In our previous blog, we covered the fundamental aspects of microservices, such as their definition, advantages, disadvantages, and various use cases.
In this part, we’ll delve into the inner workings of microservices architecture. How you can implement it, deploy it, monitor it, and so on.
Let’s start!
How does microservices architecture work?
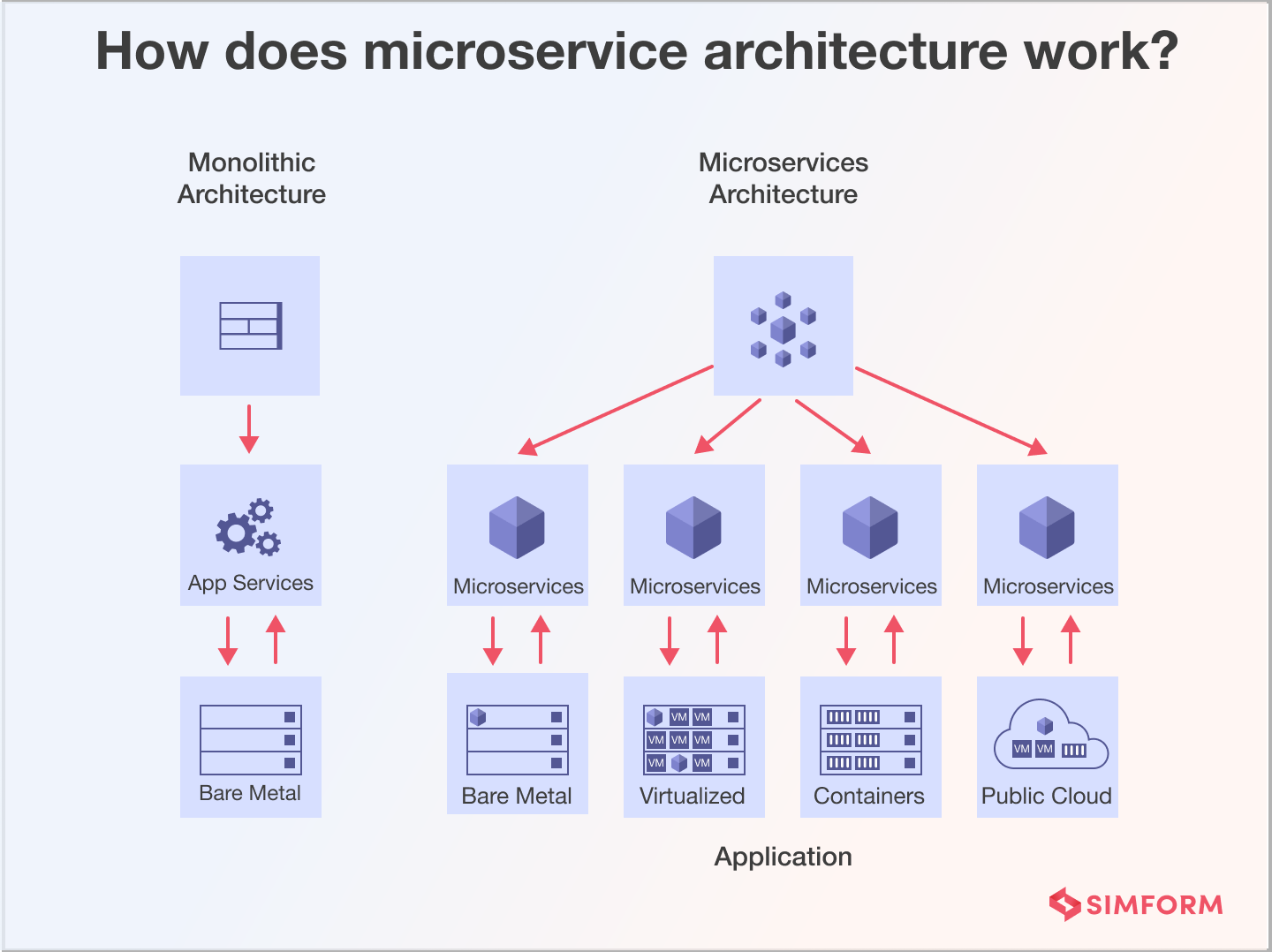
A microservices architecture breaks your monolithic application into a collection of loosely coupled services. Each service focuses on a business capability or domain.
They then communicate through well-defined APIs using RESTful or other lightweight protocols, sometimes using centralized API gateways.
Containers, such as Docker, package and deploy these microservices with container orchestration tools like Kubernetes.
This decentralization allows independent development and maintenance by different teams using the programming languages and technologies that best suit their needs.
Microservices also ensure fault tolerance through techniques such as circuit breakers, retries, distributed tracing, and monitoring and logging for issue detection.
