kinds of data you may need to work with:
Structured data is information that has been sorted and made consistent. Names, dates, geolocation, phone numbers, and so on are all examples of structured data.
Unstructured data is data that is unorganized and has not been processed. It doesn’t have a clear structure and isn’t put together. This can include pictures, videos, and music.
Semi-structured data is a mix of both structured and unstructured data. Part of its framework is set. Unstructured data could be, for example, emails that have structured information about the date, time, sender, and recipient, but the body of the email could be anything, like pictures, videos, or text files.
What is a Data Warehouse?
A data warehouse is a large, centralized repository that stores data collected from various sources within an organization. It is designed to support business intelligence activities such as data mining, analysis, and reporting.
Data warehouses are typically used to integrate data from multiple sources and transform it into a format that is optimized for analysis. This allows organizations to perform complex queries and analyses on large volumes of data, and to gain insights that can help them make more informed business decisions.
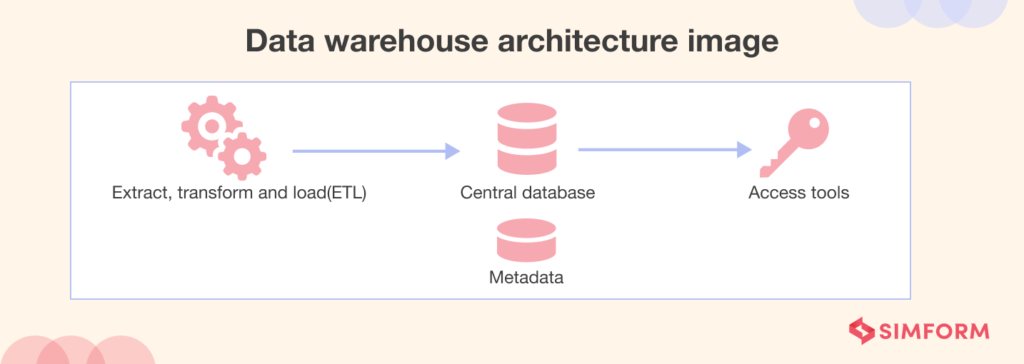
Data warehouses are only used for queries and analysis, and they often have a lot of data from the past. Most of the time, the data in a data warehouse comes from places like application log files and transaction applications. Data warehouses are made to store structured, curated data. Tables and columns are used to organize datasets. Users can easily access this data for business intelligence, dashboards, and reporting.
Pros and cons of data warehouses
It is important for organizations to understand both the benefits and drawbacks of data warehouses in order to make informed decisions. Let’s quickly look at the pros and cons of using data warehouses.
Pros
Timely business insights
A data warehouse analyzes data from various sources, providing valuable business intelligence.
Historical data analysis
In a data warehouse, the developers can compare new data to previously entered information, generating reports with historical insights.
Data standardization
Data standardization in a data warehouse makes it easier for researchers to navigate and work with large volumes of data from various heterogeneous sources.
Improved decision-making
By providing access to all of an organization’s data in one place, a data warehouse can help improve both strategic and tactical decision-making.
Increased efficiency
Data warehousing reduces the time employees spend gathering information and frees up time for analysis, leading to improved productivity.
Cons
Has compatibility issues
Data warehouses often have compatibility issues when combining different databases containing different measurements or titles for the same data type. In some cases, integrated data may not have all the required fields.
Not economical
Preparing data for data warehouses can be expensive. Additionally, the cost of maintaining a data warehouse increases as more historical data is added.
Poses some security risks
Data warehouses are a popular target for hackers, especially for research and commercial data. Ensuring the system’s reliability, resistance to attacks, and protection against information leaks is crucial. Access levels, data cleansing, and change implementation can further complicate security concerns.
Difficult to modify
Modifying a data warehouse can be difficult due to its rigid structure. Changes must go through a rigorous testing process to maintain data accuracy and integrity. Even minor modifications can impact the entire system, making changes time-consuming and resource-intensive.
Data warehouse tools
The following are some popular data warehouse tools.
Azure Synapse Analytics
Azure Synapse Analytics is a unified, cloud-native data platform that combines enterprise data warehousing with big data analytics. It supports both on-demand and provisioned query models, enabling organizations to process and analyze massive datasets efficiently.
With its integration of SQL and Spark engines, Synapse facilitates real-time analytics and machine learning workloads.
