Capital One, a reputed financial institution in the US, has adopted cloud-native microservice architecture. They employed docker containers with Amazon Elastic Container Service (ECS) for advanced microservice deployments. Containerization microservice best practices helped them decouple apps.
They were, however, confronted with challenges such as,
-
Multi-port routing for the same server
-
Context-based routing of services
Such difficulties could be met with tools like Nginx and Consul, but they would add to the complexities and operating expenses. As a result, they chose AWS elastic load balancing, which helped them with,
-
Dynamic port mapping
-
Automatic registration or de-registration of docker containers
-
Path-based routing for contextual service allocations
One of the most important lessons to take away from Capital One is how great results can be achieved with very little work. The Pareto principle, also known as the 80/20 rule, supports this.
In this article, we’ll go through 14 microservices best practices that help you drive great results with relatively less input.
Benefits of a microservice architecture
The compelling benefits of microservices have convinced business giants like Netflix, Amazon, and eBay to fully embrace this architecture. Microservices, as opposed to more typical monolithic design frameworks, provide numerous major advantages, including:
1. Enhanced fault isolation
A single component failure in a monolithic design can destroy the entire system. In contrast, because each microservice functions separately, it is less likely to influence other application sections if one service fails in a microservice design.
Tools like GitLab and others can help you create fault-tolerant microservices and improve overall infrastructure resilience.
2. Improved modularity
Microservices provide an enhanced level of modularity, presenting a significant advantage for organizations requiring rapid application modifications.
Breaking down an application into smaller components enables implementing changes quickly and with lower risk. Additionally, the self-contained nature of microservices makes it easier to understand their functionality and integrate them into a large application.
3. Enhanced scalability
Microservices outperform monolithic systems in terms of scalability. Unlike monoliths, which may struggle when traffic spikes, microservices assign dedicated resources to each service, thus averting widespread disruptions.
Moreover, tools like Kubernetes efficiently manage resources, leading to cost reductions. Furthermore, microservices simplify the update process, making them an excellent choice for rapidly growing companies.
4. Tech stack versatility
In microservices, each module functions as a miniature application, allowing crafting it using a tailored blend of technologies, frameworks, and programming languages.
This tech-agnostic approach empowers teams to select the best-fitting stack for each component, avoiding unnecessary compromises due to tech conflicts or outdated stacks.
5. More efficient testing
Microservices make testing efficient by allowing individual component testing. This modular approach streamlines bug detection and resolution while minimizing the chances of one service affecting others, resulting in smoother system maintenance and updates.
Plus, microservices support concurrent testing, enabling multiple teams to work on various services simultaneously. This speeds up testing, enhances efficiency, and contributes to developing more resilient and dependable software systems.
6. Compatible with Docker, Kubernetes, and cloud services
Docker and Kubernetes are pivotal in orchestrating containers, delivering robust, high availability and scalability. These technologies also provide seamless load balancing across various hosts, making them indispensable tools in the Microservices architecture toolkit.
Cloud providers like Elastic Container Services offer self-managed services in the contemporary landscape. These services are designed to achieve fault tolerance, high availability, and load balancing, further enhancing the capabilities of Microservices architecture.
Major cloud providers like AWS, Google Cloud, and Azure offer orchestration solutions to bolster your infrastructure.
14 Microservice best practices for your projects
The 80/20 rule is about focusing on the important things while ignoring everything else. The same may be applied to microservices deployments, which we’ll discuss further.
1. Improve productivity with Domain-Driven Design(DDD)
Microservices, ideally, should be designed around business capabilities using DDD. It enables high-level functionality coherence and provides loosely coupled services.
There are two phases to every DDD model: strategic and tactical. The strategic phase ensures that design architecture encapsulates business capabilities. Conversely, the tactical phase allows creating a domain model using different design patterns.
Entities, aggregates, and domain services are some of the design patterns that might help you design loosely coupled microservices.
Learn how SoundCloud reduced release cycle time with DDD.
SoundCloud’s service architecture followed the Backend for frontend(BFF) pattern. There were, however, complications and concerns with duplicate codes. Furthermore, they used the BFF pattern for the business and authorization logic in the BFF pattern, which was risky.
As a result, they decided to use a Domain-driven design pattern and develop a new approach known as “Value Added Services (VAS).”
There are three service tiers in VAS. The first is the Edge layer, which functions as an API gateway. The value-added layer is the second, which processes data from different services to provide a rich user experience. Lastly, the third layer is the “Foundation,” which provides the domain’s building blocks.
Within the DDD pattern, SoundCloud employs VAS as an aggregate. VAS also enables the separation of concerns and provides a centralized orchestration. It can execute authorization and orchestrate calls to associated services for metadata synthesis.
Using the VAS approach, SoundCloud managed to decrease release cycles while improving team autonomy.
How is microservice architecture making a difference in various business sectors?
2. Have quicker responses with the Single Responsibility Principle (SRP)
SRP is a microservice design principle wherein each module or class must do one thing assigned well enough for enhanced functionality. Each service or function has its business logic specific to the task.
One of the major benefits of SRP is reduced dependencies. There is no overhead on any service because each function is designed to perform specific tasks. It also reduces the response time by eliminating the need for a service to wait for support services to execute before responding to a user request.
Example of how Gojek achieved higher reliability and lower response time using SRP
Gojekis an on-demand marketplace that connects motorcycle drivers and riders. One distinct feature is a chat capability that allows users to engage with drivers via the “Icebreaker” application.