Example of an eCommerce application:
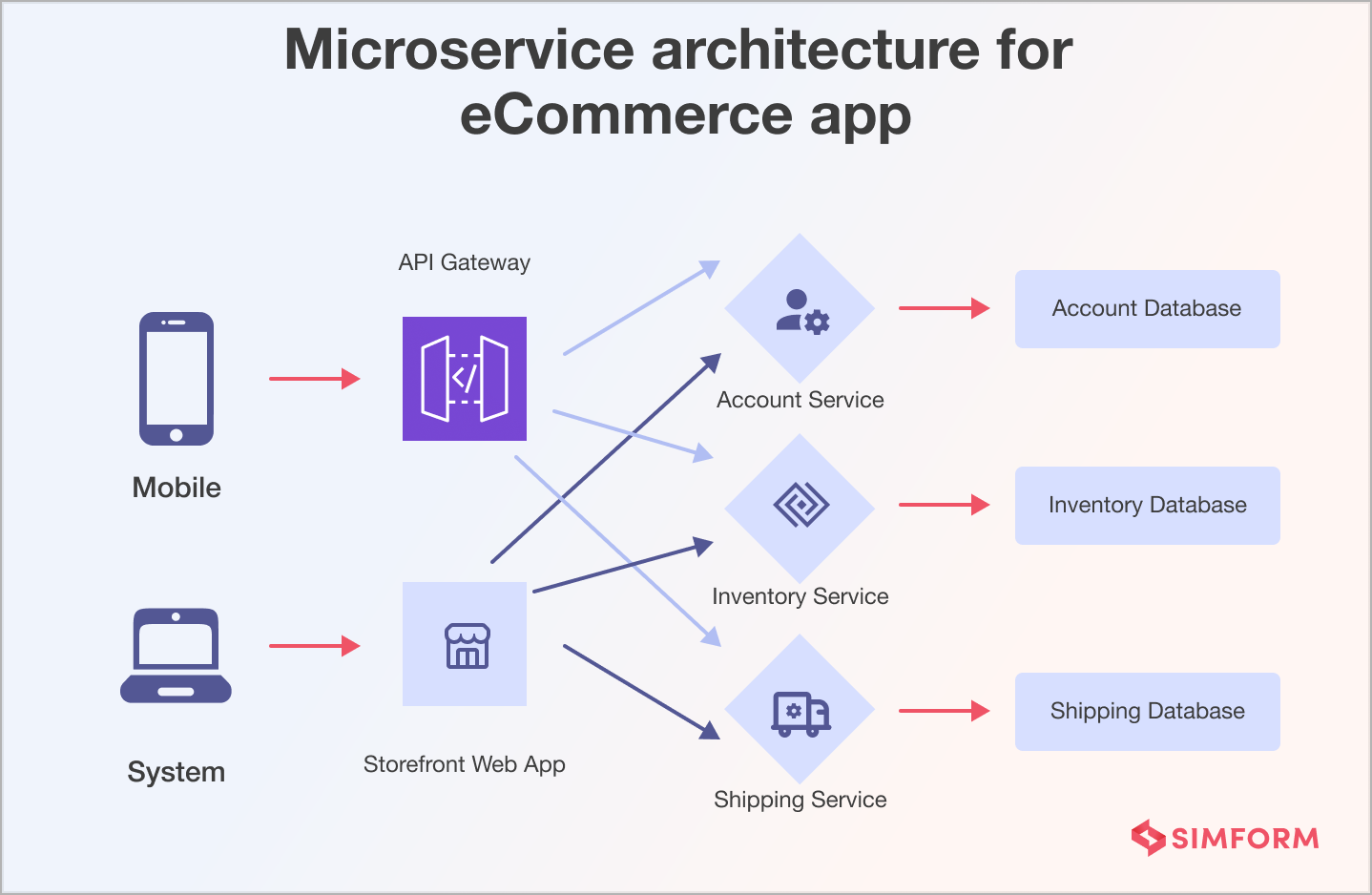
An eCommerce app would have a User Service for authentication and user management, a Catalog Service for product management, an Order Service for order processing, and a Payment Service for payment transactions.
When a user places an order, the Order Service communicates with the Catalog Service to check product availability, the User Service to verify the user’s identity, and the Payment Service to process the payment.
So, if there’s a hiccup in one service, say a temporary issue with the payment processor, the others can keep functioning. The Order Service can still finalize the order and notify the inventory while the payment retries in the background. This modular and decentralized approach helps the system gracefully handle failures, ensuring a seamless shopping experience.
How to implement microservices architecture?
To implement the microservice architecture, consider the four guiding principles:
1. Follow Conway’s law when structuring your application
Conway’s law suggests that your software system’s structure will mirror your development team’s communication patterns. It means organizing your services around your team’s natural boundaries and communication paths in microservices.
For example, if you have a large cross-functional team, you might structure your microservices architecture pattern to align with the responsibilities of these teams. It can lead to better communication, collaboration, and shared understanding among team members, which, in turn, will result in more efficient and effective development.
2. Avoid ending up with accidental monoliths
One common pitfall in a microservices architecture is inadvertently recreating a monolith by tightly coupling your services. To prevent this, maintain loose coupling between services and resist the temptation to share too much logic or data. Each service should be independently deployable and maintainable.
3. Refactor your monolithic application with service objects
It’s often wise to incrementally refactor your existing codebase if transitioning from a monolithic architecture to microservices. Service objects can help you with this. Break down monolithic modules into smaller, reusable service objects that encapsulate specific functionality. It makes it easier to replace monolithic components with microservices gradually.
4. Design smart endpoints and dumb pipes
Microservices should communicate efficiently, but communication should be simple and transparent. So, design smart endpoints that are responsible for processing requests and responses. At the same time, the communication between them (the “pipes”) should be as straightforward as possible, such as using HTTP/REST or lightweight message queues.
Moreover, prioritize continuous monitoring, automate testing, embrace containerization for scalability, and foster a culture of decentralization. Additionally, stay updated on emerging technologies and best practices in microservices to ensure your architecture evolves effectively.
How to deploy microservice architecture?
