Maybe your organization was settled on the perfect database model, and you thought it would be static for years, if not decades.
But your predictions didn’t go right!
Like the 99.999% of world organizations, your business is in continuous flux, and you’ve done better than expected. However, change is a new constant and demands frequent iterations to cope with changing customer behavior.
And the fundamental way to confront these challenges of today’s business is the foundation of a solid and flexible data infrastructure.
So, which one is the best DBMS for your business?
This was a question at the center of discussion on Reddit, where several users compared PostgreSQL, MySQL, and MongoDB. As a user points out, “dealing with thousand of live users in a chatroom feature will need an in-memory database which is written periodically on disk.”
Further, the user recommends MySQL for the use cases. However, another user cites buggy MySQL attributes and asks to stay away from it for a new project.
Well, here we are with a comprehensive comparison of MongoDB vs. MySQL. Let’s begin with a brief overview of each DBMS.
What is MongoDB?
MongoDB is a scalable and flexible database platform designed to overcome the shortcomings of NoSQL solutions. It is a DBMS that helps with horizontal scalability and load balancing capabilities. Developed in 2007, the first version was released in 2010 by MongoDB Inc.
MongoDB uses key-value pairs stored in BSON files – a slightly modified version of JSON files. So, all the Javascript gets full support due to BSON. This is why it is best for Node.js projects.
Further, JSON also enables data exchange between web apps and servers in a human-readable format. Besides the BSON advantage, MongoDB has the benefits of auto-sharding, embedding, and data replication. MongoDB is an ideal choice for cloud adoption working as a database-as-a-service(DBaaS),
Key characteristics of MongoDB
- Ad Hoc queries in MongoDB are flexible, providing a schema enabling optimized real-time analytics for enterprise applications.
- Enhanced indexing allows MongoDB to optimize performance and improve query execution speed.
- Data replications allow you to replace the primary node with a secondary one in case of failure.
- Distributed server shards carrying a portion of the dataset forms a single comprehensive database providing higher availability and horizontal scalability.
- Load balancing support by MongoDB enables your systems to handle multiple concurrent read and write operations.
What is MySQL?
MySQL is an open-source relational database management system RDBMS with a client-server model. It allows storing data in rows and tables, which further helps with information classification. In addition, MySQL enhances the reliability of your database infrastructure through master-master and master-slave replications.
A master-slave approach includes dividing the database into master and slave sections. The slave database works as a backup for the master database. Therefore, replication of the master-slave or master-master database approach provides higher reliability.
Key characteristics of MySQL
- A transactional data dictionary allows storing information about the database objects introduced with the MySQL 8.0
- Atomic Data Definition Language (DDL) statements in MySQL combine the data dictionary updates with storage engine operations and binary logs with DDL operations into a single atomic transaction.
- SSL session reuse support that MySQL 8.0 provides helps with cost optimizations as each SSL/TLS exchange has higher costs.
- Controlled data upgrades of the data dictionary and server operations
Now that we know MongoDB and MySQL individually, it’s time to see how they are head-on with each other regarding performance, security, and more.
Comparing performance & speed for MongoDB and MySQL
Organizations don’t just store information in databases. They also need quicker data accessibility for rapid response to user requests. A database combines different information efficiently stored, managed, and updated. CRUD (Create, Read, Update and Delete) operations manage the primary function of persistent storage.
When it comes to CRUD operations, how does MySQL stand up to popular MongoDB?
Let’s check out!
We will discuss a study by Roman Ceresnak and Olga Chovancova from the Central European Researchers Journal in 2019. The experiment was to test the query performance of both MySQL and MongoDB for the body mass index of different people. It helped in measuring a different number of queries and the time needed to execute them.