The Icebreaker’s heavy reliance on services to build a communication channel between users and drivers was a hurdle for Gojek. To create a channel, for example, the icebreaker will need to perform tasks like,
- Authorize API calls
- Fetch customer’s profile
- Fetch driver’s details
- Verify whether the customer-driver profile matches the active order details
- Create a communication channel
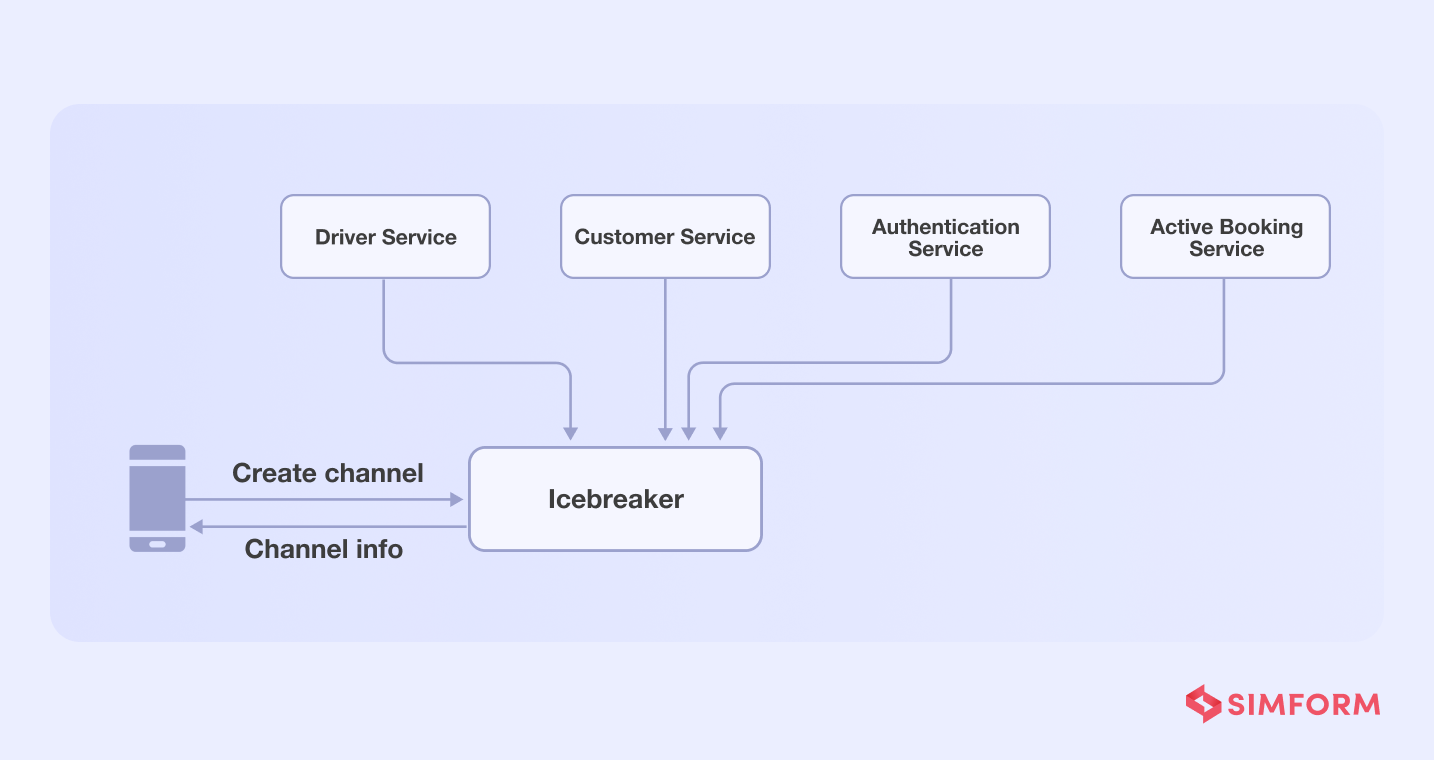
The problem with dependency on several functions/services is that if one of them fails, the entire chat function will fail.
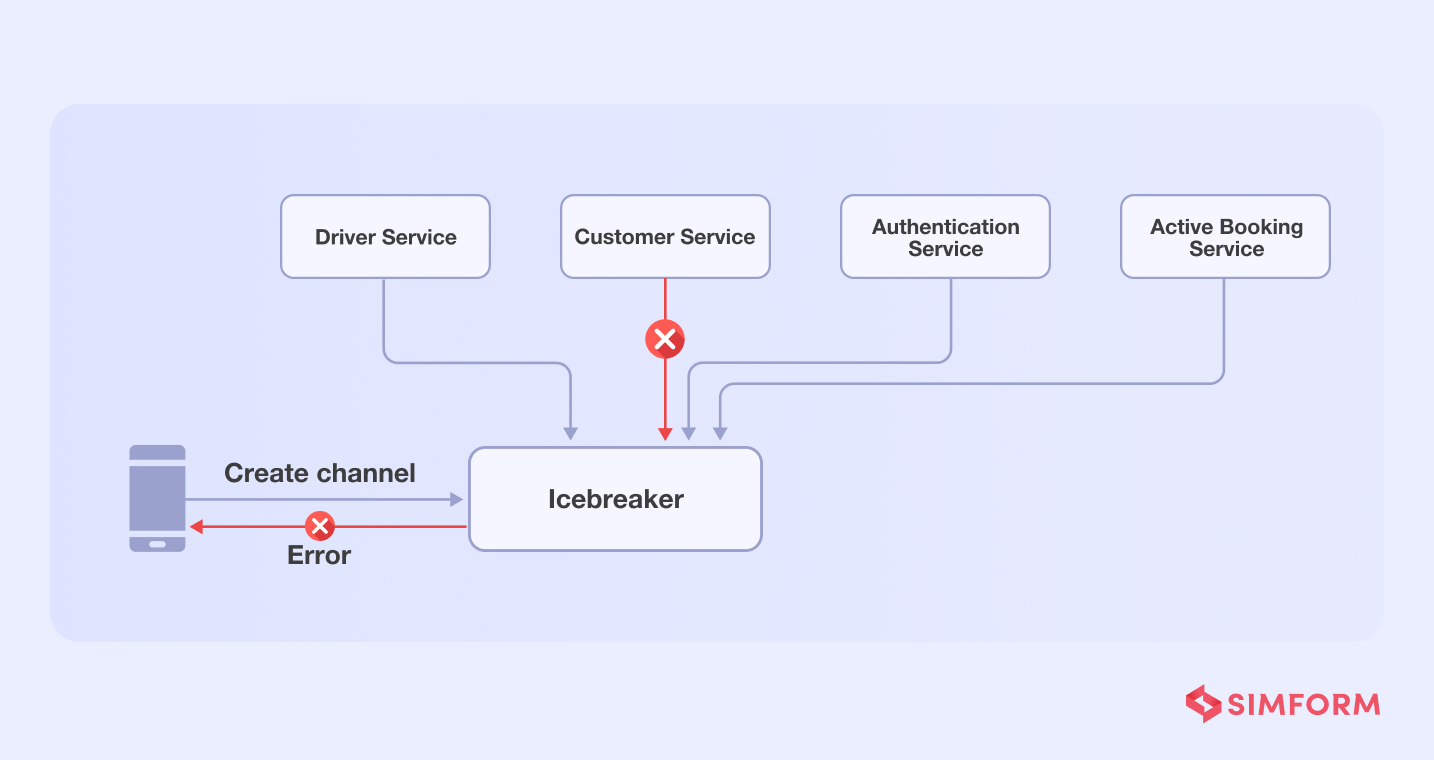
Gojek teams applied the single responsibility principle to addd services for each function, assigning tasks to each and reducing the load on a single service.