You can deploy a microservice architecture with single machines, orchestrators, containers, serverless functions, and more. No matter the way, follow a structured approach that ensures reliability, scalability, and agility, such as these six essential steps:
Steps to deploy microservice architecture
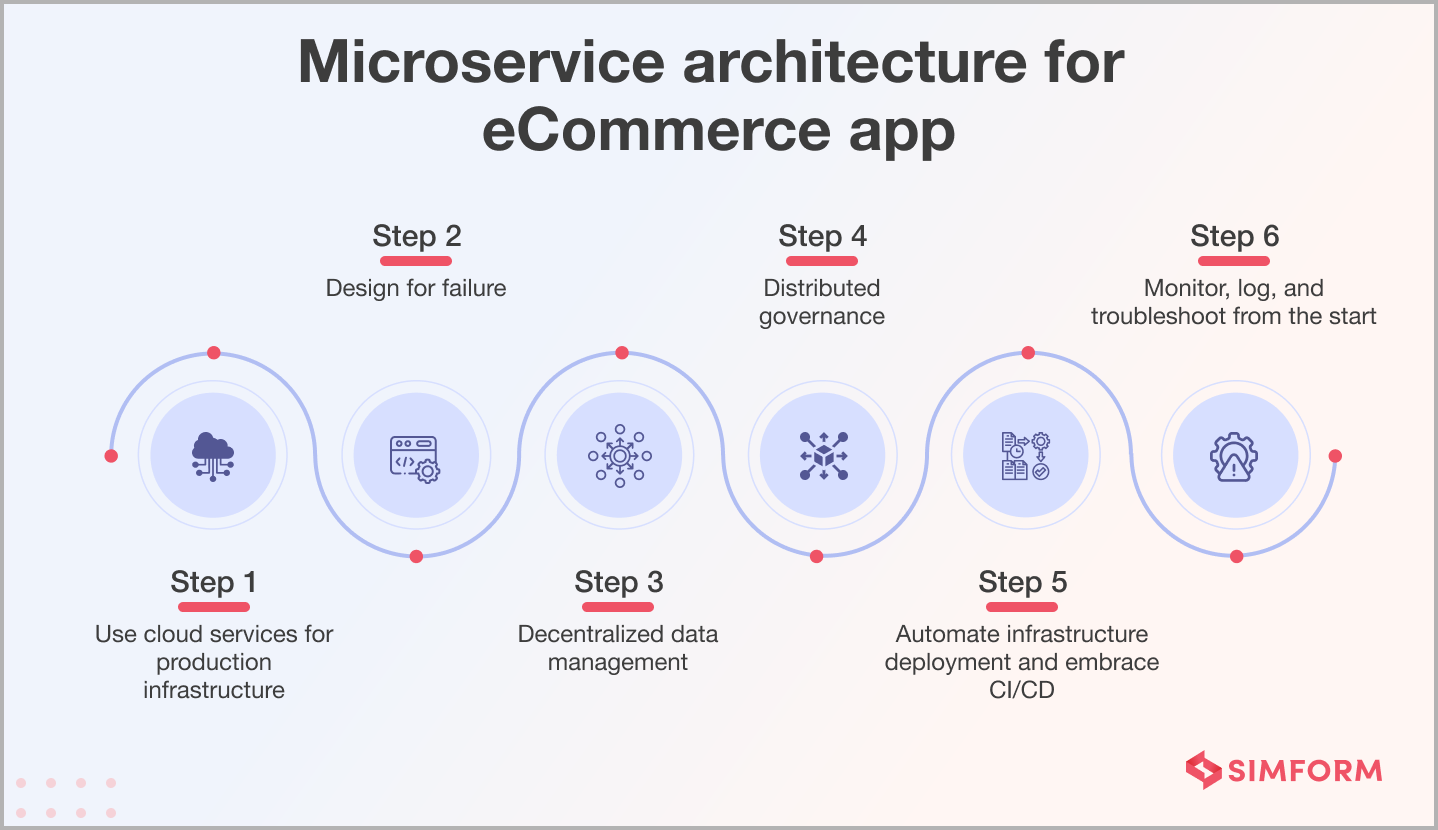
Step 1: Use cloud services for production infrastructure
Consider utilizing cloud platforms like AWS, Azure, or Google Cloud for your production environment. These services provide scalable, reliable infrastructure, eliminating the need to manage physical servers. You can quickly provision resources and leverage cloud-native tools for seamless deployment and management.
Step 2: Design for failure
In a microservices architecture, failures are inevitable. Design your services to be resilient rather than trying to prevent them entirely. Implement redundancy and failover mechanisms so that when a service goes down, it doesn’t bring down the entire system. This approach ensures uninterrupted service availability.
Step 3: Decentralized data management
Each microservice should have its own data store, preferably a database tailored to its needs. Avoid monolithic databases that can create dependencies between services. Decentralized data management ensures that changes to one service’s data structure won’t impact others, enhancing agility and scalability.
Step 4: Distribute governance
Distribute governance responsibilities across your development teams. Empower each group to make decisions regarding their microservices, including technology stack, API design, and scaling strategies. This approach fosters autonomy, accelerates development, and ensures findings align with service-specific requirements.
Step 5: Automate infrastructure deployment and embrace CI/CD
Leverage automation tools like Kubernetes, Docker, and Jenkins to streamline your deployment pipeline. Implement continuous integration and continuous deployment (CI/CD) processes to automate testing, building, and deploying microservices. This automation accelerates the release cycle and minimizes the risk of human error.
