If you ever thought that
“All my app does is to communicate to the server. Why should I design it for an offline experience?”
You really need to think twice! Offline mobile app architecture is the utmost important thing while developing a mobile app.
Networks die, Networks are low, battery constraints and a lot other factors would put your app to test, most often needing an offline support. If your apps have global users, operating from different parts of the world, you need to account for this even more.
No matter how good of a developer you are, or, how available your servers are – most cases would you require something to support your app offline. Depending upon the what your app does, it might be simple or could get scary complicated.
Architecture…what?
After spending so much time on offline architectures for mobile apps, I’ve come to realize that it doesn’t really takes 20+ programming books to get you there. A precise blog post can just do that very well.
No matter whether you are a CEO, a product manager, hobbyist, or even a developer trying to understand how your app could behave offline, this blog is going to serve you as a lightweight read.
First of all, I would simply break offline apps into three broad category:
- Data is stored offline – there’s no editing functionality. Take the example of GPS data being stored offline temporarily in an Uber type app.
- Users can edit their data offline and sync it online. A note taking app would be a great example. Imagine editing a note taking app like Google keep offline on your phone. When your phone gets network, it updates the info online as well and when you open keep.google.com, you see all edits you made.
- Users can edit other user’s data (or data shared data with other users) offline. Imagine making edits to an offline Google doc type app. The edits you make should not only reflect online, but also have to be passed through a set of rules to be filtered for the selection of the final edits and preventing conflicts between multiple online and offline edits.
In the sections that follow, I will walk you through some of my own engineering experiences on using offline mobile app architectures to develop robust apps, and how you can build an app that tackles offline capabilities in the best possible way.
Table of Contents
- Trello’s Offline Architecture Story
- Application Architecture without Offline Considerations
- Offline App Architecture Evolution #2 and #3
- Offline App Architecture #4 and #5
- Lessons from Path on Offline Architectural Support
- The Persistent Offline Architecture
- Evolving Offline Sync Architecture with a Sync Job
- What Offline Architecture to Use, Where and Why?
- Offline-online Sync – Architectural Considerations
Trello’s Offline Architecture Story
In 2016, Trello didn’t supported offline capabilities, and their users were complaining, a lot!
They wanted to use Trello on the go.
They wanted to use it when they were travelling in subways to their work and organize things even before reaching their destinations.
And, Trello wasn’t prepared for any of that.
The initial architecture that Trello started with looked something like this:
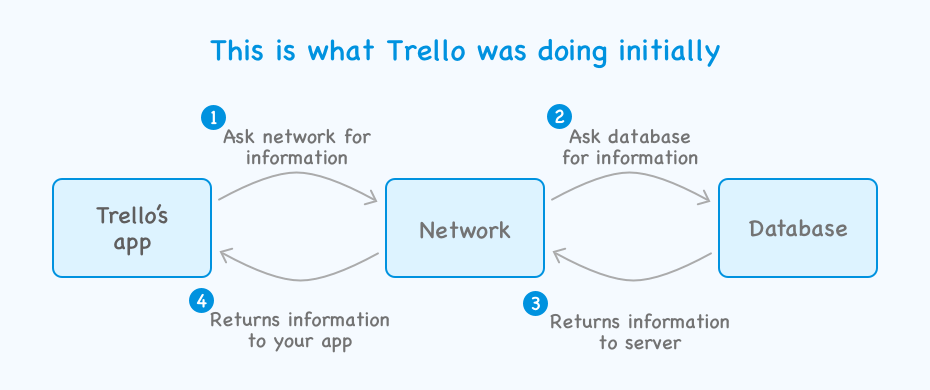
This architecture always assumed that the app will always have a network attached to it. When you have 100 Million plus users, with even a probability that 1% of them at a time would suffer from network disruption implies 1 Million helpless app users. That later translates to a lot of 1 star reviews on app stores.
So, Trello decided to move to an offline-first architecture.
Here’s how the newer app architecture looked like after upgrade:
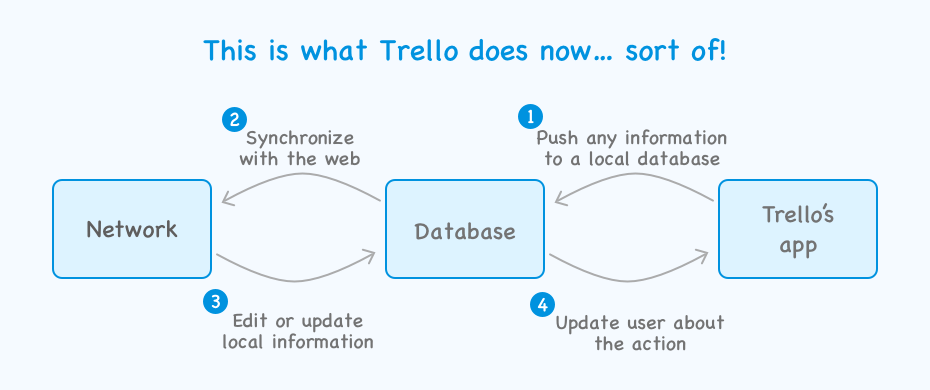
With this new architecture, a local database now plays a central role in the app’s architecture. After this upgrade entire Trello app was able to run offline.
But that’s not everything that Trello did, they went leaps beyond to make sure that their architecture can work smooth online and offline. I will come to that later, but first let’s see offline mobile app architectures from a generic point of view and let’s see how they evolved.
Application Architecture without offline considerations
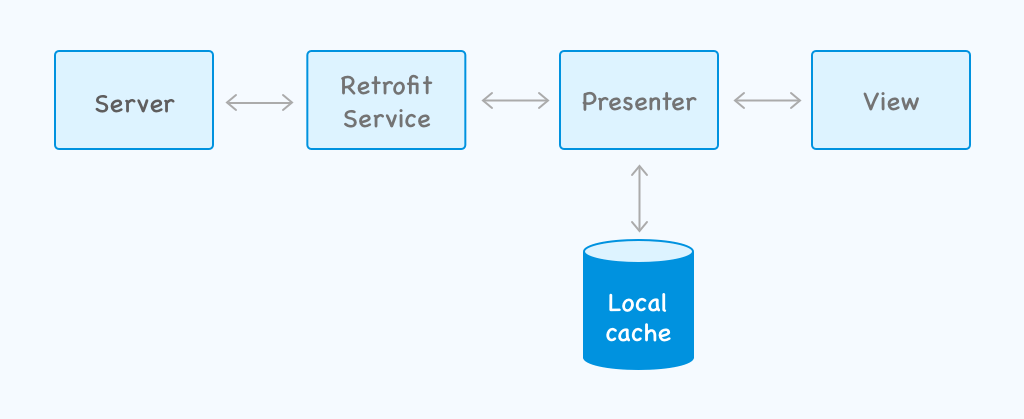
I know, I talked about this before, but let’s for the sake of revision checkout an app architecture based on MVP design pattern. I have listed Retrofit here as a lot of devs use it as their data model.