-
API call function- They added Kong API gateway for authentication functionality
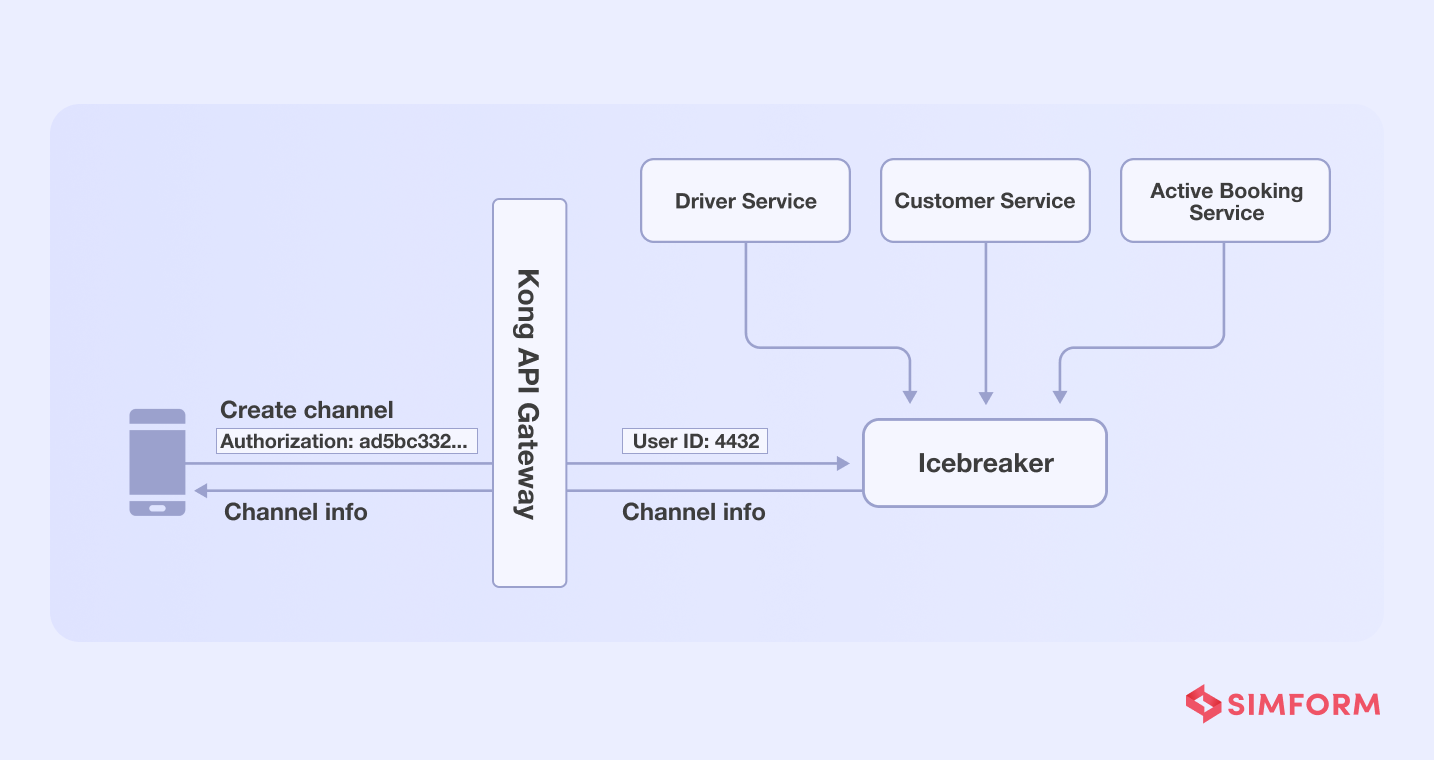
- Profile retrieval-Icebreaker needed chat tokens from driver’s and user’s data stored in separate databases, which were then stored in the Icebreaker’s data store. As a result, there was no need to perform any further retrieval in order to create the channel.
- Active booking- Icebreaker needed to verify whether an active booking had already been made when a user hits the channel creation API. The Gojek team used the worker-server approach to reduce this dependency.