Step 6: Monitor, log, and troubleshoot from the start
Start monitoring and logging your microservices right from the beginning. Use monitoring and observability tools like Prometheus, Grafana, and ELK Stack to collect and analyze your services’ performance data. Effective monitoring lets you identify issues early, troubleshoot efficiently, and continuously optimize your microservices.
Ways to deploy a microservices architecture
When you’re planning to deploy a microservices architecture, you have several options at your disposal. Each option offers a unique approach to hosting and managing your microservices, and choosing the right one depends on your specific needs and the nature of your application.
Option 1: Single machine, multiple processes
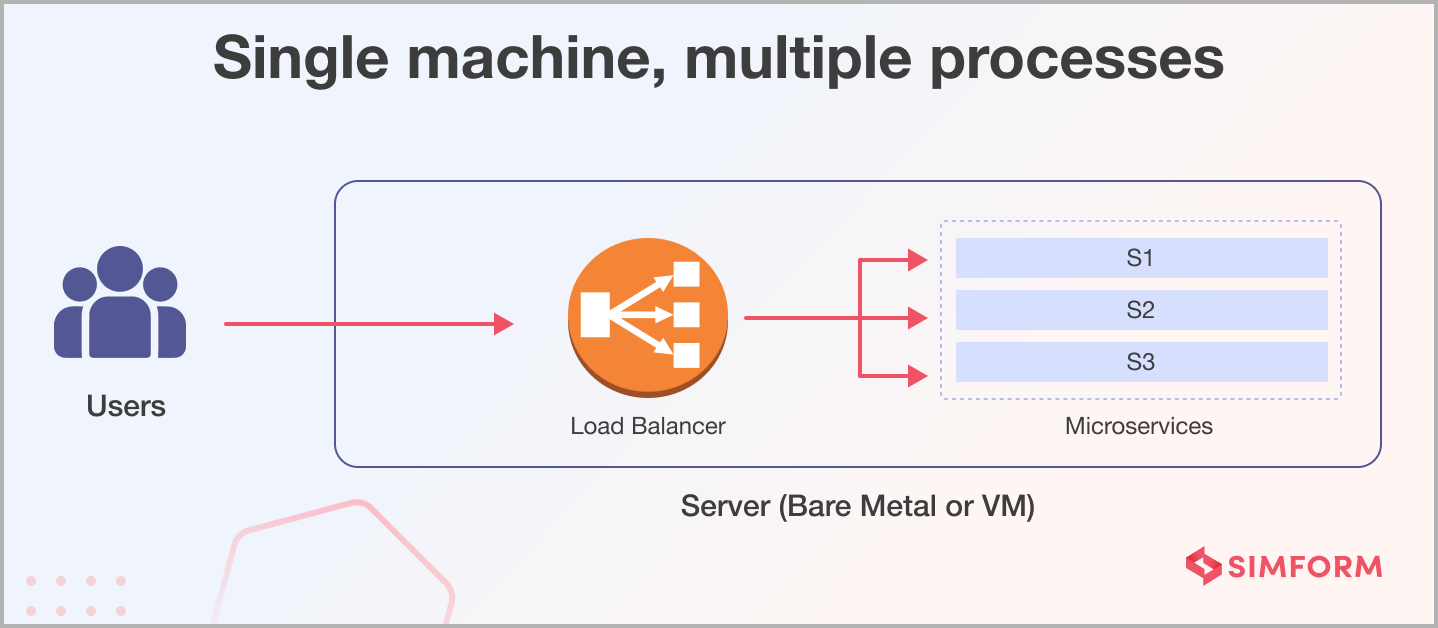
Imagine your microservices running on a single machine, each as a separate process. This option is a straightforward approach to deploying microservices. It’s suitable for small-scale applications and can be cost-effective. However, it has limitations in terms of scalability and resilience. The entire system can halt when the machine experiences issues or becomes overwhelmed.