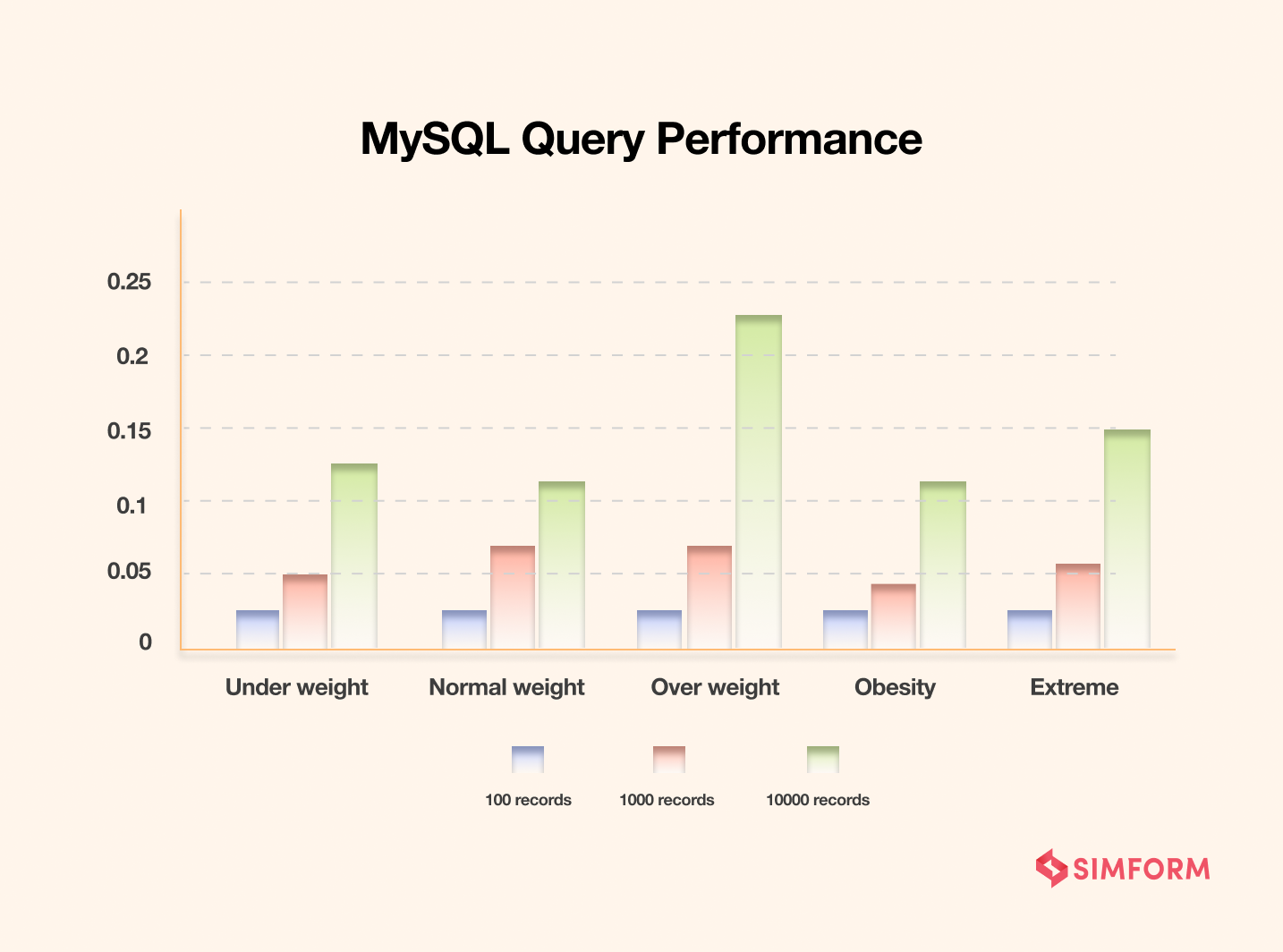
The first iteration of the BMI experiment for the MySQL database shows the query performance in milliseconds. The study needed attributes such as name, surname, height, and weight to compute the BMI index.
As you can see in the graph above, different data are compared based on the time needed to gain their values. In other words, it shows the query execution time for each data in MySQL.
