With the launch of Dall-E 2, Stable Diffusion, and Midjourney, diffusion models have pushed machine learning boundaries by transforming text into stunning images and videos. These models have not only inspired creativity but also found practical applications in fields like drug discovery, virtual reality, and content creation.
For example, MIT’s DiffDock represents a breakthrough in drug discovery, outperforming traditional methods.
As these models evolve, we can effortlessly create images, videos, and immersive experiences. For instance, when we used a prompt in Stable Diffusion, like “A large cabin atop a sun-drenched mountain in the style of Dreamworks and Artstation,” it generated four different outputs.

As diffusion models reshape how brands interact with clients, one should understand their details thoroughly. In this article, we will cover what is a diffusion model, its types, benefits, use cases, and ingenious solutions to challenges.
What is a Diffusion Model?
Diffusion model is a powerful class of generative models (parametrized probabilistic model) that can create brand-new data using the trained data. For example, if the model is trained on images of cats, it can generate realistic images of cats.
How Does the Diffusion Model Work
Diffusion model works by adding noise (Gaussian noise) iteratively to a foundational sample (known as the forward diffusion process) and then skillfully eliminating it. The process revolves around enhancing the denoising mechanism (also known as the reverse diffusion process), step by step, to reconstruct the original data.

Each iteration amplifies noise and compels the model to master noise elimination. This gradual denoising process helps the model generate updated samples and understand the data’s intricate patterns and structure.
Types of Diffusion Models
Diffusion models are based on three fundamental mathematical frameworks – DDPMs, SGMs, and SDEs, each of which adds and then removes noise to generate new samples. Let’s discuss them:
#1. Denoising Diffusion Probabilistic Models (DDPMs)
DDP models are generative models primarily used to reduce noise from visual or audio data. Their applications extend to image quality amplification, missing details restoration, and file size reduction.
For example, the entertainment industry uses advanced image and video processing techniques to produce realistic backgrounds or scenes for movies and improve production quality.
#2. Noise-conditioned Score-Based Generative Models (SGMs)
Noise-conditioned SGMs blend randomness with real data and refine it using calculated adjustments guided by a “score” tool. This tool, paired with a “contrast” guide, favors real data over created samples, which makes SGMs useful for crafting and modifying images.
Notably, they excel in crafting lifelike images of familiar faces and enriching healthcare data, often scarce due to strict rules and industry norms.
#3. Stochastic Differential Equations (SDEs)
Stochastic Differential Equations (SDEs) are mathematical models that help us understand how random processes change over time. They are commonly used in fields like physics and finance, where randomness plays a significant role.
For example, SDEs can help us accurately predict the prices of commodities like crude oil by considering the factors that can affect their value.
Why Incorporate Diffusion Models
Diffusion models not only produce more realistic imagery and match real images’ distribution better than GANs, but they also improve creativity, efficiency, and marketing efforts. Here’s more to it.
#1. Generates Realistic Imagery
Unlike other generative models, such as GANs and VAEs, diffusion models are easier to train with a simple and efficient loss function. They’re also more stable than Generative Adversarial Networks (GANs), which can sometimes get stuck and generate only a limited range of images, although that is rare. Diffusion process sidesteps this issue as it smoothens the distribution. Thus, diffusion models are more suitable for diverse and high-quality images than GANs.
#2. Expands Creative Possibilities
With a simple text prompt, diffusion models spark new ideas, creating fresh directions for various projects. Their versatility extends to various data types, such as images, audio, and text. It leads researchers to explore applications like text-to-image and image inpainting.
#3. Improves Branding and Marketing Efforts
Diffusion models generate visuals that resonate with audiences and improve engagement and recognition. Using AI-generated images in brands and marketing strategies boosts modernity and customer rapport. For example, Coke used Stable Diffusion in an ad campaign where the entire museum’s art came together to inspire and uplift a boy.
Use Cases of Diffusion Models
#1. Text-to-Image Generation
Midjourney, Google Imagen, and DALL-E are transforming image generation. OpenAI’s DALL-E neural network creates images based on textual descriptions using a diffusion-based generative model.
For example, it can create images like a synth wave-style sunset above the reflecting water of the sea within a digital art context.