Option 2: Multiple machines and processes
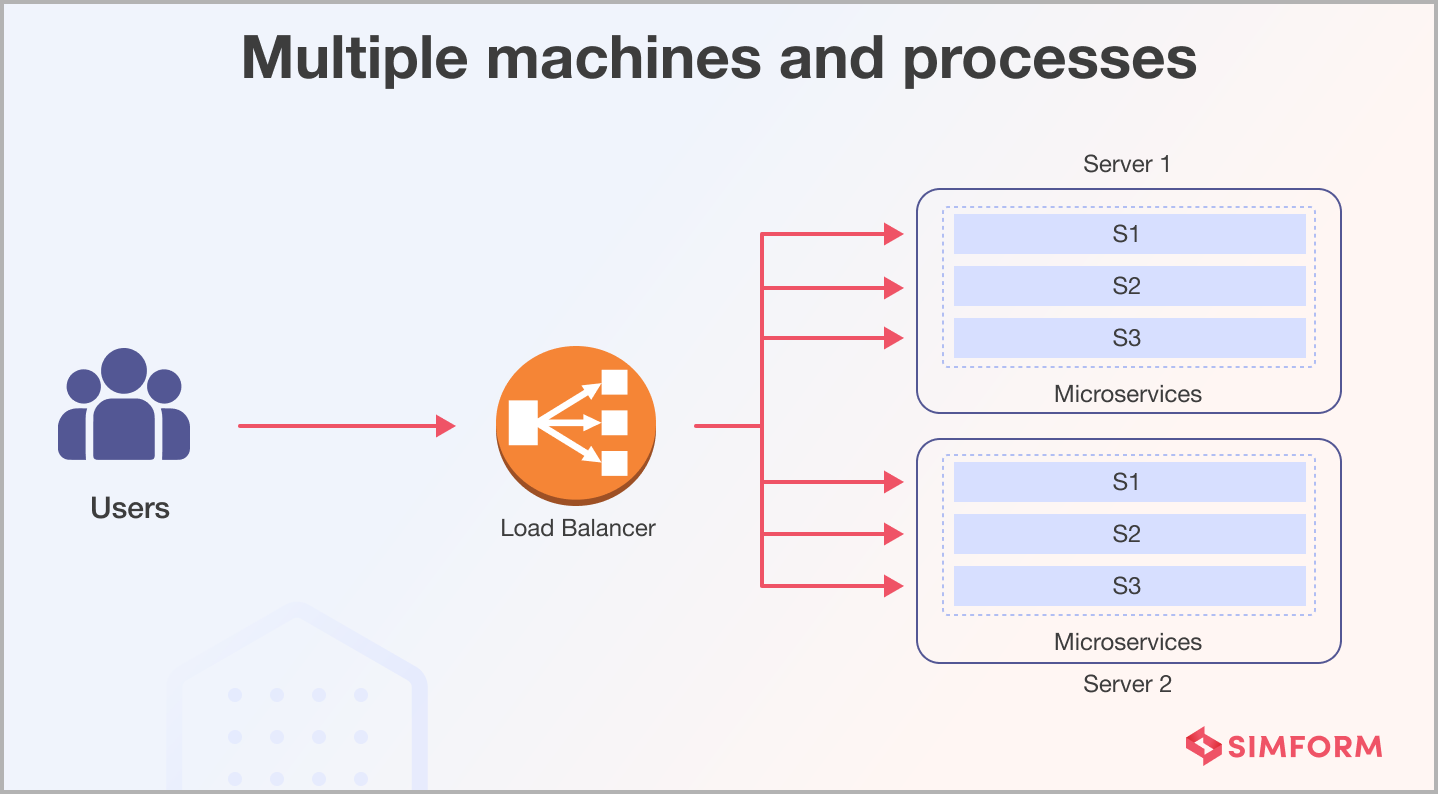
To address the limitations of the single-machine approach, you can deploy your microservices across multiple machines. Each microservice runs as a separate process on its server. This approach improves scalability and reliability, making it suitable for larger applications. Implementing load balancing is essential to distribute traffic evenly across the microservices and maintain high availability.
Option 3: Deploy microservices with containers
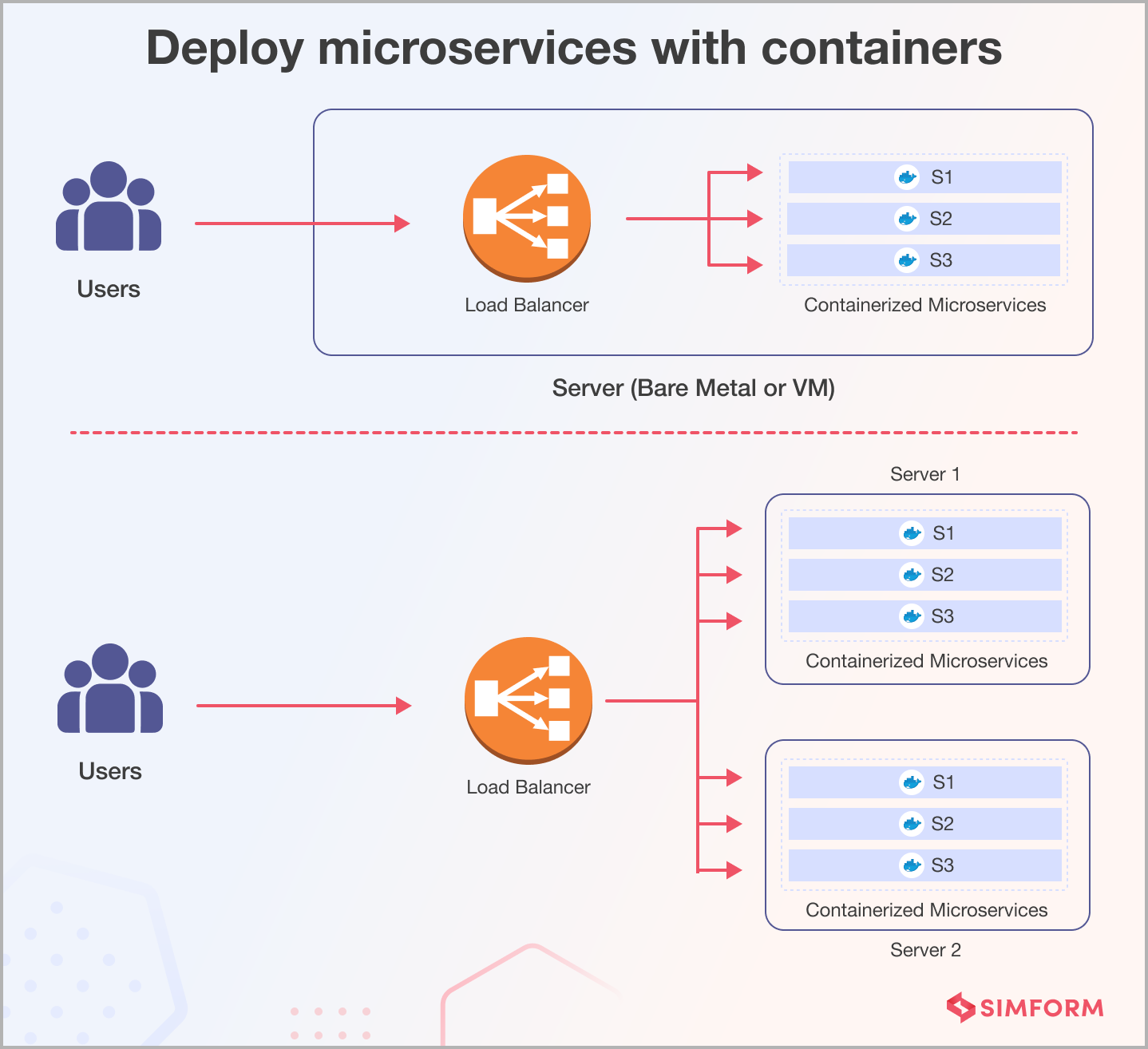
Containers, such as Docker, have revolutionized microservices deployment. With containerization, you can package each microservice and its dependencies into a lightweight, consistent environment. This approach ensures that your microservices are isolated from each other, making it easier to manage, scale, and deploy them across various environments. Containers are also portable so that you can run them on different cloud providers or on-premises servers with minimal changes.