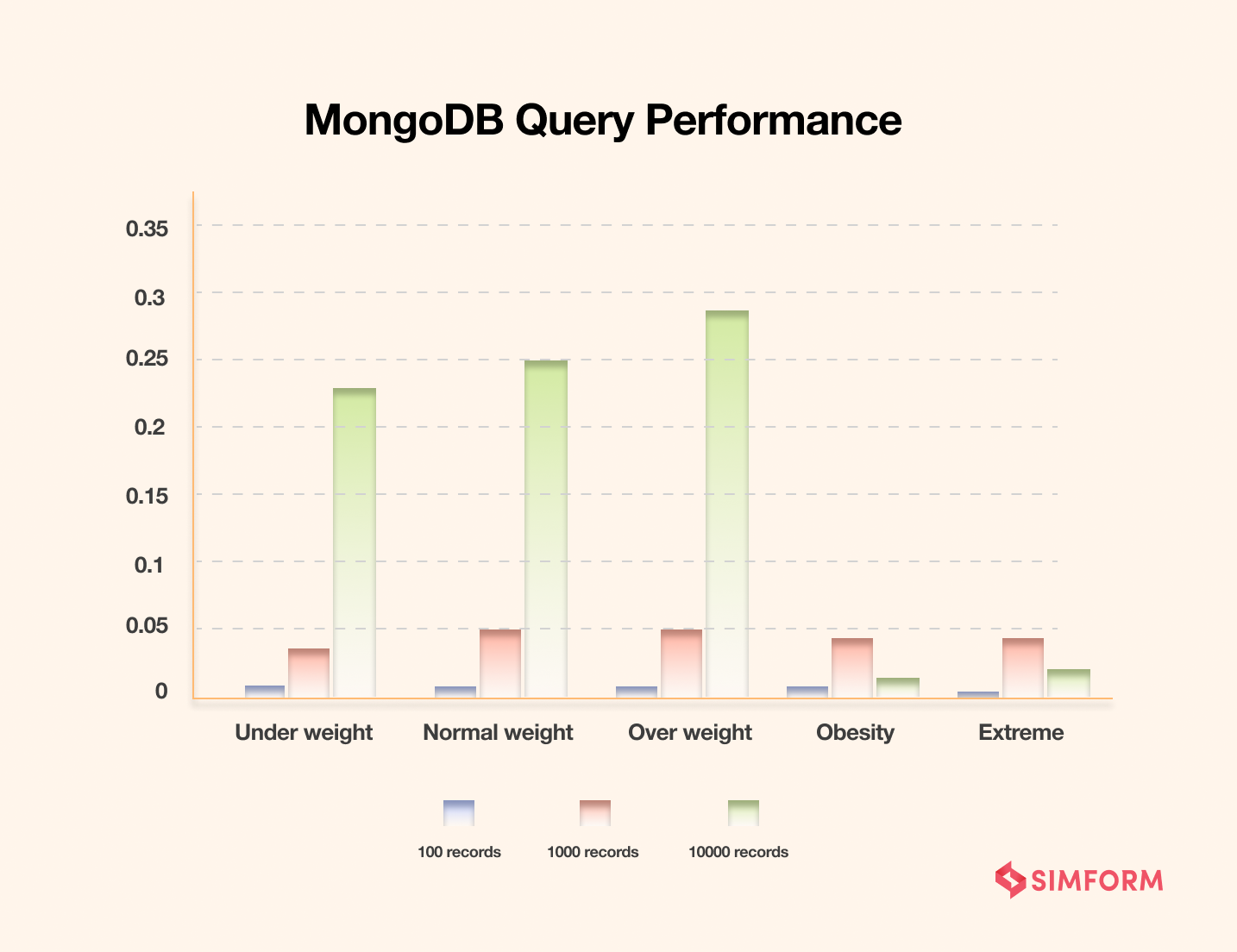
On the other hand, MongoDB results for the same query execution of BMI index data show less time needed. It shows how querying speeds are better in MongoDB in comparison to MySQL. Let’s discuss how they stand in terms of querying.
Query performance: MongoDB & MySQL
Decoding the querying aspect of the two database technologies
One of the critical differences between MongoDB and MySQL querying capabilities is the underlying database technology. For example, MySQL uses Structured Query Language (SQL) for querying, and MongoDB uses Javascript as a query language.