We’ve seen its impact firsthand. A leading global retailer needed to process over 50,000 orders per day. To meet this demand, they built a scalable ETL and analytics platform using Azure Synapse Analytics, Azure Data Factory, Azure Data Lake Storage Gen2, and Azure Databricks. The project was completed in just four to five months, enabling real-time operational insights—without the overhead of managing infrastructure.
How we built a transformative big data and analytics solution for school districts
Google BigQuery
Google BigQuery is a PaaS (Platform-As-A-Service) data warehousing solution that has built-in machine learning capabilities. It allows for scalable data analytics of petabytes of data. Google BigQuery supports features like automatic data transfer and is a perfect solution for businesses that want to run data mining or machine learning applications on their data.
Snowflake
Snowflake is a more flexible framework as compared to the other data warehousing tools available in the industry. It is also easy to use and offers a complete SaaS (Software as a Service) architecture. Snowflake users can conduct data analysis with structured as well as semi-structured data sets using a single language SQL.
Amazon Redshift
Amazon Redshift is a fully managed cloud data warehouse that can store and analyze petabytes of data using SQL. It’s ideal for businesses that need fast, complex queries and sophisticated analytical capabilities.
Data warehouse use cases
A data warehouse has long been the go-to solution for business intelligence and operational reporting, especially when the data is well-defined and historical trends matter.
While newer architectures offer more flexibility, data warehouses remain essential for high-performance analytics on curated, structured datasets. Here are a few situations where they provide clear advantages:
BI queries
Data warehouses are mostly made for business intelligence (BI) queries. A data warehouse could tell you, for example, how sales have changed from one year to the next and how they have changed over a certain time period.
Performance and query optimization
A data warehouse is designed to enable quick and effective data access, making it ideal for use cases requiring high performance and query optimization. For instance, a company may employ a data warehouse to enable real-time data dashboards and reporting, where quick and efficient data access is crucial.
Security and compliance
For use cases where security and compliance are top priorities, a data warehouse can offer a secure and compliant environment for storing sensitive data. To guarantee that consumer data is secure and conforms with privacy laws, a company can, for instance, utilize a data warehouse to store and analyze client data, such as financial information and personal details.
For example, finance and banking institutions deal with a lot of sensitive information like customer transactions and personal details that must be kept secure. In such cases, a data warehouse can provide a secure and compliant environment for storing and analyzing such data.
These are just a few situations where a data warehouse may be a better choice than a data lake or a data lakehouse. The specific use case will depend on the organization’s goals and the kind of data being stored and analyzed.
The next type of data storage we’ll talk about is the data lake. Note that data lakes and data warehouses are often used together in a company’s data infrastructure. Each is used for the needs that match its strengths best. Some use cases may even start with looking at unstructured data in a lake, which is then moved into a data warehouse so that it can be queried better.
What is a Data Lake?
Data lakes emerged as a solution to address the disadvantages of a data warehouse. Unlike data warehouses, data lakes can process all data types, including unstructured data like images and documents, which is essential for advanced analytics and machine learning use cases.
In simple words, a data lake is a centralized data repository that enables the storage of both structured and unstructured data of any scale. The data can be stored in its raw form without the need for prior structuring and can be analyzed using various methods, such as visualization tools, big data processing, real-time analytics, and machine learning algorithms. This facilitates informed decision-making based on the insights gleaned from the stored data.
Data lakes collect information from a wide variety of unstructured sources, including
- Transactional data from business applications like ERP, CRM, or SCM
- Semi-structured data like XML, JSON, and AVRO formats
- Multimedia files like images, audios, binary, PDFs
- Device logs and IoT sensors
Data lake architecture
There are five steps in a typical data lake architecture: “ingest,” “store,” “analyze,” “surface,” and “act.”