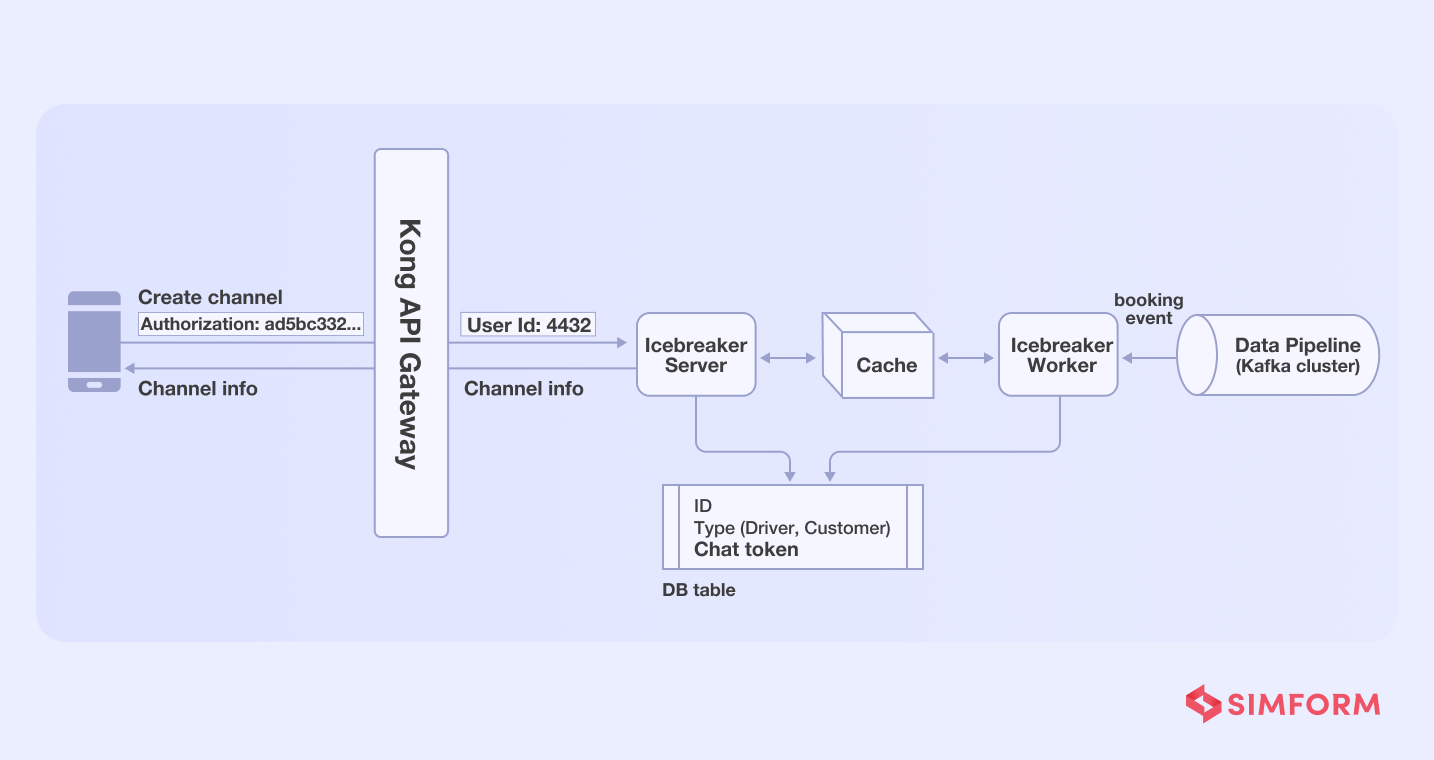
So, each time an order is placed, a worker creates a communication channel and stores it in the Redis cache, which a server pushes as per need each time a user hits the channel API.
As a result, Gojek reduced its response time by 95% with the single principle responsibility approach.
3. Enable service autonomy with independent microservices
Independent microservice is a practice of taking the service isolation to a step further. Through independent microservice practices, three forms of independence can be obtained.
- Independent service evolution is a process of isolating feature development based on the need for evolution.
- Independent testing is a process of conducting tests that prioritize and focuses on the service evolution. This decreases the number of test failures caused by service dependencies.
- Independent deployment reduces the chances of downtime due to service upgrades.. It is beneficial, especially if you have a cyclic dependency during the app’s deployment.
Amazon’s single-purpose functions and independent microservices’ management issues
Back in 2001, developers at Amazon found it difficult to maintain a deployment pipeline with a monolithic architecture. So, they chose to migrate to a microservice architecture, but the real challenge began after the migration.
Amazon teams pulled single-purpose units and wrapped them with a web interface. It was undoubtedly an efficient solution, but the difficulty in managing several single-purpose functions was the issue.
Merging the services them week after week for deployment became a massive challenge as the services increased. Hence, development teams at Amazon built “Apollo,” an automated deployment system based on the decoupled services.
Further, they established a rule that all-purpose functions must communicate through a web interface API. They defined a set of decoupling rules that every function needs to follow.
Lastly, they had to deal with manual handoffs, which resulted in “deadtime.” Eventually, the deployment pipeline sequence was discovered to reduce manual handoffs for improved efficiency of the entire system.
4. Embrace parallelism with asynchronous communications
Without proper communication between services, the performance of your microservices can suffer severely. There are two communication protocols popularly used for microservices,
- Synchronous communication is a blocking-type communication protocol where microservices form a chain of requests. Though it has a single point of failure and it lags in performance due to higher dependency and
- Asynchronous communication is a non-blocking protocol that follows event-driven architecture. It allows parallel execution of requests and provides better resilience.
The asynchronous communication protocol is the better option for enhanced communication between microservices. It reduces the coupling between services during the execution of user requests.
How Flywheel Sports powered real-time broadcast with enhanced microservice communication?
Flywheel Sports was launching “FlyAnywhere,” a platform for their fitness community that enhanced the bike riding experience through real-time broadcast. Flywheel’s engineers built the platform using a modular approach and microservice architecture.
It did, however, have communication challenges, which resulted in network failures and system availability issues. To solve these issues, they created a checklist of features like,
- Service discovery
- Messaging
- Queuing
- Logging
- Load balancing
They built “Hydra,” an internal library that supports the above features and Redis clusters. They tied each microservice to a shared Redis cluster and used pub/sub (asynchronous communications) to maintain inter-process communication.