Despite its simplicity, SQL is a potent language that consists mainly of two parts: Data Definition Language (DDL) & Data Manipulation Language (DML). You can use the following commands to query the data in the MySQL database- ‘SELECT,’ ‘UPDATE,’ ‘INSERT,’ and ‘DELETE.’
MongoDB uses Javascript query language, which is unstructured. You must use an extensive set of operators to link several JSON files. Querying in JSON documents requires a document definition with specific results you need.
In other words, you need to define the type of data or information provided when a specific query is executed. But, again, MongoDB makes it simple by implying all the queries to be natively assisted with a special operator – $or.
So, when it comes to querying unstructured data, MongoDB has the edge over MySQL due to support for Javascript querying language.
Querying unstructured data: MongoDB & MySQL
Sharding & replication in MongoDB and MySQL
Sharding is a process of distributing data across multiple databases for enhanced deployments. It allows organizations to support high throughput operations and handle large data sets. It follows the horizontal scaling principle by distributing information across multiple servers, making the entire system highly available and cost-effective.
Replication and sharding in MongoDB
MongoDB supports Ad Hoc queries, replication of data, and sharding. The sharding feature in MongoDB enables distributed data systems for your applications. It uses replica sets to provide data replications. Each replica set is a group of MongoDB instances that host the same data set.
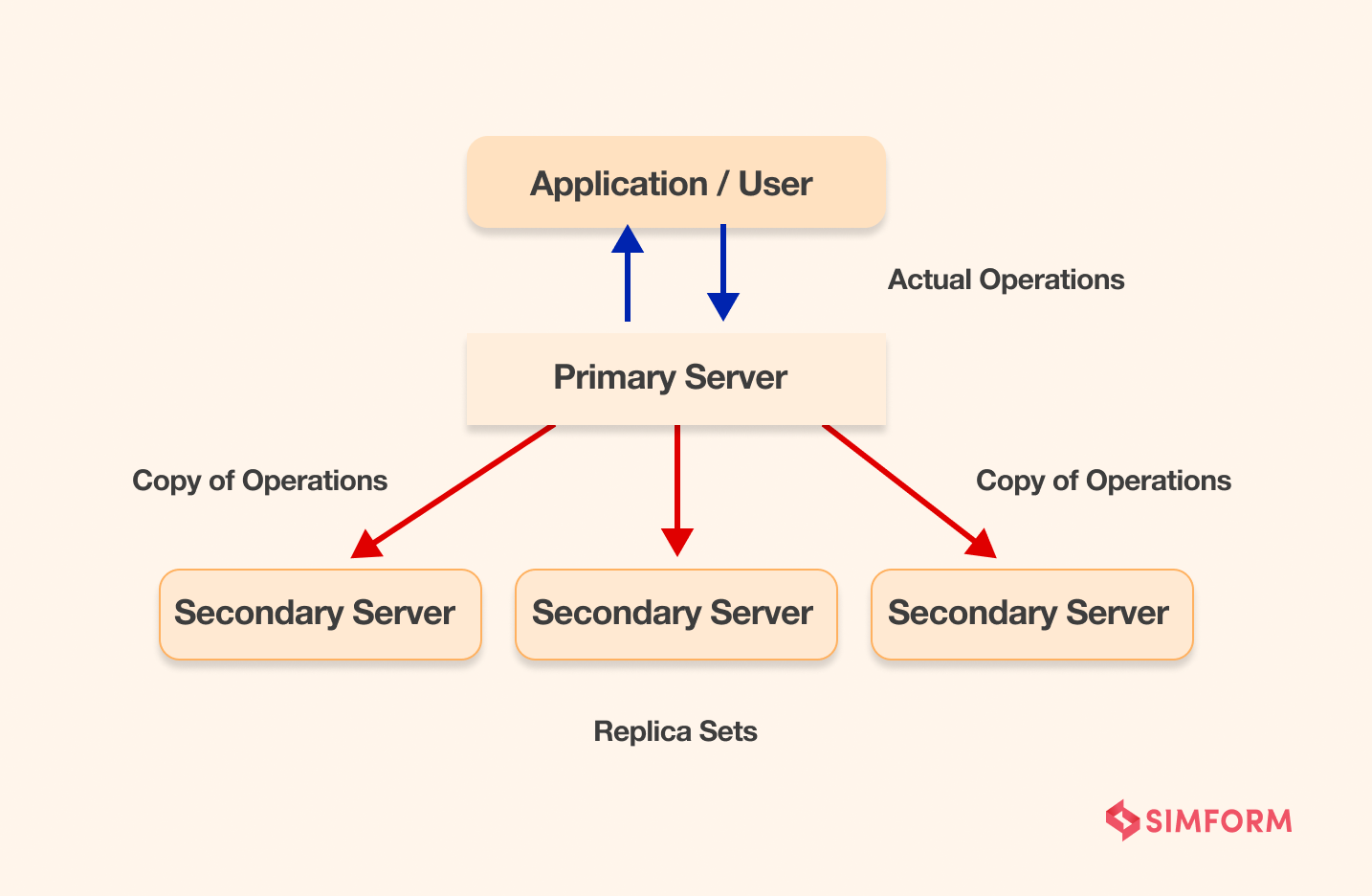
There are two sets of nodes,
- Primary nodes that receive all the operational requests from user
- Secondary nodes that are updated according to primary nodes
If the primary node fails, one of the secondary nodes becomes the primary one. Once the failed primary node recovers, it joins the cluster as a secondary node. This way, MongoDB offers higher availability for your system.