Here’s how the architecture would look like:
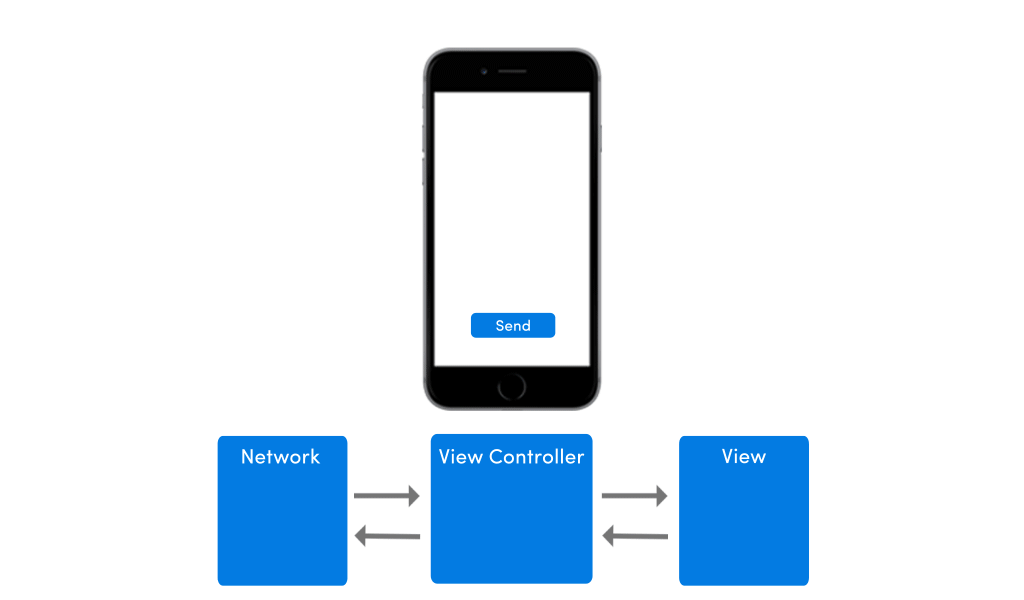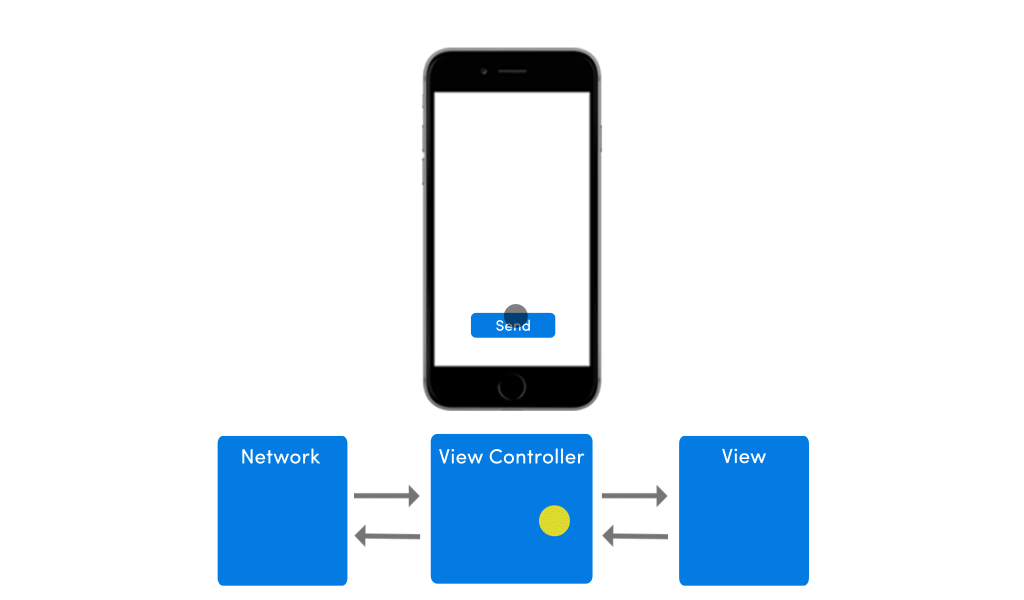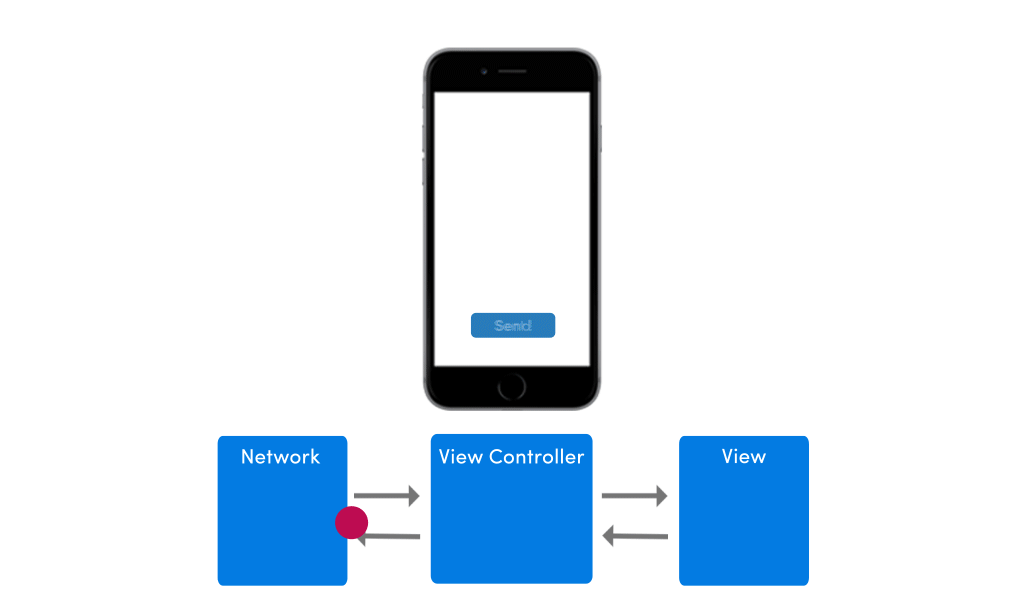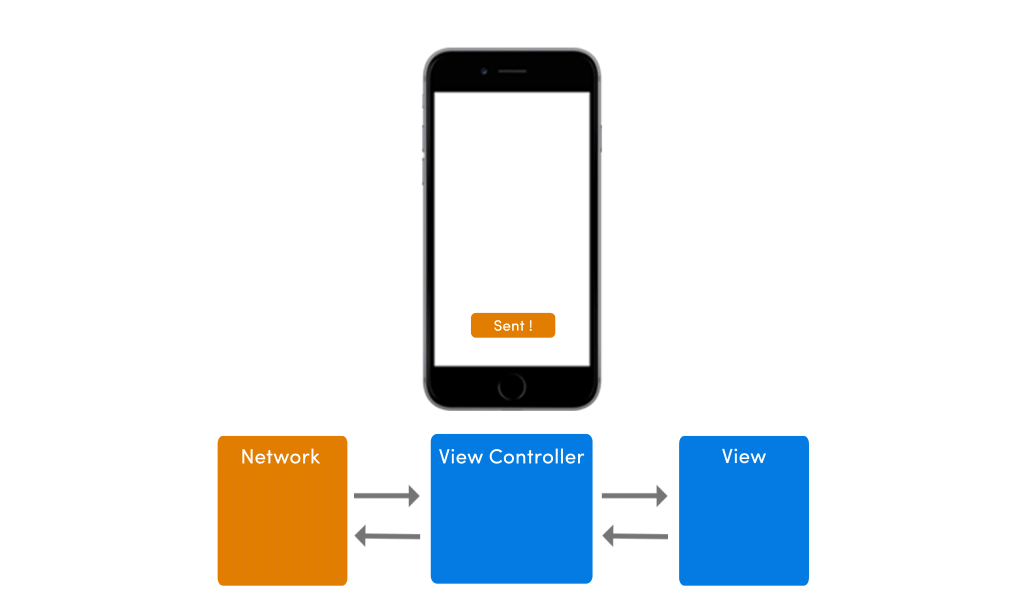
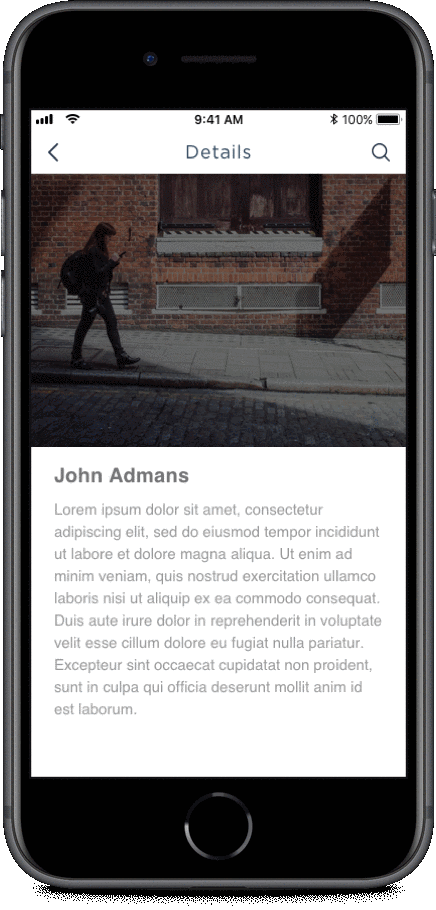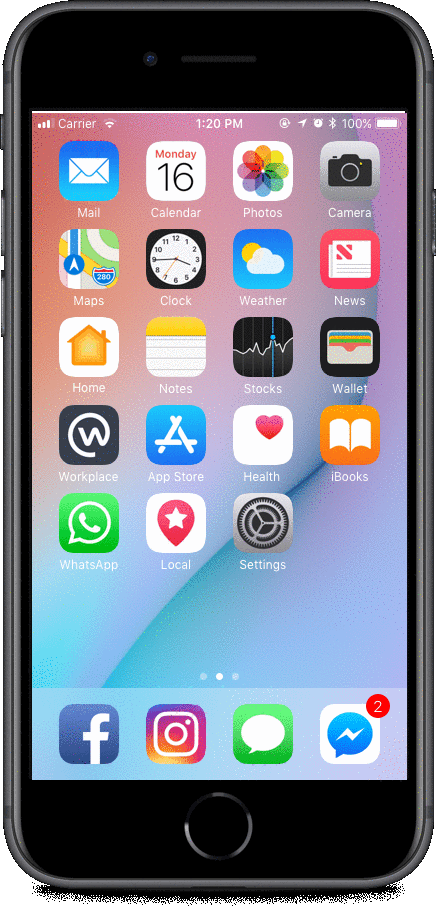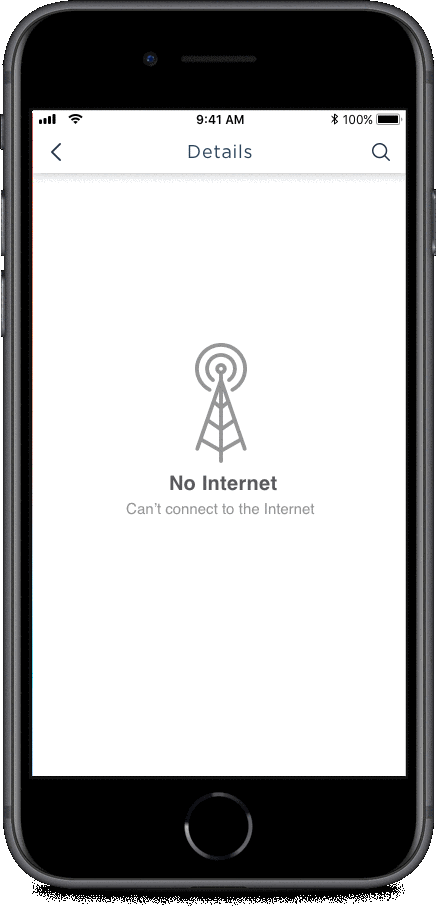
This architecture’s view model relies on network/server to work, so if there’s no network, nothing will happen on mobile. To an end user it might seem as if the app is stuck.
If your app has no network in place, the app’s UI would suffer from any pending requests. The image below shows how the app’s UI would behave in absence of internet connectivity.