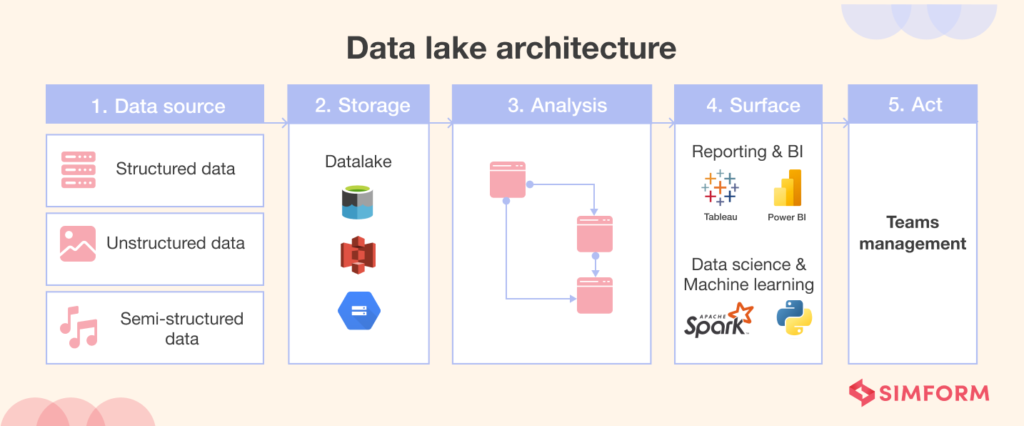
Ingest
Ingest refers to the process of transferring data through APIs or in batches. ETL solutions are used by data engineering teams to collect and take in data.
Store
Storage is the act of putting both structured and unstructured data in one place. Amazon S3, Google Cloud Storage, and Azure Data Lake are some of the tools that are often used to store data.
Analysis
During this step, the data is processed and looked at to see if there are any connections.
Surface
Surface means putting the insights into charts, graphs, and diagrams that are easy to understand using BI tools.
Make sure that your data lake doesn’t turn into a data swamp. For this, it’s important to have an effective data management strategy. Your strategy should integrate data governance and metadata management into the design of the data lake.
Data lakes: pros and cons
Data lakes are a popular storage solution for organizations, but like any technology, they have both advantages and disadvantages. Let’s take a brief look at the pros and cons of a data lake.
Pros
Data consolidation
Data consolidation is a major benefit of data lakes when we compare data lakes vs. data warehouses. Both structured and unstructured data can be stored in data lakes, so you don’t have to store both types of data in different places.
Flexibility with data
One of the best things about data lakes is how flexible they are. You can store data in any format or medium, and you don’t need to have a set schema. If you let the data stay in its original format, you can analyze more data and use the data in more ways in the future.
Advanced analytics support
Data lakes provide support for complex algorithms such as deep learning, allowing organizations to recognize patterns of interest. They generate different types of insights including machine learning, historical reporting, and more. Your team can have different roles to access data using your choice of analytic tools and frameworks without having to move the data to a separate analytics system.
Cost savings
Data lakes are cheaper than traditional data warehouses because they are designed to be stored on low-cost commodity hardware like object storage, which is usually optimized for a lower cost per GB stored. For example, Amazon S3 standard object storage costs $0.023 per GB for the first 50 TB per month, which is a crazy low price.
Cons
Difficult to use in BI use cases
If data lakes are not properly managed, they can become disorganized, making it hard to connect them with business intelligence and analytics tools. This happens to be a major con of data lakes in the data lake vs. data warehouse debate. Also, if there isn’t consistent data structure and ACID (atomicity, consistency, isolation, and durability), transactional support, reporting, and analytics use cases might not get the best query performance.
Hard to ensure robust data security
Since data lakes can store any type of data, it might be hard to set up the right data security and governance policies for sensitive data.
Data lake tools
The following is a list of some popular data lake tools and technologies:
Azure Data Lake Storage Gen2
Azure Data Lake Storage Gen2 is Microsoft’s end‑to‑end data lake platform, combining petabyte‑scale performance with flexible folder hierarchies and automated tiering to keep costs in check.
It integrates natively with Power BI and Azure Synapse and has built‑in security and compliance (HIPAA, ISO, GDPR) for enterprise analytics workflows.
Amazon S3
Amazon S3 is a popular object-based storage service from AWS. It is a suitable tool for storing unstructured data that is likely to remain constant over time. S3 offers unified data access, security, and governance to comply with regulatory requirements. The best part? AWS lake formation allows organizations to get started with secure S3 data lakes in a just few days!
Amazon S3 is an important storage tool in data engineering. Know more about the entire data engineering pipeline and how billion-dollar companies like Samsung and Netflix use such pipelines in our free ebook.
How Billion-Dollar Companies Leverage AWS Data Engineering Tools
Databricks Delta Lake
Delta Lake is an open-format storage layer by Databricks that provides a reliable, secure, and high-performance single storage area for structured, semi-structured, and unstructured data. It offers automated and scalable data engineering, flexible and transparent data sharing, and enhanced security and governance. Delta Lake is powered by Apache Spark and is a cost-effective solution.