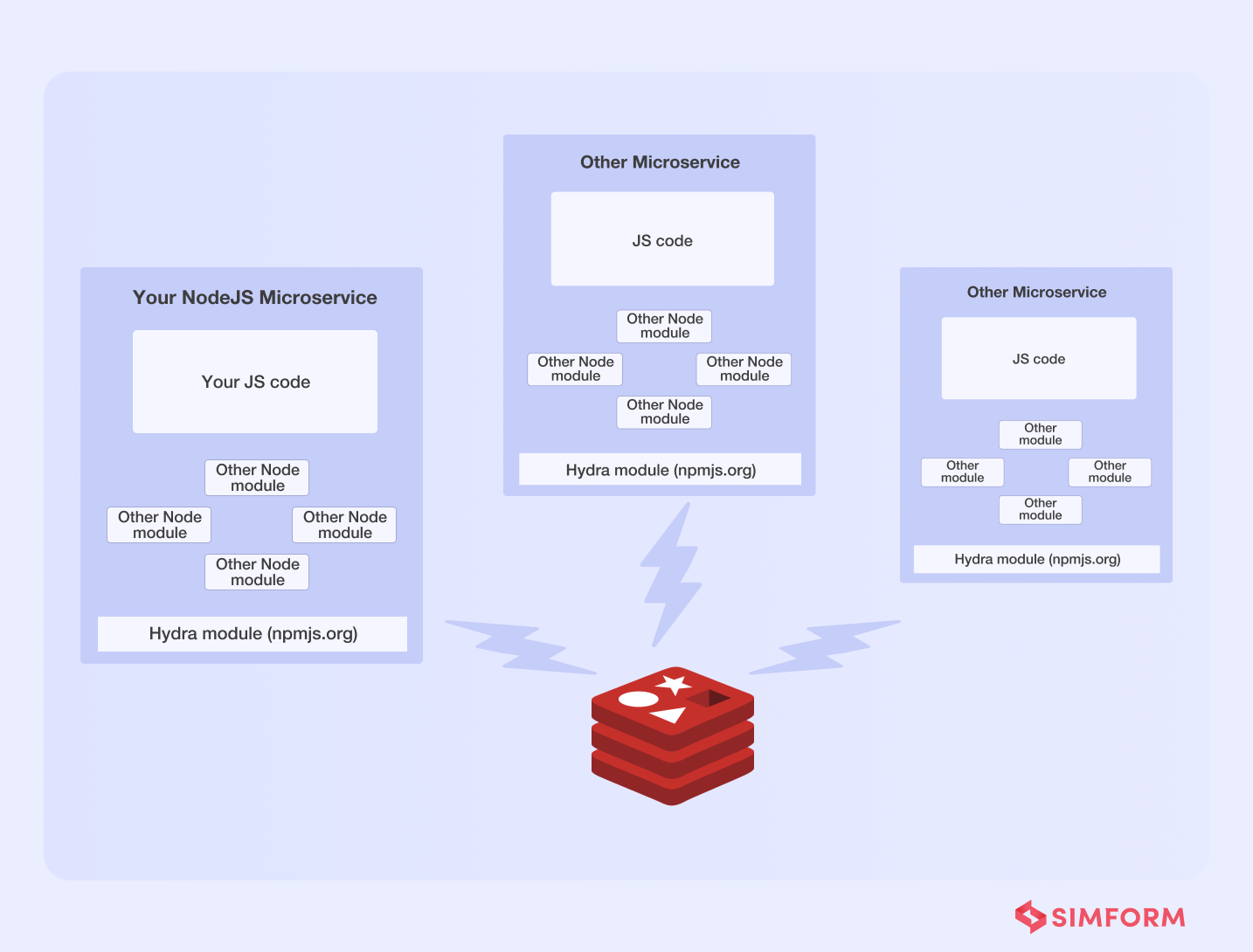
Not just that, Hydra also assisted them in mitigating the single dependency issues of microservices by enabling features like,
- Inter-service communication
- Service discovery
- Load balancing and routing
- Self-registration of services with zero configuration
- Job queues
Overall, we can conclude that asynchronous communication assisted Flywheel in establishing a solid foundation for providing real-time broadcasts to its FlyAnywhere consumers via Hydra.
5. Separate microservice database to reduce latency
Although microservices are loosely coupled, they all require to retrieve data from the same datastore with a shared database. In such instances, the database must deal with multiple data queries and latency issues. The solution might be a distributed database for microservices, with each service having a data store of its own can be the answer.
A separate microservice database allows services to store the data locally in a cache. Latency is reduced as a result of this. Because there is no single point of failure with a distinct data store, security and resilience are also improved.
Twitter’s ability to process millions of QPS was improved through a dedicated microservice datastore.
Twitter migrated from a monolithic software architecture to a microservices architecture in 2012. It utilized multiple services, including Redis and Cassandra, to handle about 600 requests per second. However, as the platform scaled, it needed a scalable, resilient database solution to handle more queries per second.
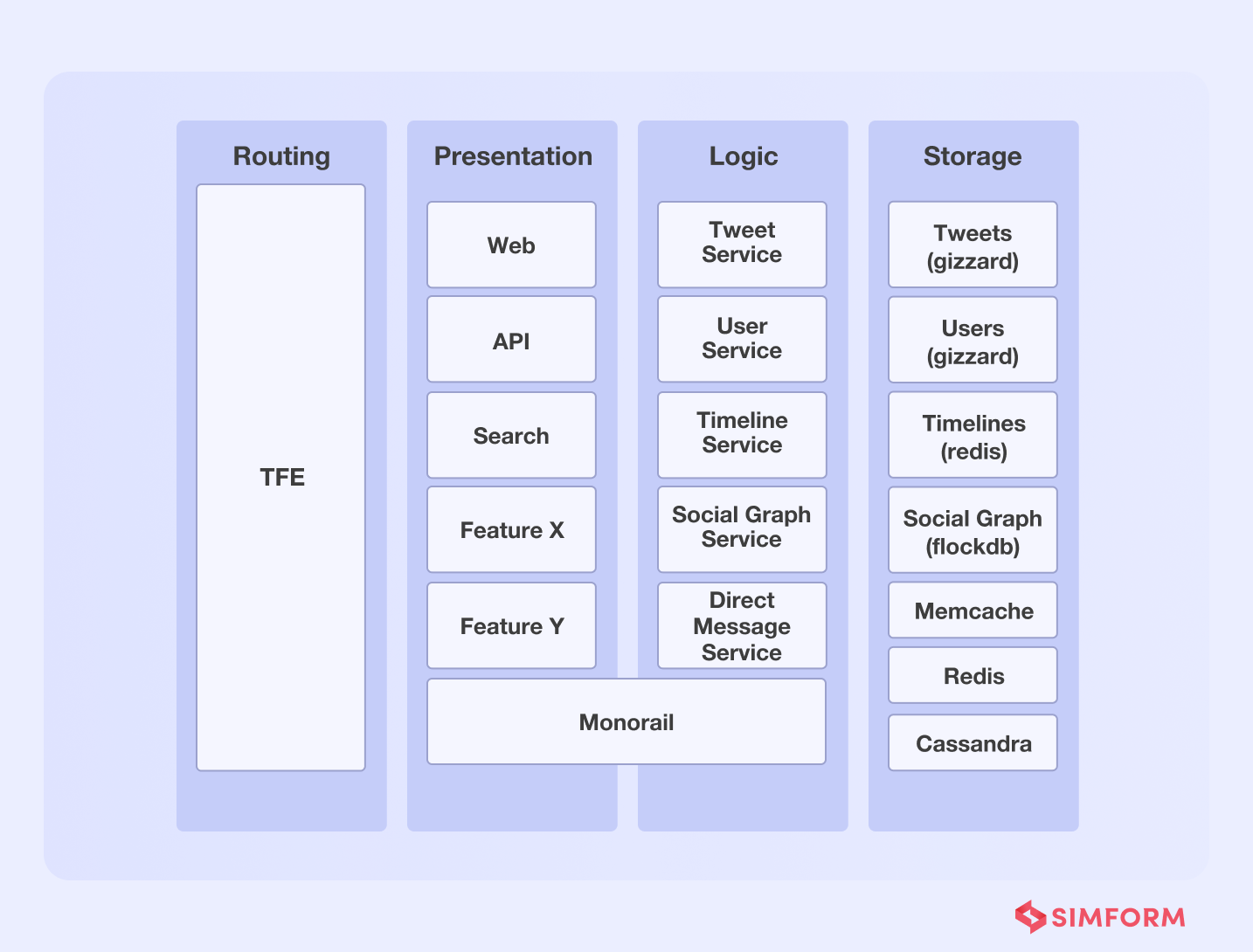
Initially, Twitter was built on MySQL and moved from a small database instance to a large one. This led to the creation of large database clusters, because of which moving data across instances was time-consuming.