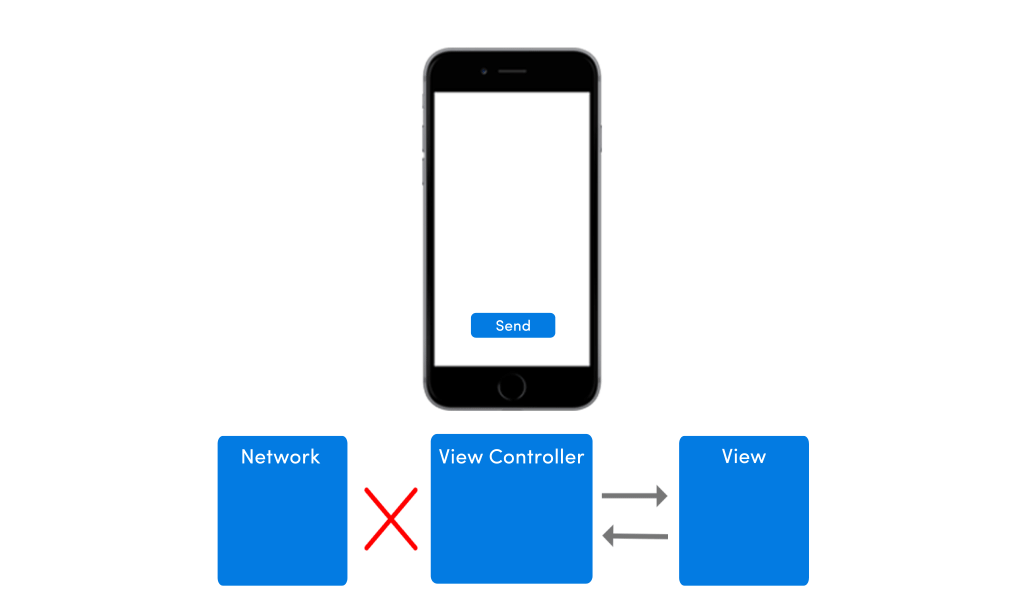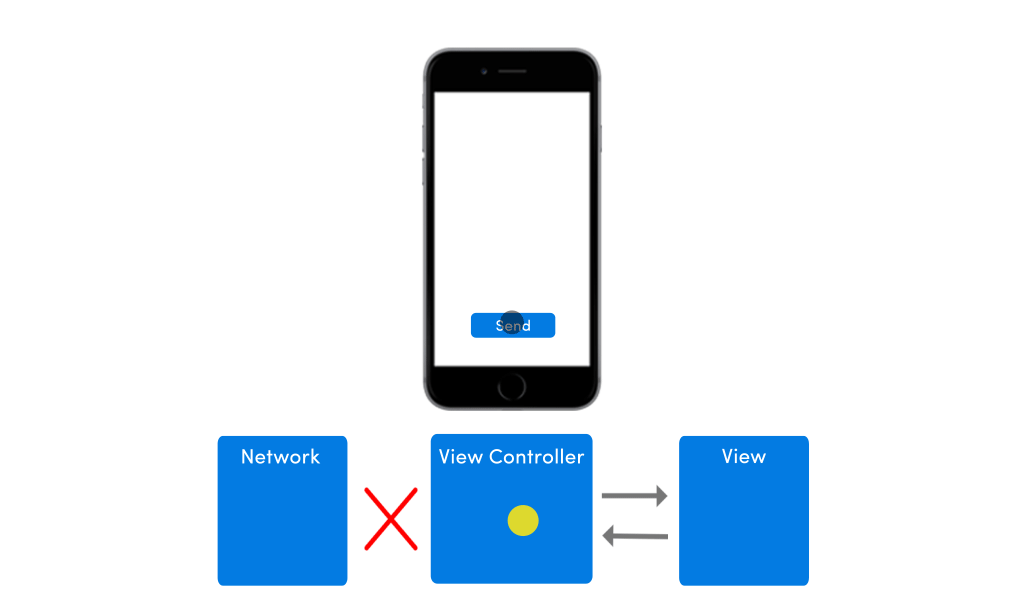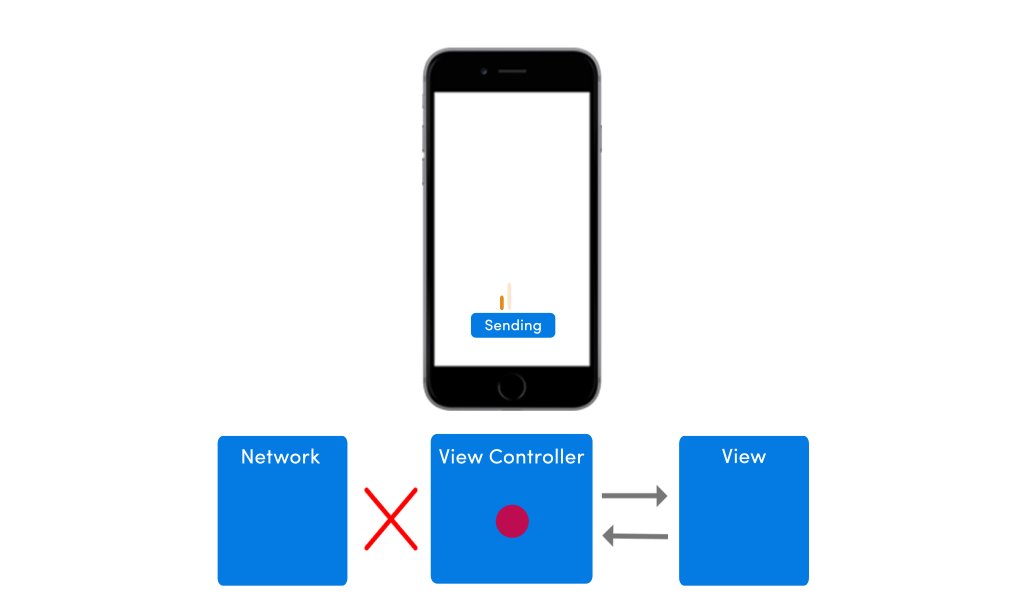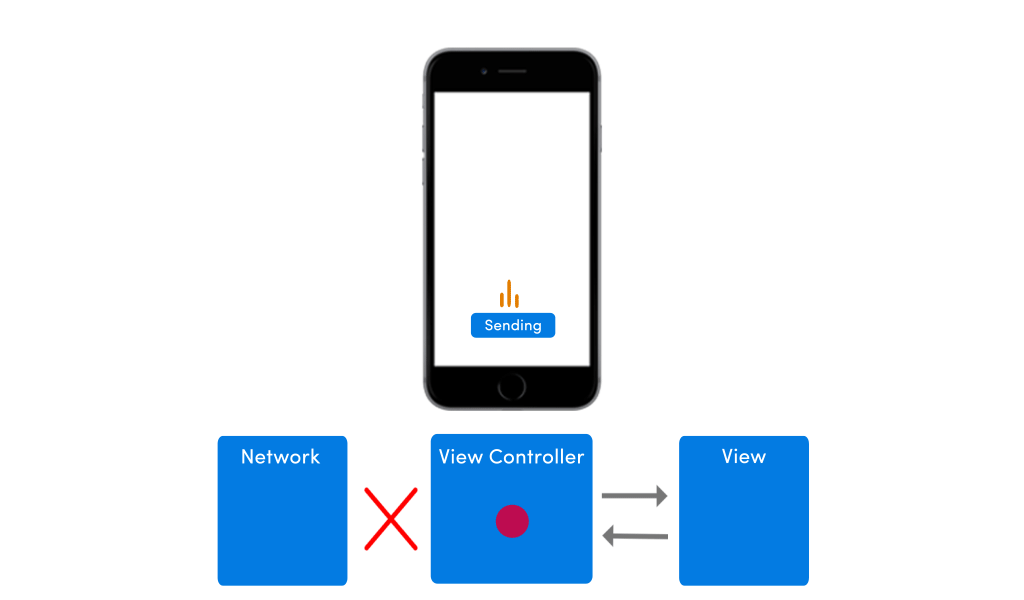
To improve this poor experience with intermittently available network conditions, I would highly advise you to place a model within your app. A lot of clients I work with come to me with apps that have no model in place, and I just wonder, how can you even develop an app without any model?