Option 4: Deploy microservices with orchestrators
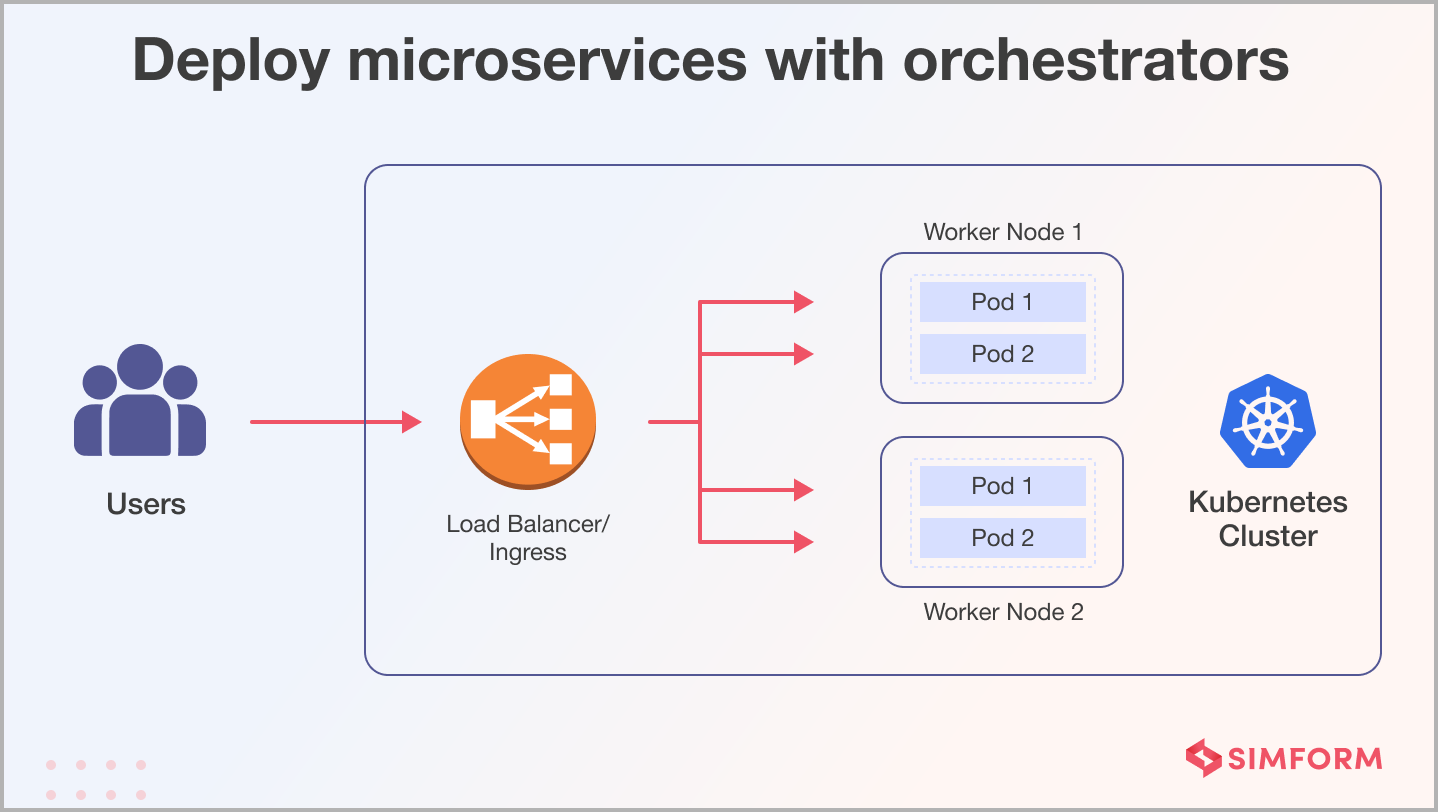
Container orchestration platforms like Kubernetes offer a powerful solution for deploying and managing microservices at scale. Orchestrators help automate the deployment, scaling, and load balancing of microservices. They provide advanced features like self-healing, rolling updates, and service discovery, making managing many microservices more manageable. Kubernetes, in particular, has become the de facto standard for container orchestration.