As a solution to this problem, Twitter incorporated several changes. One is the introduction of Gizzard, a framework that helped them create distributed datastores. It works as a middleware networking service and handles failures.
Further, Twitter added Cassandra as a data storage solution. Though Gizzard and Cassandra helped Twitter handle data queries, the latency problem persisted. They needed millions of queries per second with low latency in a real-time environment.
So, they created an in-house distributed database called ‘Manhattan” to improve latency and handle several queries per second. Twitter improved reliability, availability, and latency, among other things, with this distributed system. Furthermore, Twitter migrated data from MySQL to Manhattan and adopted additional storage engines to server different traffic patterns.
Another key aspect of Twitter’s dedicated database solution was the use of Twemcache and Redis. It helped them protect backing data stores from heavy read traffic.
A dedicated microservice datastore approach helped Twitter handle,
- More than 20 production clusters
- More than 1000 databases
- Manage tens of thousands of nodes
- Handle tens of millions of queries per asecond(QPS)
6. Containerize microservices to improve process efficiency
Containerization of microservices is one of the most efficient best practices. Containers allow you to package the bare minimum of program configurations, libraries, and binaries. As a result, it is lightweight and portable across environments.
Apart from this, containers share the kernel and operating system, reducing the need for resources for the individual OS. There are many benefits that containerization can provide,
- Isolation of process with minimal resources
- Smaller memory footprint
- Higher data consistency due to shared OS.
- No impact of sudden changes of outside environment on containers
- Optimized costs and quicker iterations
- Rapid rollouts and rollbacks
Learn how Spotify migrated 150 services to Kubernetes to process 10 million QPS.
Spotify has been containerizing microservices since 2014; however, by 2017, they understood that their home-grown orchestration system, Helios, was insufficient to iterate quickly for 200 autonomous production teams.
Kubernetes for Spotify was the solution to Helios’ inefficiency. To avoid putting all of their eggs in one basket, Spotify engineers migrated some services to Kubernetes, which runs alongside Helios.
After thoroughly investigating core technical challenges, they used Kubernetes APIs and extensibility features for integration. Further, Spotify accelerated the migration to Kubernetes in 2019, focusing on stateless services. They migrated over 150 services to handle 10 million requests per second.
How is microservice architecture making a difference in various business sectors?
7. Increase native UI capabilities with micro frontend
Micro frontend architecture is a method of breaking down a monolithic frontend into smaller elements. It follows the microservice architecture and enables individual UI element upgrades. With this approach, you can make changes to individual components and test and deploy them.
Further, micro frontend architecture also helps in creating native experiences. For example, it enables the usage of simple browser events for communication that are easier to maintain than APIs. Micro frontends improve CI/CD pipelines by enabling faster feedback loops. So, you can build a frontend that is both scalable and agile.
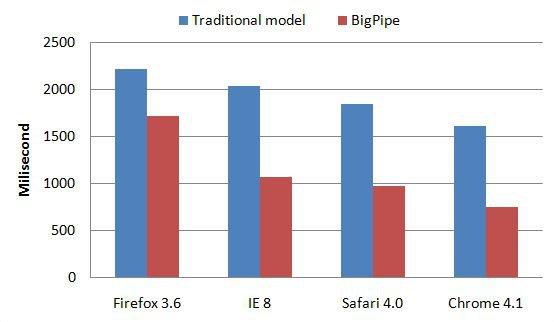
How Facebook improved web page latencies with BigPipe
In 2009, Facebook was having trouble with the frontend of its website and wanted a solution to reduce loading times. The traditional front-end architecture needed overlapping browser rendering and page generation optimizations. Such optimizations were the only solution to help them in reducing the latency and response time.
Which is why Facebook built a micro frontend solution called the BigPipe. This allowed Facebook to break the web page into smaller components called “pagelets.” Using BigPipe, Facebook has improved latency across browsers’ web pages.
Over time, modern micro front-end architectures have evolved from web pages to support use cases like web apps and mobile applications.
8. Secure microservices for data protection
Microservices communicate with external services or platforms through APIs, and securing such communication is essential. Data can be compromised, and hackers can take control of core services and disrupt your app’s operations if you don’t use effective precautions. To give you a perspective, data breaches cost businesses more than $2.9 million every minute.
So, microservices security is critical to your business. There are many ways to secure microservices like,
- SSL/TLS encryptions
- Multi-factor authentications
- Restricted data access
- Web application firewalls
- Vulnerability scanning
- Penetration testing
OFX secured microservices with a middle-tier security tool
OFX is an Australian international financial transfer institution that processes more than $22 billion worth of transactions every year.
After migration to the cloud environment, OFX needed a highly secure solution to increase visibility and protection against cyber threats defined by the Open Web Application Security Project (OWASP).
OFX partners and external services communicate with the microservices through APIs in an internal network. Therefore, they needed to improve security and visibility to properly verify access requests from external platforms.
To tackle this, OFX deployed a security tool in the mid-tier environment with an agent on their web servers to have visibility of several aspects, including,
- Detection of suspicious patterns
- Monitoring of login attempts
- Blocking malicious traffic
- Extensive penetration testing
By adding a security tool in the middle-tier, security teams and cloud architects can track every interaction of APIs. It helped them detect anomalies and secure microservices.