Improving this architecture a bit
I am not talking about offline yet, but here’s a minimal improvement that we all can make to improve this app’s quality a lot. We will here introduce a model. Let’s take an example of a newsfeed app, where your user read something interesting and wants to add a comment there.
Let’s place a model within your app, and see how a user would now feel.
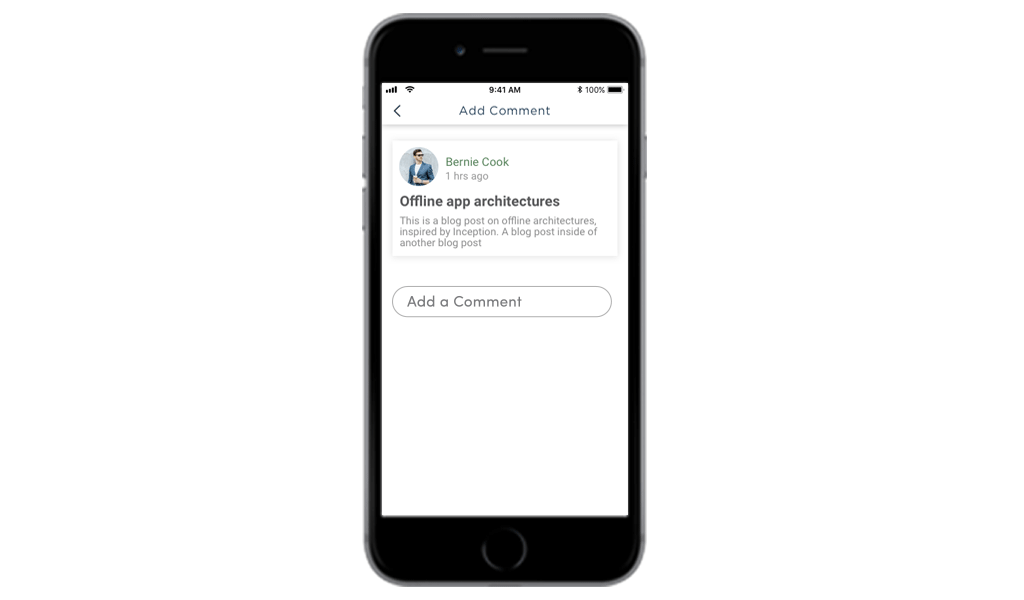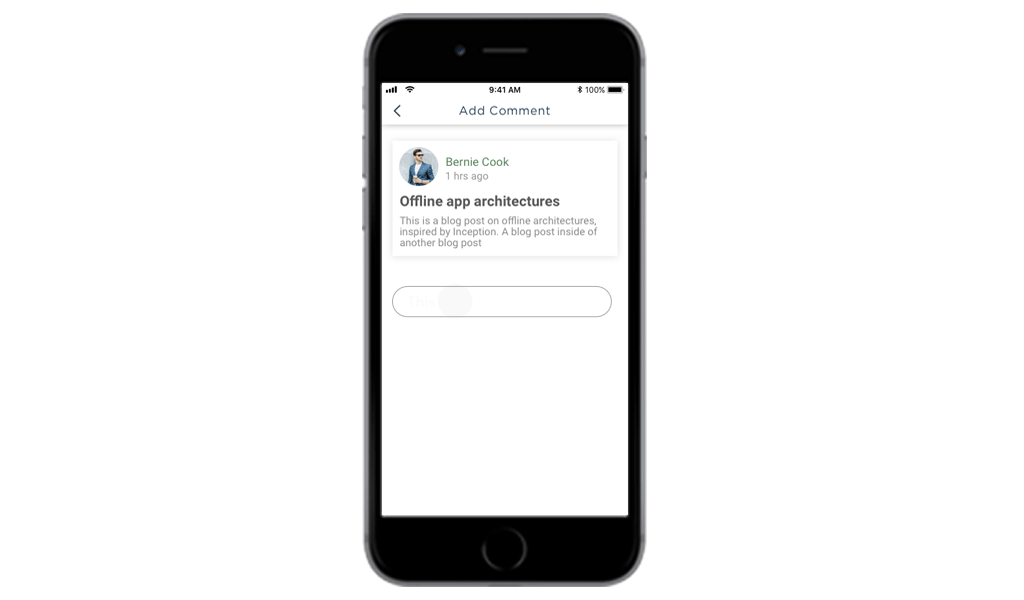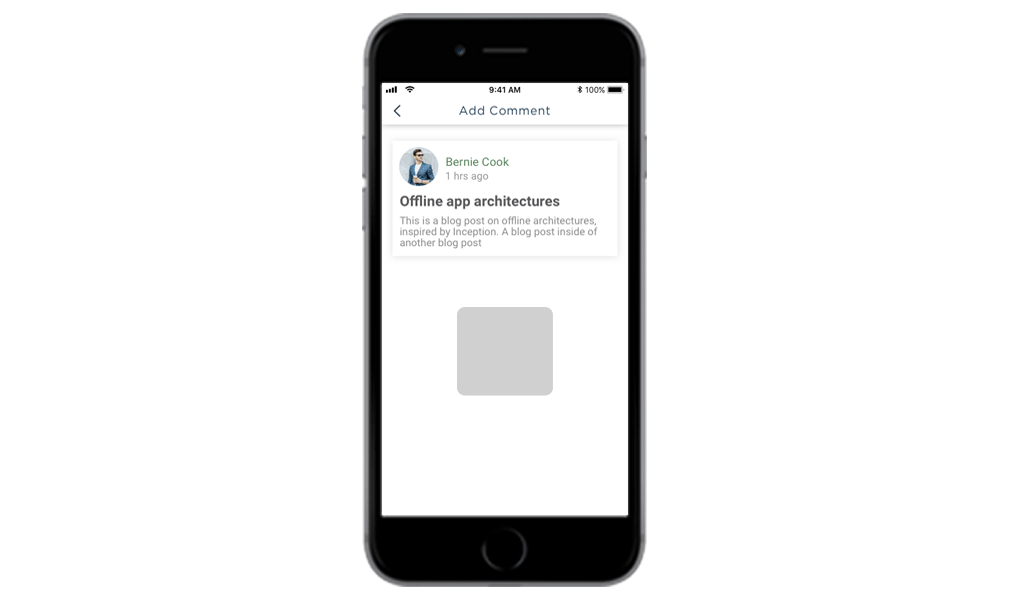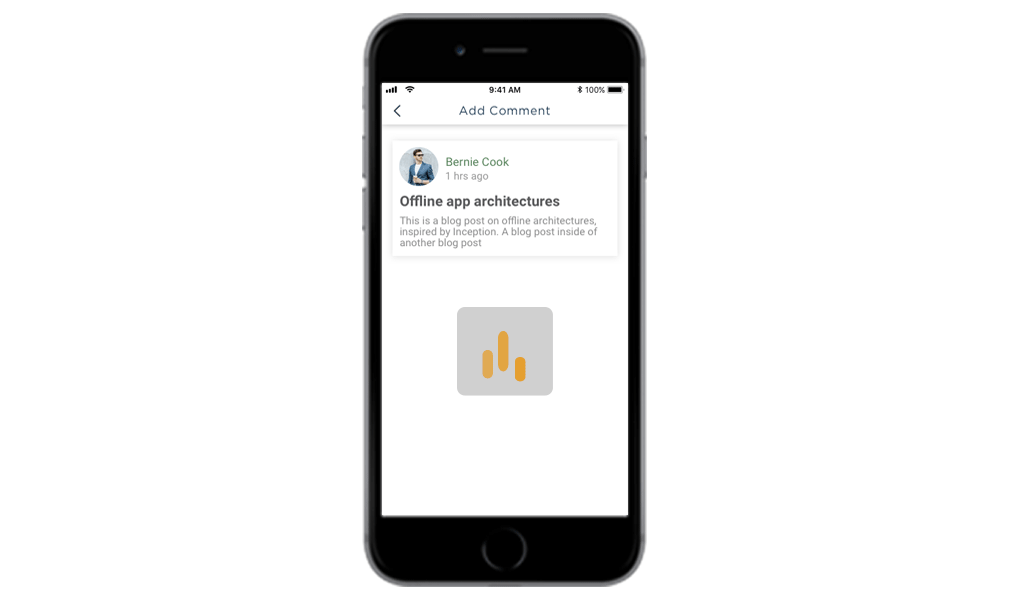
Till your comment gets synchronized with the server it would be light in the color, the user in this case won’t be locked out from his UI. And, when it gets fully synchronized it will be dark black as your can see in the image above.
Offline Mobile App Architecture Evolution #2 and #3
As time progressed, developers noticed this shortcoming and started introducing local cache to their app to work in offline scenarios.
Let’s talk about the same newsfeed app, but this time with a context to Android. Developers usually either handle the caching vai Shared preferences or via SQLite database.
Dedicated cache service
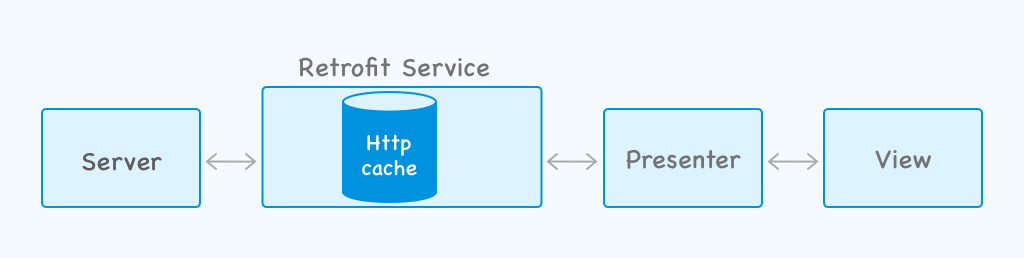
In the architecture shown below, cache is applied to the architecture with a dedicated cache service. Doing so allows developers to cache http requests locally.
Cache applied to the Presenter
In another common modification of this architecture, cache is applied to the presenter instead.
While both of these seemed to work for some low complexity use cases, truth is that if you are building an app that has a substantial user base, they won’t be able to work through properly.
Another problem with such offline support that I do see frequently is often with implementation errors. I have seen an app where cache was saving a GET response based on the URL only, regardless of the query parameters.
A few more challenges that I have seen with this architecture:
- Shared preference: A lot of edge cases have to be handled by your architecture, you might have to fail first and improve upon gradually. Costing you a few bad reviews on app store, or multiple iterations on your app’s beta version
- SQLite is heavy: If your content structure changes, you will have to create a migration script to move to a new schema. You could potentially suffer from concurrency.