Data lake use cases
The following are the major use cases for data lakes.
Handling large amounts of diverse data
Data lakes is a great solution for applications that deal with a lot of data, such as in the oil and gas industry or in smart city initiatives, where large amounts of diverse data from different sources and formats need to be managed and leveraged.
Finding matching records
Combining records from different data sources is a common challenge in data management, and using a common identifier, such as a social security number or address, provides a way to link the two data sets together. You can easily combine the streams by zipping them together. Fuzzy matching methods can also prove useful if the two data sets only somewhat match, allowing you to create consumer profiles from multiple sources of information, including point-of-sales records, credit card transactions, account signups, and social media posts.
Data access control
Data lakes are useful in access control use cases. For instance, you can build data lakes to give different groups of people different levels of access to the data without making copies of it. AWS Lake Formation is a tool that adds an extra layer of security that makes it easy to control who has permission to access what. A lake administrator, for example, can “see everything,” but a data analyst may not be able to see personally identifiable information (PII) about customers.
Organizing and searching for data
Data lakes are helpful in situations when a large amount of information needs to be stored in a unified, searchable format. Data in data lakes can be retrieved using a search interface that allows for the insertion of keywords.
In order to manage and leverage all of their data streams, businesses with hundreds or thousands of data sources need a repository. All of a data lake’s metadata, such as table definitions and database names, is stored in its data catalog. Metadata in the form of tags can be effectively applied to tables and even individual columns inside tables. This makes it easy to search and retrieve relevant data quickly.
Data lakes and data warehouses are commonly implemented together since they serve various but complementary purposes for businesses. So then, why did the need for data lakehouses arise? Let’s find out in the following sections!
What is a Data LakeHouse?
A data lakehouse is a hybrid data management architecture that combines the benefits of both data lakes and data warehouses. It allows for the storage of both structured and unstructured data in its raw form, like a data lake, but also supports the creation of schema-on-read and schema-on-write structures, like a data warehouse. This enables organizations to perform traditional business intelligence (BI) tasks, such as querying and reporting, alongside more advanced analytics tasks, such as machine learning and deep learning, using a unified data management system.
Data Lakehouses: a new hybrid architecture
Typically a data lakehouse architecture consists of the following layers
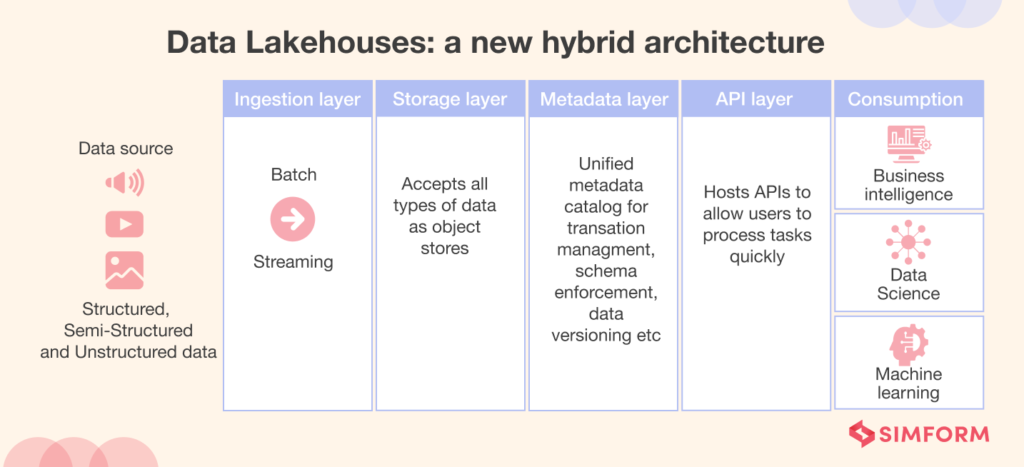
Ingestion Layer
The ingestion layer takes data from various sources using a variety of protocols and methods. It is capable of handling a variety of data kinds, including structured, semi-structured, and unstructured data. The layer may draw in data in real-time or in batches, thus providing you with a flexible solution for information collection.
Storage layer
The storage layer is responsible for cost-effectively storing enormous quantities of data. It supports organized, semi-structured, and unstructured data and has an open file format similar to Parquet. This layer is readily applicable to machine learning and artificial intelligence models, making it a useful asset for data-driven enterprises.