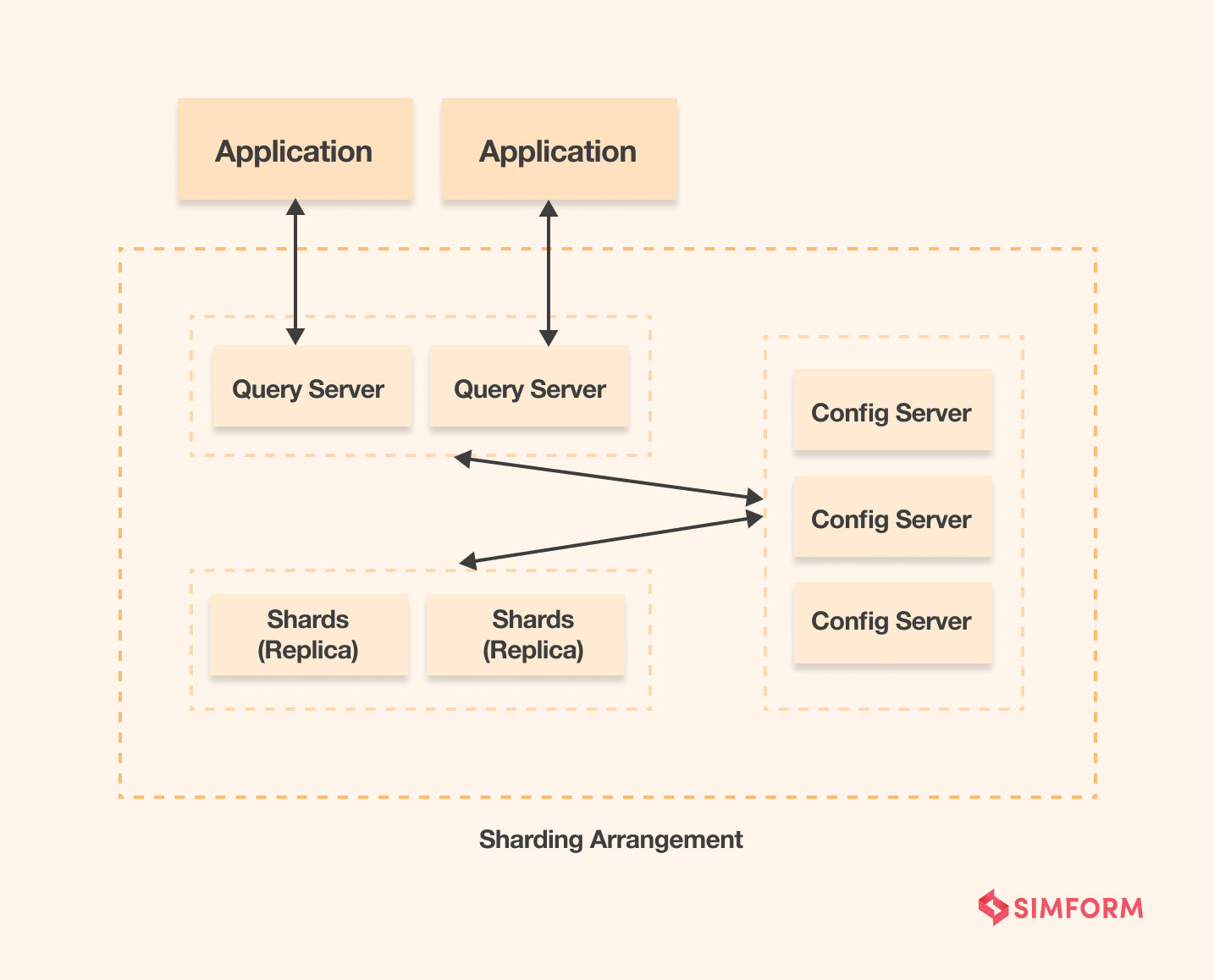
Replication and sharding in MySQL
On the other hand, MySQL also provides data replication through a multi-master approach. However, the multi-master approach requires each application to write to a different master for scaling.
MySQL offers two ways for the sharding –
- MySQL Cluster – built-in automatic sharding functionality
- MySQL Fabric – an official sharding framework
However, tech giants like Facebook and Pinterest have created their sharding frameworks. So you can look to implement a similar approach by creating one for your organization. Sharding is a scale-out approach, and with MySQL, you will have each node with independent MySQL RDBMS. It helps in inducing parallelism, boosting the scale of workload deployment.
Replication & sharding– MongoDB = MySQL
How MongoDB and MySQL perform in terms of security?
Application security is vital for higher customer engagement and conversions. In addition, database platform security aids in improving protection for applications against several cyber threats.
MongoDB uses a role-based access control(RBAC) with a flexible set of privileges. Its security features include authentication, auditing, and authorization. Moreover, it is also possible to use Transport Layer Security (TLS) and Secure Sockets Layer (SSL) for encryption purposes. SSL/TLS ensures that the data access is secure.
On the other hand, MySQL uses a privilege-based security model(PBSM). It authenticates a user and facilitates privileges of access to specific databases such as CREATE, SELECT, INSERT, UPDATE, etc. MySQL also uses encrypted connections between clients and the server using the SSL.
Security– MongoDB = MySQL
Popular use cases for MongoDB
Cisco eCommerce improved page response time and resilience with MongoDB.
Cisco’s eCommerce platform caters to more than 150,000 users across the world. It deals with problems like lack of fault tolerance, downtimes on new code deployments, and lack of higher page response time.