Offline Mobile App Architecture #4 and #5 – Robospice, Retrofit
So, let’s say to prevent a poor user experience you start to cache http requests and you are caching. That way you aren’t making the same request again.
Caching can drastically reduce the number of web server requests your app is making.
App architecture with Retrofit
Let’s say if you are already using an http client with your mobile app, let’s say something like Retrofit. You can simply create a custom configuration for the HTTP client, you can then define a cache size for this client, let’s say 50MB. At then end you can simply configure an interpreter to get the request from the cache if the server is not available.
Here’s how this architecture would look like:
How does http caching stands against previously listed solutions?
Apart from significant offline support, there is something obvious that you should know about. Database testing (specifically unit testing) isn’t that straightforward. When you provide an offline support using SQLite type database, not only you are making everything a bit more heavy for your app’s users, but you are also reducing test coverage significantly.
Note: We do have ways to perform unit testing on local mobile databases, but these methods are quite advanced and aren’t for beginners. I will write a detailed blog post on this shortly.
In terms of code complexities:
- An existing HTTP cache based client would incur a code complexity of O(1)
- SQL database would bring in an code complexity of O(n^2)
- Shared preferences bring a code complexity of O(n)
Http caching isn’t enough for offline architectures
Even though you used a library like Robospice on Android, or XYZ on iOS, you would ideally think that you have covered enough for an offline experience – But that isn’t sufficient enough! Let’s walk through a scenario to see exactly how this happens:
- App cached data locally using http cache, everything seems fine and the user is able to read a cached article within their app.
- Users leaves the app to respond to an incoming message (assuming that the network is absent), he opened the app after writing “Okay” to a friend and sees that the article isn’t there any more. User instead gets an error message.
What happened there?