9. Simplify parallel programming with immutable APIs
Microservices and immutability share the idea of parallelism, which also helps apply the Pareto Principle. In addition, parallelism allows you to accomplish more within less time.
Immutability is a concept where data or objects, once created, are not modified. Therefore, parallel programming is much easier, especially when using microservice architecture.
Understanding how immutable containers improve security, latency, and more.
Let’s consider a use case like an eCommerce web app that needs integration of external payment gateways and third-party services.
Integration of external services needs APIs for microservice communication and data exchange. Traditionally, APIs are mutable and provide the power to create several mutations as needed.
However, the problem with mutable APIs is susceptibility to cyber-attacks. Hackers exploit shell data access to inject malicious codes.
On the other hand, immutability with containerized microservices improves security and data integrity. You can simply remove the faulty containers with immutable containers instead of fixing them or upgrading them. In other words, immutable APIs can help your eCommerce platform secure users’ data.
Another key advantage of immutable API is parallel programming. A major caveat of concurrent programs is how changes in one thread impact other threads. It leads to complications for programmers who need to figure out the context in which their thread executes.
Immutable APIs solve this problem by restricting the side effects of one thread on others. It restricts the change of state no matter which version of an object a thread accesses. If a thread needs an altered version of an object, a new one is created in parallel. So, you can execute multiple threads in parallel, improving programming efficiency.
10. Increase delivery speeds with a DevOps culture
DevOps is a set of practices that breaks the siloed operational and development capabilities for enhanced interoperability. Adopting DevOps can help your organization with a cohesive strategy and efficient collaboration, among other benefits.
DocuSign reduced errors and improved CI/CD efficiency with DevOps.
DocuSign introduced the e-signing technology using the Agile approach for software development. However, they soon realized that the lack of collaboration between individual teams resulted in failures.
DocuSign’s business model, which involved contracts and signatures, needed continuous integration. In addition, the exchange of signatures and approvals needs to be error-free, as a single misattribution can lead to severe problems.
So, DocuSign adopted the DevOps culture to improve collaboration between operation and development team members. Despite the cultural shift in the organization due to DevOPs adoption, the CI/CD problem persisted. They used application mock for internal APIs to support continuous integration.
The application mock tool offers a mock endpoint and response. DocuSign combines it with incident management and tests the app before release through simulations. It helped them quickly build, test, and release applications through a cohesive strategy.
Simulations allowed them to test the app’s behavior in real-life scenarios, improve fault isolation and make quick changes. So they could continuously test, integrate changes, and have continuous delivery cohesively.
11. Deploy a version control system
Microservice version management is crucial for cloud-native software development. You need to manage thousands of objects that form the software supply chain. Imagine the complexity of managing microservices across so many software versions!
So, what is version control in microservices?
Version control in microservices is an approach that enables teams to maintain multiple services with the same functionality. It involves tracking changes in application containers and attributes like key-value pairs, software bills of materials, licenses, etc.
Versioning for reducing the microservice drift
When you implement microservices, your application will face a phenomenon called “Drift.” It occurs when different versions of a single microservice run on multiple clusters and namespaces. Let’s take an example of an online store that sells candy, clothing, and toys on different clusters, and all three use a common microservice for shipping.
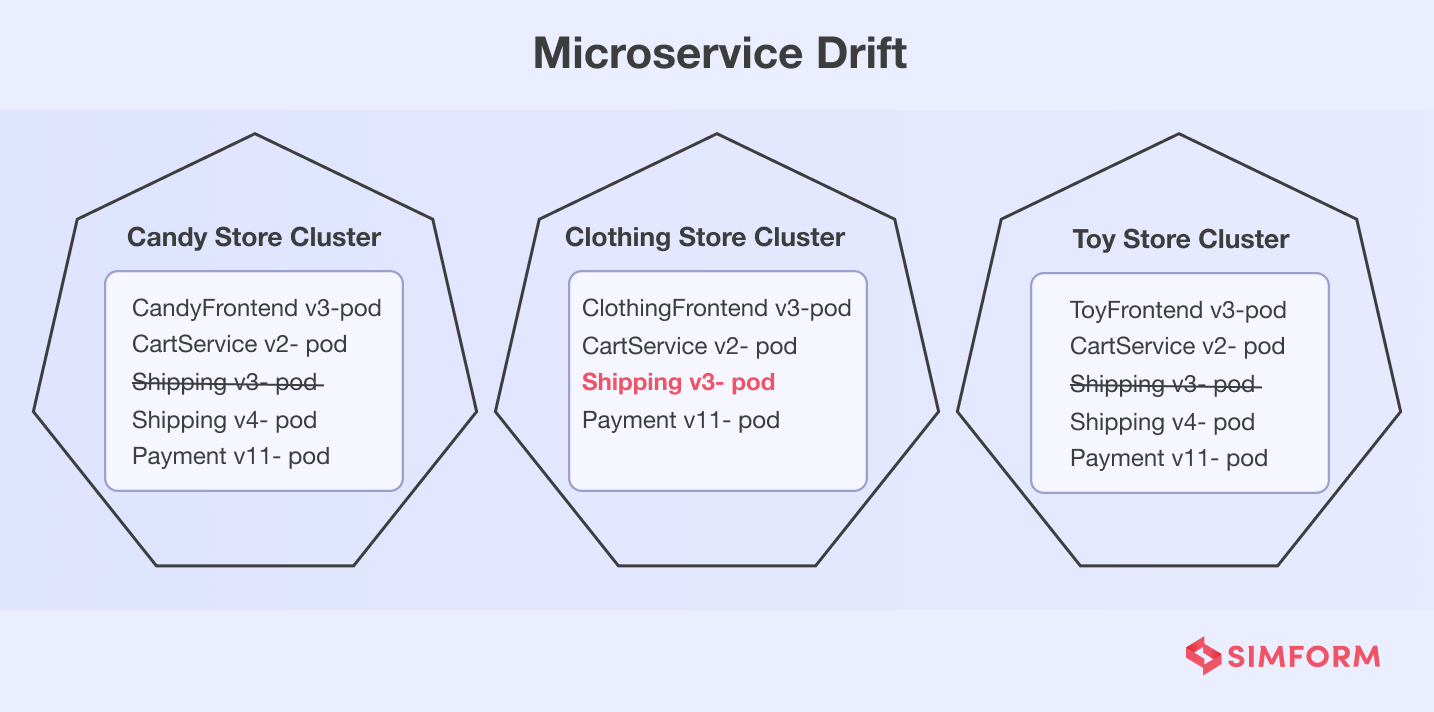
You can notice the drift in a clothing store for shipping microservice. One way to avoid the drift is to deploy the same version across the stores. However, it is not an ideal solution, with some environments not ready for deployment.