Google released an exclusive text-to-image model named ‘Imagen’, which uses large transformer language models to understand text and diffusion models to create high-fidelity images.
It features three image generation diffusion models: one for producing 64×64 resolution images, followed by a super-resolution model to upsample 256×256 resolution and a final model that elevates the image to 1024×1024 resolution. These applications blend diffusion and language models to create accurate and relevant visuals from text prompts.
#2. Text-to-Video Generation
Diffusion models, like MagicVideo, can now turn text prompts into videos, such as “time lapse of sunrise on mars,” without extensive CGI.

However, these models are still in early development and face challenges such as computational cost, data scarcity, temporal coherence, and user feedback. They aren’t widely accessible for general users yet. Meta’s Make-A-Video is one such platform.
As of 2023, several AI video generators, including Pictory, Synthesys, and Synthesia, are available to simplify video content production.
#3. Image Inpainting
Image inpainting is an image restoration technique to remove or replace unwanted elements in images. It involves creating a mask to visualize specific areas or pixels for modification and guiding the model to make the desired changes.
For instance, you can erase a person from a photo and fill the background with grass by drawing a mask and specifying the color green. This technique can quickly handle real and synthetic images and produce high-quality results.
Here is an example of restoring the image:

#4. Image Outpainting
Image outpainting extends images, creating larger and more cohesive compositions while maintaining the same style. Users can give cues such as “add a mountain on the right” or “make the sky darker” to create new narratives.
It’s like enhancing photos with extra elements for scene coherence. For example, you can add more trees and clouds to a lake photo or enhance a city painting with additional buildings and cars.
Outpainting generates entirely new content not in the original images, different from inpainting, which fills missing or unwanted parts.
First Dalle 2 #outpainting
— Jojo Eco (@AIdenNFTSx) August 31, 2022
"a man riding a horse"#dalle2 #AIart #openai pic.twitter.com/wKhfx36LAk
#5. Text-to-3D
Text-to-3D innovation uses neural radiance fields (NeRFs) to train a 2D text-to-image diffusion model that creates 3D representations from text prompts. These models offer fluid perspectives, adaptable illumination, and effortless integration into various 3D environments. The presence of pre-trained image diffusion models eliminates the need for specialized 3D training data.
For example, the Dreamfusion project, powered by the Stable Diffusion text-to-2D model, generates high-quality images from text prompts, like real-time views of objects with a graphical user interface (GUI).
#6. Text to Motion
Text-to-Motion uses advanced diffusion models to bring text to life by generating human motion, including walking, running, and jumping. In the “Human Motion Diffusion Model” paper, the authors introduced the Motion Diffusion Model (MDM), a diffusion-based generative model specifically adapted for the human motion domain. They said,
“MDM is transformer-based, combining insights from motion generation literature. A notable design-choice is the prediction of the sample, rather than the noise, in each diffusion step. This facilitates the use of established geometric losses on the locations and velocities of the motion, such as the foot contact loss. As we demonstrate, MDM is a generic approach, enabling different modes of conditioning, and different generation tasks. We show that our model is trained with lightweight resources and yet achieves state-of-the-art results on leading benchmarks for text-to-motion and action-to-motion.”
#7. Image to Image
Image to Image (Img2Img) is a technique that reshapes existing visuals with a simple text prompt. It alters images based on textual descriptions.
Palette is a framework for image-to-image translation using conditional diffusion models. It excels in colorization, inpainting, uncropping, and JPEG restoration.
For example, Stability AI introduced Stable Diffusion that supports Img2Img generation.
With an image of a cat and a prompt describing a serene nocturnal scene with moonlight, the result achieves exceptional detail and realism, inspired by artists like Carl Kahler, Henriette Ronner-Knip, and Bruno Liljefors.
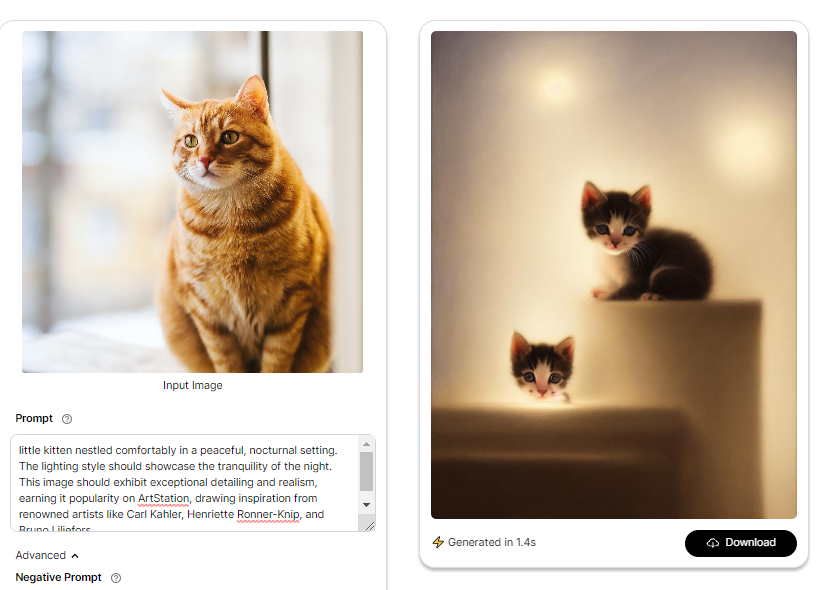
But that’s not it. Diffusion models offer even more!
Microsoft Designer’s integration of Dall-E 2 impacts various industries. In Retail and eCommerce, it facilitates product designs, catalog creation, and alternate angles generation. 3D diffusion models rapidly produce full product renders, manifesting as tangible 3D models.
In the entertainment industry, diffusion models enrich special effects, streamline production, and fuel audacious creativity. NeRFs can turn 2D images into 3D representations that can be viewed from any angle and under any lighting condition.
Marketing and advertising have also found applications, like Nike’s “By You” campaign that lets customers design their own shoes. Designers are using Midjourney to generate product mockups for different design concepts and preview their ideas.