Cisco used MongoDB and conducted pre-deployment testing. The results showed,
- When applied five times the normal peak load, the throughput and latency remained the same.
- MongoDB could self-heal within 2 seconds upon being introduced to a range of failure conditions.
- High resilience without any interruptions with MongoDB’s architecture
Craigslist optimized operations through auto sharding in MongoDB
Craigslist posted more than 1.5 million advertisements daily, storing its data in a MySQL cluster. But this setup lacked flexibility, and management cost was higher. So, Craigslist decided to choose MongoDB. It helped them reduce the cost of schema migrations. Further, Craigslist used MongoDB’s auto sharding to optimize operations and improve data availability.
Bosch used MongoDB to power IoT-based analytics.
Bosch needed a flexible database model to power its IoT suite. One of the pilot projects of the Bosch IoT Suite has been flight data tracking. An application based on the Bosch IoT suite gathers data regarding aircraft for manufacturers that help them get insights on the performance and other metrics.
It records data wirelessly transmitted from the aircraft, including the operator’s detail, battery level, and time-series calibration settings. This is also important for manufacturers to comply with the regulations of the FAA.
Bosch used MongoDB for its SI technology to,
- Manage complex data types
- Support continuous innovation and business agility
- Create a unified view
- Power its real-time analytics based on IoT data
Popular use cases for MySQL
BBC developed an in-house system to monitor content with MySQL
The BBC wanted to work in real-time with a dynamic system that would give audiences a real sense of the news stories on the website. The challenge was balancing the demand for high performance with value-for-money content.