This is why microservice versioning is crucial in managing different versions across environments. To implement an optimized microservice versioning system, you can use approaches like:
- URI versioning
- Header versioning
- Semantic versioning
- Calendar versioning
URI versioning
Uniform Resource Identifier (URI) helps connect physical resources or abstract resources. URI is a string of characters that acts as an identifier for a file path or a scheme name. You can add version information directly to a service’s URL, which offers a quick way to identify specific versions.
The development team or testers can simply look up a Uniform Resource Locator (URL) and determine the version. Here are some examples of URLs that you can use to check the microservice version,
- http://productservice/v1.1.2/v1/GetAllProducts
- http://productservice/v2.0.0/GetProducts
Here, V1 and v2 are two versions of the services, and you can copy data from v1 into the v2 database. This helps keep the two databases separate, making updating the schema and altering the code easier. Here is an example of the code snippet showing two versions of a service running side-by-side using URIs,
[ApiController]
[ApiVersion("1.0")]
[Route("api/{version:apiVersion}/product")]
public class EmployeeV1Controller : ControllerBase
{
[HttpGetbn]
public IActionResult Get()
{
return new OkObjectResult("Inside Product v1 Controller");
}
}
[ApiController]
[ApiVersion("2.0")]
[Route("api/{version:apiVersion}/product")]
public class EmployeeV2Controller : ControllerBase
{
[HttpGet]
public IActionResult Get()
{
return new OkObjectResult("Inside Product v2 Controller");
}
}
But scaling and managing the naming convention with URI can be tricky. This is where header versioning helps with better naming conventions.
Header versioning
This microservices versioning approach leverages HTTP protocol header attribute to pass version information, also known as “Content-version.” Header-driven versioning uses the content-version attribute to specify the service.
Here’s an example code snippet that shows how you can configure header versioning in ASP.Net Core:
public void ConfigureServices(IServiceCollection services)
{
services.AddControllers();
services.AddApiVersioning(config =>
{
config.DefaultApiVersion = new ApiVersion(1, 0);
config.AssumeDefaultVersionWhenUnspecified = true;
config.ReportApiVersions = true;
config.ApiVersionReader = new HeaderApiVersionReader("x-api-version");
});
}
One of the key benefits of using header versioning is the naming conventions. Unlike URI, the header versioning helps maintain the names and locations of app resources across the updates. It ensures that URI remains uncluttered with the versioning data, and API names retain semantic meaning.
However, using header versioning can lead to configuration issues. This is where using semantic versioning makes more sense.
Semantic versioning
Semantic versioning uses three non-negative integer values to identify version types like major, minor, and patch(MAJOR.MINOR.PATCH). In this approach, the three integer values help make the versioning easy to understand.
If you have a previous version compatible with the new version but some logic of service changes, you can just number it. In other words, you must add a number every time you fix a code or add patches.
For example, if you name a new version, v1.0.1, it indicates a slight change in the service executed through a patch. When there is a significant change in the new version, the naming convention will be v2.0.0.
Calendar versioning
This is an approach where you can use date format for naming versions. So, you can refer to the version names and identify when it was deployed. For example, if you want to name the version created in 2020 and identify two error patches, it can be named 4.0.2.
Now, if you have a significant update the following year, it will be named 4.1.0, and each minor update after that will be named 4.1.2.
12. Ensure backward compatibility of service endpoints
Microservices versioning is critical to managing different renditions of the same service and improving backward compatibility. However, there are other best practices to ensure backward compatibility.
But why bother so much about backward compatibility?
Backward compatibility for different services ensures that the system does not break if there are changes. In other words, you need to plan to evolve all the services together without breaking the system.
One way to ensure backward compatibility is to agree to contract services. However, if one service breaks the contract, it can cause issues for the system. For example, Restful web APIs are crucial for communication between distributed systems. Though with advanced technologies, APIs need updates that can break the system.
You can use the robustness principle or “Postel’s Law” to avoid such issues and ensure backward compatibility for service endpoints. It is an approach where you must be conservative about what you send and liberal about what is received.
For web APIs, you can apply the robustness principle in the following way for enhanced backward compatibility:
Every API endpoint needs only one CRUD operation; clients must be responsible for aggregating multiple calls.
Servers need to communicate the expected message formats and adhere to them.
Ignore new or unknown fields in message bodies which can cause errors in APIs.
13. Avoid hardcoding values
A critical microservice best practice is to avoid hardcoding values so that network-based changes do not cause system-wide issues. Let’s take an example of an eCommerce application. Customer service receives the delivery request when a user adds products to the cart and makes the payment.
Conventionally, developers hardcode the service address of the shipping service. So, if there is a change in the network configuration or address for customer service, it becomes difficult to connect with the shipping service.
The best approach is to leverage a network discovery mechanism using a service registry or proxy. Once you integrate network discovery tools, it becomes easy to connect and execute functions.
14. Leverage a centralized logging and monitoring system
Several functionalities are visible on the home page of Netflix; Right from a series of recommendations to profile management and one-click play options. This performance and functionality have been possible because the Netflix team has executed all these functions across multiple microservices. Logging and monitoring systems allow businesses to manage multiple microservices easily in a distributed architecture.
A centralized logging and monitoring system helps in tracking changes in microservices and handles errors better. As a result, it also facilitates enhanced observability. Besides the improved visibility, centralized logging helps the teams with root cause analysis for errors in microservices.
80/20 the Simform way!
The 80/20 principle is all about reducing efforts and maximize gains. These microservice best practices can help you achieve maximum gains. However, which one to choose remains use case specific. Take an example of CrayPay, that needed an m-payment solution for retail payments.
Simform used the independent microservice best practices to help CrayPay create a m-payment solution deployed across 50,000 retail locations. Similarly, you need to consider use cases and business requirements before choosing a microservice best practice. So, if you are looking for the right microservice solution, get in touch with our experts now.