Metadata layer
The metadata layer equips the data lakehouse design with characteristics typical of contemporary data warehouses. It serves as a centralized catalog of metadata for all storage layer objects. This metadata supports multiple functionalities, such as ACID transactions, schema governance and enforcement, indexing, caching, time travel, and access control, which provide data integrity, consistency, reliability, quality, security, and historical data retrieval.
API layer
The API layer enables many data engineering tools and processes with efficient and rapid data access. The data is in an open format, providing advanced analytical software and applications immediate access. This layer is essential for firms that rely on machine learning, artificial intelligence, and other sophisticated analytics.
Consumption layer
The consumption layer permits business intelligence applications such as Power BI and Tableau to access data, as well as SQL queries and machine learning tasks. This layer is essential for organizations that must derive insights from their data in order to make strategic decisions.
Data Lakehouse: pros and cons
As a relatively new hybrid data management architecture, data lakehouses offer several advantages over traditional data management systems, but also present certain challenges and drawbacks that should be carefully considered. Let’s take a brief look at the various pros and cons of a data lakehouse.
Pros
Reduced data duplication
Data duplication is a serious issue in data storage. It happens when the same data is stored more than once in different places. Naturally, duplication can lead to inconsistencies in data. These differences lead to problems like higher storage costs and more trouble managing and getting to the data.
Data lakehouses offer a single platform for storing data that can be used for many different things and put all the data in one place. In this way, a data lakehouse can help reduce the data duplication issue.
High data reliability
As all data is stored in a single location, it is simple to maintain a high level of data consistency in a data lakehouse. High data consistency ensures the accuracy of the data utilized for analytics.
Openness
Data lakehouses permit access to data via any tool, as opposed to being restricted to applications that can only manage structured data, such as SQL.
Better data management
A data lakehouse eliminates the need to manage several copies of identical data. As all data is stored in a single area, it is far simpler to access and manage this data.
Low expenses for storage
As data lakehouses aid in decreasing data duplication, storage expenses are reduced. How? As data duplication is reduced, it becomes unnecessary to retain numerous copies of identical data, resulting in less storage space being utilized. In addition, data lakehouses implement the cost-effective storage characteristics of data lakes by employing low-cost object storage solutions.
Easy data administration
Data lakehouses reinforce data integrity by applying improved data security schemas, making it simpler for enterprises to manage and safeguard their data. This includes the implementation of access controls, data encryption, and data backup and recovery procedures, among others. By guaranteeing data integrity, data lakehouses instill greater confidence in an organization’s data and the insights derived from it.
Data lakehouses also offer enhanced data governance with features such as metadata management, data cataloging, and data lineage tracing, among others. These qualities make it easier for businesses to comprehend the data they own, its origin, its processing, and who has access to it.
Cons
A relatively underdeveloped concept
The idea of a “lakehouse” for data is still in its early stages. Data lakehouses can’t be managed well because there aren’t enough mature tools and technologies. This can lead to a lot of manual work and make it hard to grow the data lakehouse for it to handle more data.
There is also a lack of industry expertise and best practices when it comes to designing and putting data lakehouses into action. This can lead to bad performance and a less-than-optimal use of resources.
High complexity
Data lakehouses can be harder to design, set up, and keep up than separate architectures for data lakes and data warehouses. This is because they need to support both the flexible, unstructured data storage of a data lake and the structured, organized data storage of a data warehouse.
Vendor lock-in
Some data lakehouses are tied to specific vendor ecosystems, which can make it harder for an organization to choose the best tools and technologies for its needs. A vendor lock-in also means difficulty switching to a different architecture in the future.
Data Lakehouse tools
Databricks Lakehouse Platform
Databricks Lakehouse Platform is a reliable and scalable platform for managing data pipelines, data lakes, and data platforms. It includes a collaborative Data Science Workspace for practitioners to run analytic processes and manage ML models.
Starburst Data Lakehouse
Starburst’s data lakehouse analytics engine, based on open-source Trino, enables fast and interactive queries on data lakes with high concurrency, scalability, and performance. Its cloud-native and fully managed Starburst Galaxy offers unified table formats in popular data lakes and allows running interactive and ELT workloads in one query engine, increasing productivity and lowering costs.