Option 5: Deploy microservices as serverless functions
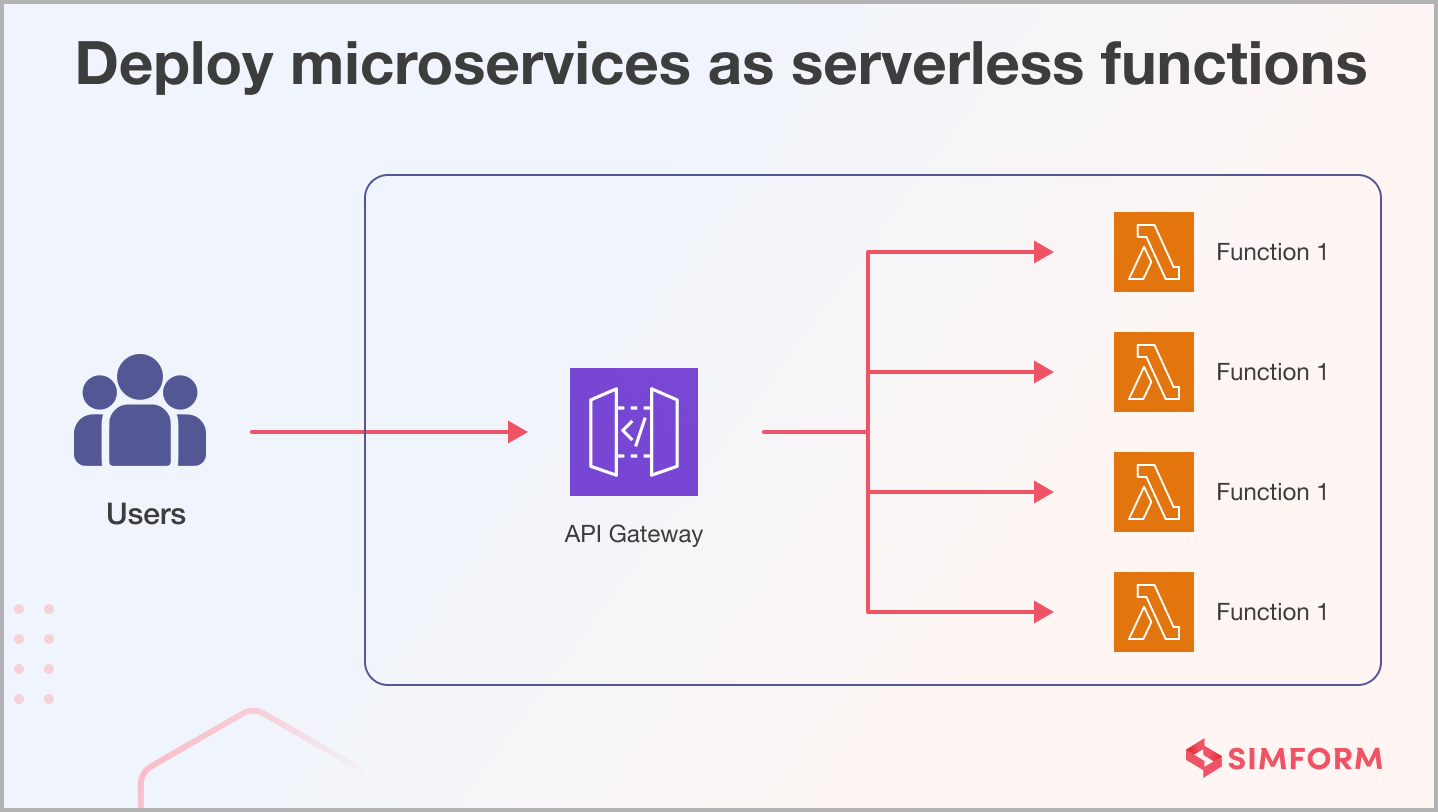
Popularized by platforms like AWS Lambda, serverless computing allows you to deploy microservices as individual functions that automatically scale with demand. This approach eliminates the need for managing infrastructure and ensures cost efficiency by only charging you for the resources used. While serverless is an attractive option for specific workloads, it’s unsuitable for all applications. Consider latency, execution limits, and the stateless nature of serverless functions when deciding whether to go serverless.
And, as you deploy your microservices architecture, monitor your system’s ongoing health and performance to ensure seamless operations.
How to monitor microservice?
Start with containers, then look for service performance, APIs, multi-location services, and other parts. To effectively monitor microservices, adhere to the below-mentioned fundamental principles:
1. Monitor containers and what’s inside them
In microservices, organizations often containerize applications using technologies like Docker or Kubernetes. Monitoring these containers is fundamental. So, keep track of resource utilization (CPU, memory, network), container health, and the processes running inside. It allows you to spot potential issues early on.
2. Alert on service performance, not container performance
While monitoring containers is essential, the ultimate goal is ensuring that the services hosted within these containers perform as expected. Instead of being overwhelmed with alerts from individual containers, focus on high-level service-level indicators such as response times, error rates, and throughput. It provides a more accurate reflection of the user experience.