The moment a user leaves your application, the app is running in the background and Android decides to kill it. And, when the user comes back to your app next time, clicks on the activity – user sees nothing!
Didn’t your user had this information moments before in the same exact screen? The problem here was that you were on caching your web requests and the only time your user had this information was when he/she made a request to load news. When your user comes back to the same new article page, they don’t make the same request again. So your app won’t fetch information from in-memory cache, although you have this article stored in your memory cache.
Your users simply can’t access it. This is an engineering disaster!
Lessons from Path on Offline architectural support
Before we go into the details of the architectures that should be used to deal with situations like this, let’s first have a look at the story of Path app.
Path started building their iOS app first, which was working great and had been shaped by years of fine tuning. They now launched an Android app, which was build pretty fast to catch up with the features.
At that time, Path had a lot of users from Indonesia. But Indonesia had a bad network as well.
On a fine day, Path suddenly started getting 1 star reviews with users complaining about:
- Android users failing to post
- iOS users getting unusually low engagement on their posts
Developers at Path kept diagnosing one issues after another, focusing mainly on the API parts to see if that’s what was causing these issues.
The Persistent Offline Architecture
While caching http requests might seem like a good solution to a lot of realistic problems. Let’s take the example of a social networking app that uses previous two architectures and see what happens when they are subjected to high stress
The issue with most http request models is that when you leave an app and come back, you basically start with an empty model. Since this model is empty, it can’t fetch anything that you have in your cached memory.
So, how do we fix this?
Simple, we change ourselves to a persistent model. Here we start persisting our data on disk. By doing that, if your user leaves your application your data is still there. We use something called an application logic, this is something that makes the network calls and keeps our persistent model upto date.
And whenever this application logic does that it notifies, this application logic can be built on top of RX or whatever you prefer. As soon as it fetches something, it shares this information with the persistent model, this information can then be used by the entire application. And, whatever component/part of your app needs, that component can request this information from this persistent model.
So, now let’s say that your newsfeed app user wants to add a comment. The action he takes on the UI (writing comment and posting it), then gets routed via the View Controller that communications it with the Application logic. This application logic then talks with Persistent logic and stores this information to the disk. This in-turn then updates the View itself with the new data. This is how your views become more event driven. If the network is available, the Application logic updates the network/server as well.
Space for further optimization
Great! You allowed a user to post comment in a zero network conditions. But what if your user wants to post not just one but three consecutive comments. Even though everything is happening locally, you user would still see all of these comments appearing together. He/She for a while even could get confused on “what happened to the previous comments?”.
With the architectures we talked about before, these comments would appear. But they would appear at once, like a snap. Which is sort of a poor user experience and engineering. Why does that happens when you are doing everything locally.
Well, let’s look at the process flow and then see how things are happening. Below is the default queue that your app would use with such an architecture:
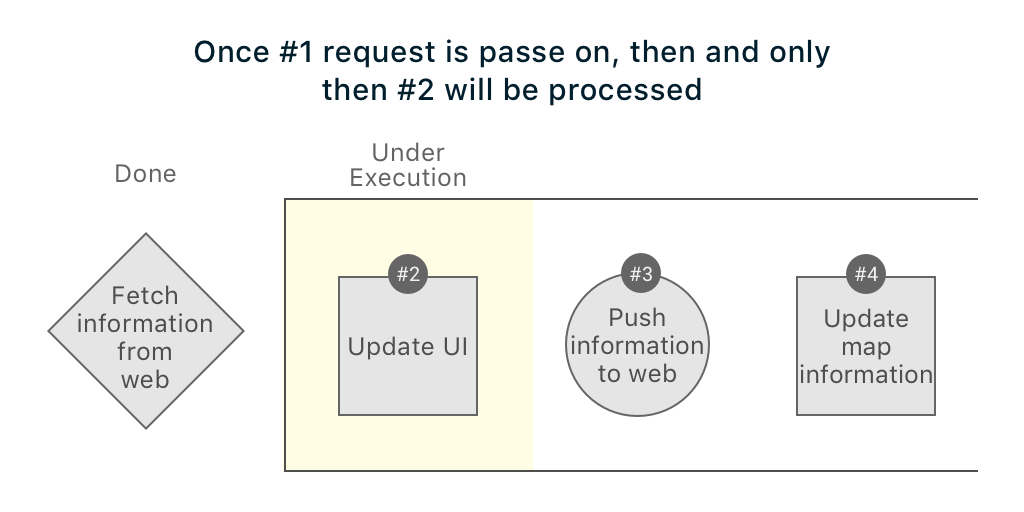
The real problem is with this implementation, what if your network is super slow and the background process queue is waiting for this network to respond while all other local tasks (which should be executed in less 50ms) are still pending.

Let us now split the queues and separate them by network and local queues. Below is how your revamped queues would behave:
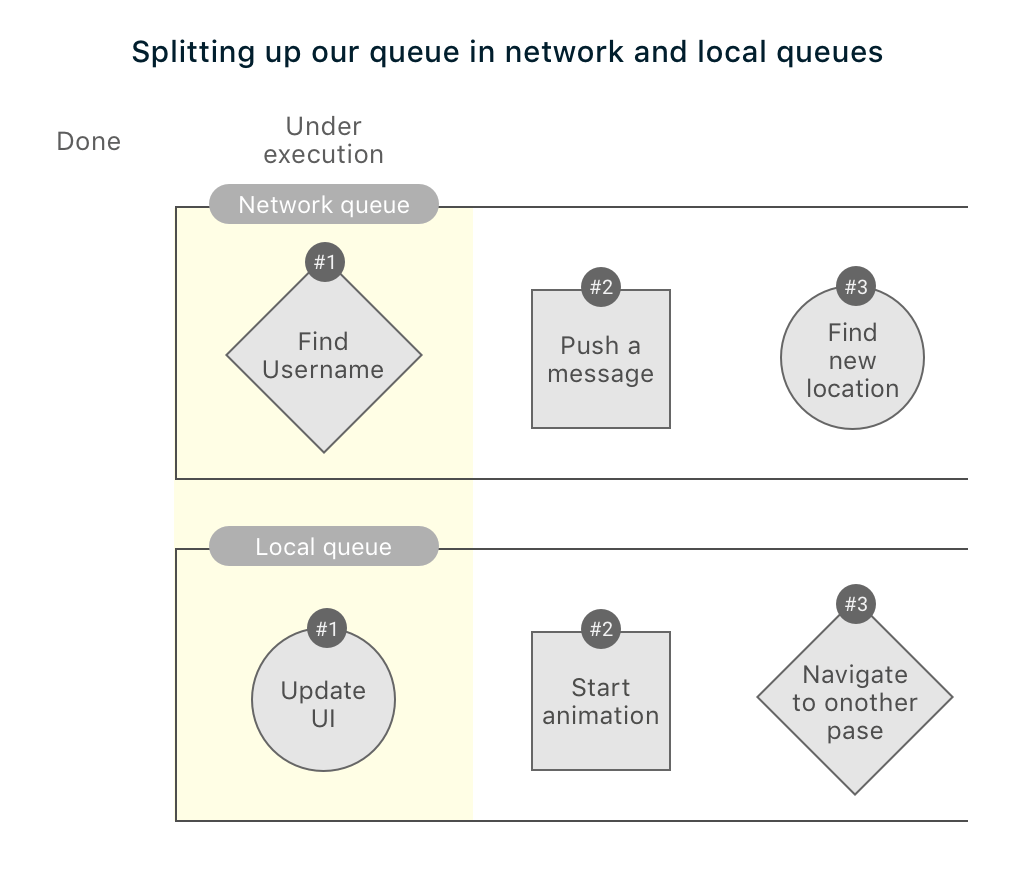
Now, when a user adds comment on a news section, the app won’t behave as it did with the previous use cases. And the comments would show up instantly, directly from the disk.