Use cases of Data Lakehouse
Augment data lake’s capabilities
When you already utilize a data lake but want to add SQL performance capabilities to it while saving money on the cost of creating and maintaining a two-tier architecture with warehouses, you should consider data lakehouse use cases.
Improve data compliance with low-cost
Choose a data lakehouse when you want to improve data security, dependability, and compliance, and you still want to maintain large amounts of data in low-cost lake storage.
Hybrid data analytics
Because it can process both structured and unstructured data, a data lakehouse is an excellent choice for hybrid data analytics.
Real-time data analytics
As it is possible to store and handle massive amounts of data in real-time using a data lakehouse, this architecture is ideally suited for use cases that call for real-time analytics.
Data Lake vs. Data Warehouse vs. Data Lakehouse: A comparative analysis
| Parameters | Data Lake | Data Warehouse | Data Lakehouse |
| Type of Data | Unstructured and Structured | Structured | Unstructured and Structured |
| Data Quality | Raw data | Highly curated data | Raw and curated data |
| ACID Compliance | No | yes | yes |
| Storage | cost-effective and flexible. | costly and time-consuming. | cost-effective and flexible. |
| Schema | a schema-on-read strategy. | a schema-on-write approach. | A data lakehouse can accommodate both techniques |
| Use cases | Data exploration, machine learning, and big data analytics are the use cases that are supported by the data lake. | The three most common applications for data warehouses are business intelligence, reporting, and analytics. | Data science, machine learning, real-time analytics, and business intelligence are the most common use cases that are supported by the data lakehouse. |
| Data Governance | A data lake offers very few options for data governance methods. | It’s possible for a data warehouse to have data governance and compliance controls integrated right in. | Controls for data governance and compliance are already incorporated into a data lakehouse. |
| Cost | The cost of storing data in a data lake is relatively low, but the expenses of processing and analysis could be rather significant. | The expenses of processing and analysis are less when you are using a data warehouse, but the storage costs are higher. | The storage and processing capabilities of a data lakehouse are efficient and economical. |
| Scalability | Due to its numerous storage possibilities, a data lake is a highly scalable type of data storage option. | A data warehouse may not be as scalable as a data lake because data in a data warehouse has to be pre-grouped and has other limitations. | Because of its adaptable processing and storage choices, a data lakehouse is a highly scalable alternative for storing information. |
| Integration with other tools | For the purposes of data transformation, data processing, and data analysis, a data lake might require some extra tools. | Integration of a data warehouse with other BI tools for the purposes of analysis and reporting is common practice. | It’s possible that a data lakehouse may need additional tools for data translation, processing, and analysis, but it can also integrate with BI tools for usage in analysis and reporting. |
What factors should you consider when choosing between a data warehouse, data lake, or data lakehouse solution?
There are important factors to think about when deciding between a data warehouse, data lake, or data lakehouse.
The main distinctions between a data warehouse, a lake, and a lakehouse are not technical but rather conceptual. They’re designed to meet various requirements in the commercial world.
The question then becomes why you require a data storage solution in the first place. Is it for use in data science, business intelligence, real-time analysis, or routine reporting? Which, in terms of your company’s demands, is more important: timely data or consistent data?
Use case development requires time. You should have a clear idea of what you need from analytics. It’s important to have an in-depth familiarity with your target audience and their respective skill sets.
Here are some general guidelines you can follow:
- Choose a data warehouse if you have a clear idea about the analytics results you want to get regularly.
- If you are in a highly regulated industry like healthcare or insurance, a data warehouse will be a better choice.
- If you require simple historical analysis, go with a data warehouse.
- If your data team is after experimental and exploratory analysis, choose a data lake or a data lakehouse solution. However, you’ll need a team that has strong data analytics skills that can assess unstructured data.
- If your organization wants to leverage machine learning technology, a data lakehouse or data lake will be a natural fit.
Choosing the right data storage solution with Simform
The architectures for the storage of data are still developing. It is not feasible to predict with absolute certainty how things will progress. Nevertheless, regardless of which way you decide to go, it is beneficial to be aware of the typical benefits and dangers of choosing the storage technologies available to you.
We sincerely hope this post has helped clarify any confusion that you may have had regarding data warehouse, data lake, and data lakehouse consulting. Send us a message if you have any remaining queries, require top-tier technical skills or guidance, or want to design your own data storage solution. Our team will be more than happy to assist you!