3. Monitor elastic and multi-location services
Microservices architecture enables services to scale and distribute across multiple locations dynamically. Therefore, ensure your monitoring solution can track service instances wherever they may be, whether in a data center, cloud, or on edge. Next, measure elasticity regarding auto-scaling events and location-aware monitoring for uniform performance across various regions.
4. Monitor APIs
In microservices, communication often happens through APIs. So, monitor the performance and reliability of these APIs. Track response times, error rates, and usage patterns to identify bottlenecks, misbehaving services, or any external dependencies causing slowdowns or failures in your microservices ecosystem.
5. Map your monitoring to your organizational structure
Different teams often manage microservices in larger organizations. Each team may have ownership of specific microservices or service clusters. So, create a monitoring strategy that reflects your organizational structure. Implement role-based access controls so each team can monitor and troubleshoot their services without impacting others.
What to monitor in microservices? (key metrics)

Tools to monitor microservices
Monitoring microservices is crucial for ensuring the reliability and performance of complex distributed systems. Here are the top 10 tools to help you supervise your microservices.
Challenges (and best practices) to implement microservice architecture
Implementing a microservice architecture requires g effective communication, complexity management, and orchestrating service interactions. Here’s how you can overcome these challenges.
Challenge 1: Service coordination
Coordinating the services in a microservices architecture can be complex due to the system’s distributed nature. Each microservice operates independently, with its codebase and database, making it essential to establish effective communication between them.
Solution: Use API gateways
API gateways provide a central entry point for clients, simplifying service communication. They handle request routing and can perform tasks like load balancing and authentication. This practice centralizes the routing logic, easing developers’ service discovery burden. API gateways can also help with versioning and rate limiting, enhancing the user experience.
Challenge 2: Data management
Each microservice often maintains its database, which can lead to data consistency and synchronization issues. Ensuring that data is accurate and up to date across all services can be complex. The need to manage transactions and maintain data integrity between services becomes critical.
Solution: Execute event sourcing and CQRS
Event sourcing involves capturing all changes to an application’s state as a sequence of immutable events. Each event represents a change to the system’s state and can be used to reconstruct the state at any point in time. By storing these events and using them for data reconstruction, you can maintain data consistency and simplify synchronization.
Command Query Responsibility Segregation (CQRS) complements this approach by separating the read and write data models. This allows for specialized optimizations and improved data consistency.
Challenge 3: Scalability
While the architecture promotes horizontal scaling of individual services, ensuring dynamic scaling, load balancing, and resource allocation to meet changing demands without overprovisioning resources becomes challenging.
Solution: Utilize containerization and orchestration
Containerization, facilitated by technologies like Docker, packages each microservice and its dependencies into a standardized container. Orchestration tools, such as Kubernetes, manage these containers, automatically scaling them up or down in response to varying workloads. This combination simplifies deployment and scaling, making it easier to adapt to changing demands.
Challenge 4: Monitoring and debugging
With numerous independent services communicating, it’s challenging to monitor individual services’ health, performance, and logs and to trace the flow of requests across the entire system. Debugging issues that span multiple services, identifying bottlenecks, and diagnosing performance problems become more complex in such a distributed environment.
Solution: Incorporate centralized logging and distributed tracing
Centralized logging tools collect log data from various services into a single location. It allows for easier monitoring and debugging, as developers can access a unified log stream for all services.
Distributed tracing tools enable the tracking of requests across services, offering insights into the flow of data and the ability to identify bottlenecks or errors. These tools provide an effective way to diagnose issues, optimize performance, and ensure reliability.
Challenge 5: Security
Each service may expose APIs for interaction, making it essential to ensure the security of both the services themselves and the communication between them. As services interact across a network, potential vulnerabilities, including data breaches, unauthorized access, and denial-of-service attacks, must be addressed effectively.
Solution: Implement OAuth 2.0 and JWT
OAuth 2.0 is an industry-standard protocol for secure authentication and authorization, ensuring that only authenticated users and services can access sensitive data. JWTs, on the other hand, are compact, self-contained tokens that transmit information between services securely. These technologies enhance security by enabling controlled access and secure data transmission.
Till now, you have learned how microservices work and how to tackle their implementation challenges, but should you use microservice architecture for your project? Find your answer below.
When should you and when should you not use microservice architecture?
Use microservice architecture
- When your application needs to scale independently, allowing each component to grow or shrink based on its demands.
- When you want to enable multiple development teams to work concurrently on different microservices.
- When different parts of your application require varied technologies, allowing each microservice to use the most suitable tools.
- When you need to isolate failures and maintain system reliability.
- When you aim for a streamlined CI/CD pipeline, facilitating quicker updates and bug fixes.
- When you have cross-functional teams that can take ownership of specific microservices.
Do not use microservice architecture
- When you’re dealing with small-scale applications with minimal complexity.
- When you have limited resources or a small development team.
- When migrating from a monolithic legacy system would be cost-prohibitive or risky.
- When dealing with applications heavily reliant on data consistency and transactions.
- When your project demands stringent security and compliance requirements, these can be challenging to implement across numerous microservices.
Role of microservice architecture in DevOps
In DevOps, microservice architecture enhances agility and efficiency throughout the software development lifecycle. It empowers you to break down large, monolithic applications into smaller, independent services. This granularity facilitates rapid development, deployment, and scaling, enabling seamless integration of new features and updates.
Thus, the adoption of microservices is sweeping across industries to achieve improved scalability, fault tolerance, and faster time-to-market.
Adopting microservices is not just a trend; it’s a powerful strategy transforming the future of software development in various domains.