MySQL helped them in building an in-house system. It allowed the BBC to monitor many daily stories read hour by hour. BBC used this system to analyze which story and video have been the top during each hour of the day. MySQL enabled BBC to cater to 35 million unique users and receive over 800 million page impressions monthly.
Twitter’s transition from temporal sharding to distributed database approach with MySQL
Twitter used to store the tweets with an approach of temporal sharding. However, as Twitter scaled, it became difficult to keep up with a high number of tweets through temporal sharding. So, Twitter built a distributed tweet store- “T-bird.” It was built on top of Gizzard using MySQL. Gizzard is an open-source and distributed sharding framework that allows Twitter to improve fault tolerance and data availability.
Uber switched from Postgres to MySQL for enhanced build releases.
Uber used Postgres to power its on-demand applications. However, there were several limitations to Postgres like,
- Lack of architecture for writing operations
- Data replication issues
- Corrupted data tables
- The difficulty of upgrading new releases
Uber switched from Postgres to MySQL to overcome these limitations and improve release time. MySQL supports different types of data replication, allowing faster fetch of information per system requirements. It helped Uber reduce overhead through concurrent connections, spawned with one thread per connection.
When to use MongoDB?
You can prefer MongoDB when,
- You require high data availability with automatic, fast, and instant data recovery
- You are dealing with BigData across multiple geographical locations
- You have an unstable schema and want to reduce schema migration costs.
- Most of your services are cloud-based and need a native scale-out architecture
When to use MySQL?
You can prefer MySQL when,
- You want a DBMS for the small-scale project with a restricted budget
- You have a fixed schema and data structure.
- You are dealing with a high transaction rate.
- Data security is your top priority for choosing the DBMS
Conclusion
To answer the main question of “Why I should use X over Y?” you need to take into consideration your project goals and many other relevant things.
MySQL is highly-organized for its flexibility, high performance, reliable data protection, and ease in the management of data. Proper data indexing can resolve your issue with performance, facilitate interaction and ensure robustness.
But if your data is not structured and complex to handle, or pre-defining your schema is not coming off easy for you, you should better opt for MongoDB. What’s more, if it is required to handle a large volume of data and store it as documents- MongoDB will help you a lot!
The result of the faceoff- one isn’t necessarily a replacement for the other one. MongoDB & MySQL both serve in different niches. For example, we have used both SQL and NoSQL databases for our client’s project called Freewire. Here’s the case study.
So, if you are looking for custom software development with a reliable RDBMS, Simform can help with tailor-made solutions. Contact us for more information.

Andras Szekely
Dear Mihir, Excellent document. I'm just need to decide for an new development, what kind of DB system I'll handle in the future. I will decide MongoDB, but your information is great. My best wishes, András Székely
Abdou ramadan
really nice document thanks for the hard work.😊😊😊
David
In the Performance section the graph shows MySQL is much faster at selects, is that correct?
Anirban
Yeah, it is, Mongo serves best when there is a large amount of unstructured data on the other hand where the data structure is defined and more emphasis is given on data integrity, MySQL serves the best. In other words, both have pros and cons it totally depends on the type of application.
dvvyn
Very good article! Keep up the good work!
Daryll
Mr. Shah, thanks for this amazing article. It really lays clear a lot of the doubts I had about the differences between MongoDB and MySQL. Great Article!
Vivek Mehta
Very Good and detailed explanation.
Luis Andre
Mr. Shah, excellent article, excellent investigation. I am using MySQL right now because it is what my hosting provider gives me but in the future, I would love to implement Mongo. Thank you again.
Joe Drumgoole
MongoDB added ACID transactions in MongoDB 4.0
Mathew
Thanks a lot for this article. I never checked MongoDB because I use MySQL since... ever. Will try it out on my new project because it looks promissor.
Brahim Belghmi
This was helpful, thank you.
Yeveren
good article
Pourya Siyami
It was an interesting article. Now I understand their difference better