Evolving Offline Sync Architecture with a Sync Job
Let’s for a minute think about what we have achieved so far. We separated queues to make sure that your app performs super fast, we added persistence to your mobile app. Now, here’s the thing – nothing you will build will be perfect.
The architecture we have so far is can be better characterized by two traits:
- On demand
- Just in time
This is good, it works and handles like 100s of different use cases.
But, we can still make it better.
What if we could add a dedicated “Synchronization service” where you have a program(sync service) that synchronizes changes with the network?
The characteristic of this new system would now be:
- Ahead of time
- Store and forward
Here’s how the offline architecture looks now:
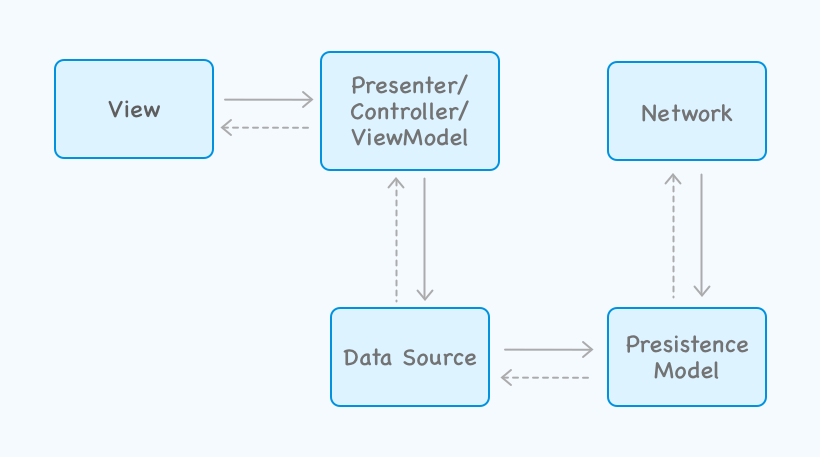
If we try to simplify and show what’s happening under these layers, here’s how it would look
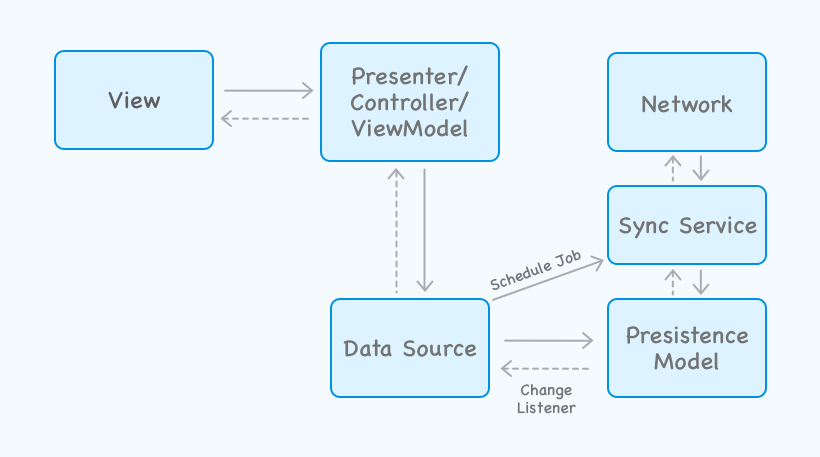
Basically, the last two architectures are the ones that I would personally recommend for most of the app developers. Based on the characteristics, these architectures are better suited for use cases.
What Offline Mobile App Architecture to use, where and why?
On-demand type offline architectures are better suited for:
- Ecommerce apps
- Realtime apps
- News apps
- Map apps
The reason for the preference are pretty straightforward:
- They bring faster data retrieval after sending 1st request
- They handle connectivity better
Note: This is still not what we call a “true offline capability”.
Ahead of time type offline architectures are better suited for:
- Notes taking apps
- Email apps
- Weather apps
- Finance type apps
- Messaging apps
Again, looking into the following factors when when you go for this type of an architecture:
- Fast data retrieval upon multiple requests
- It has complete offline capabilities
- This architecture has no dependency on the UI. It won’t have to check if the UI is active or not. Which is the case in previous (on-demand) architecture
Note: This architecture type gets complicated very fast.
Offline-online Sync – Architectural Considerations
If you still aren’t sure on what offline considerations you should keep with you mobile app (be it Android or iOS), here are some challenges that your offline architecture should support:
- How and where are you going to cache your data?
- How reliable is this caching?
- How is this architecture going to handle concurrency?
- Are there any safeguards in your architecture to handle data conflicts?
- How will this architecture handle connectivity changes?
While, I have covered some, but not all possibilities in offline architectures for mobile apps, I hope the blog post helps you. Feel free to reach out to me via email or drop me a comment if you have any questions.


Igor Ganapolsky
I really appreciated reading your explanation of various caching options. Can you tell me if Firebase DB caching is a viable option?
thedigizones
With the popularity and demand for smartphones and tablets, mobile app development has become a progressively prominent medium of software creation. The app development of mobile enhances business opportunities and gives the users exactly what they need and what you want to give.
Rupinder
Your blog is very effective and glad to read, really it’s pretty awesome and gives lots of valuable ideas for web app development. It will be very useful for Web app developers.
Joseph Samuel
Your article is very helpful and provides great information and this all information it's very helpful for me.
Diego
Great content thanks for sharing your experience
How to Plan an App | 7 Little- Known Visual Strategies to Build an App
[…] Based on your user flows and data needs identified earlier, it’s time to define how the app looks and works. […]
Deepika
Thanks for sharing!
Explorate Global
Hi Hardik, Amazing post! Thanks for sharing.