It elevates image quality, diversifies outputs, and expands stylistic horizons. It also provides capabilities for seamless textures, broader aspect ratios, image promotion, and dynamic range enhancement.
Diffusion Models Deployment Challenges
Integration of the diffusion model requires understanding the associated deployment challenges. Some of these include:
#1. Data Privacy and Security Concerns
As diffusion models require large amounts of data for training, there are concerns about privacy breaches and intellectual property infringement. Also, malicious users may attempt to infer the original training data, as seen in the membership inference attack (MIA). Data anonymization and encryption help protect your data from privacy breaches and misuse during modeling.
#2. Compatibility Issues with Existing Workflows
Implementing diffusion models into existing software systems or processes can require significant changes to infrastructure and workflows. Compatibility issues may arise as AI-generated outputs might not align with human intentions and requirements. Careful design, planning, and coordination are necessary for seamless collaboration.
#3. Scalability & Distribution Concerns
The computational needs of these models can strain existing infrastructure, which necessitates efficient resource allocation to scale diffusion models for large applications. Moreover, many AI diffusion models, including those used in DALL-E, are large in model parameters.
Storing and distributing these large models efficiently can be problematic, especially on devices with limited storage capacity. Cloud-based resources alongside model compression or pruning techniques help reduce the size and complexity of the models without sacrificing their performance.
#4. Fidelity and Quality-Related Concerns
What we see in our daily lives, or what we can capture on a camera, can differ in image generation, meaning it might have low fidelity and produce unwanted distortion. Correcting them can be time-consuming.
For example, when we used Stable Diffusion with a detailed input prompt, we explored these concerns:
Prompt: A family of 3 standing in an amusement park with happy faces watching the merry-go-round in front of them, Leica sl2 50mm, vivid color, high quality, high textured, real life.

#5. Biased and Unsafe Data
Standard safety filters lack the depth required to address the complexity of content filtering. Plus, the datasets used to train models contain considerable biased and unsafe data, making the models prone to producing misleading content. A multi-faceted approach is essential to mitigate these concerns.
Embrace the Potential of Diffusion Models
While diffusion models continue to inspire, their true limitations haven’t been fully explored. We’re about to see fundamental changes in human-machine interaction as these models advance. Society, art, and business all can benefit from these implications.
For that, we need a better understanding of Generative AI and how Generative AI models work, along with its evaluation process, and applications to leverage those to achieve our business goals.
