Quick Summary :- Efficient configuration of AWS Lambda functions is highly critical when you're expecting an optimal performance of your serverless applications. This blog discusses potential serverless performance bottlenecks and ways through which you can finetune AWS Lambda performance.
At Simform, we’ve seen some remarkable and exponential client growth. Months over months, the number of software development projects that we are handling is growing at an exponential rate. As we move into this article, you’ll discover that predicting the performance of AWS Lambda systems is quite a difficult job, especially for lower-memory functions. And hence, in this blog, we’ll try to set some concrete benchmarks, or AWS Lambda best practices, which you can use to configure the AWS Lambda performance.
Well, with some serverless vendors, you have the limit for choosing the memory from 128 MB to 1308 MB while some vendors select the memory automatically according to your function.
This leaves the question of how to choose the optimal memory size for your functions. What I have observed is that simply choosing the memory size that sufficiently runs your function isn’t going to work.
Let’s take the example of AWS Lambda. Lambda provides you with a single dial to allocate the number of computing resources (RAM) to your function. This RAM allocation also impacts the amount of CPU time and network bandwidth received by your function.
It helps to optimize AWS Lambda performance and data-driven cost.
It is easy to integrate with the continuous integration and development pipeline.
AWS Lambda power tuning optimizes the cost for Lambda functions and performance in data-driven functions.
This mechanism invokes functions with multiple power configurations, analyzes the execution logs followed by the best optimal suggestion about minimizing cost or enhancing the performance.
Well, the noteworthy point here is that you should test your lambda functions at all available resources levels so as to determine the excellent level of price/performance for your application. You will observe that the performance level of your functions will increase logarithmically over time.
The limits that you’ll set initially will be working as base limits. As you move on, you’ll come across a resource threshold where any additional RAM/CPU/Bandwidth available to your functions no longer provides any significant performance gain.
However, the prices of lambda functions increase linearly with the increase in computing resources. And that is why your test should be able to determine the logarithmic function bend to choose the excellent configuration of your function.
Performance Results
In an experiment conducted by Alex Casalboni, it was observed that for Two CPU-intensive functions, using the AWS Lambda Power Tuning mechanism results in faster and cheaper experience.
Execution time goes from 35s with 128MB to less than 3s with 1.5GB, while being 14% cheaper to run.
Conclusion
Though there is no significant performance gain after 512 MB for this and hence the additional cost per 100 ms now drives the total cost higher. This means, 512 MB is the optimal choice for minimizing total cost.
Language & runtimes
It could be a concern of everybody whether the chosen language will perform best for functions or not! Let’s see what users from around the world have to say about language runtime performance!
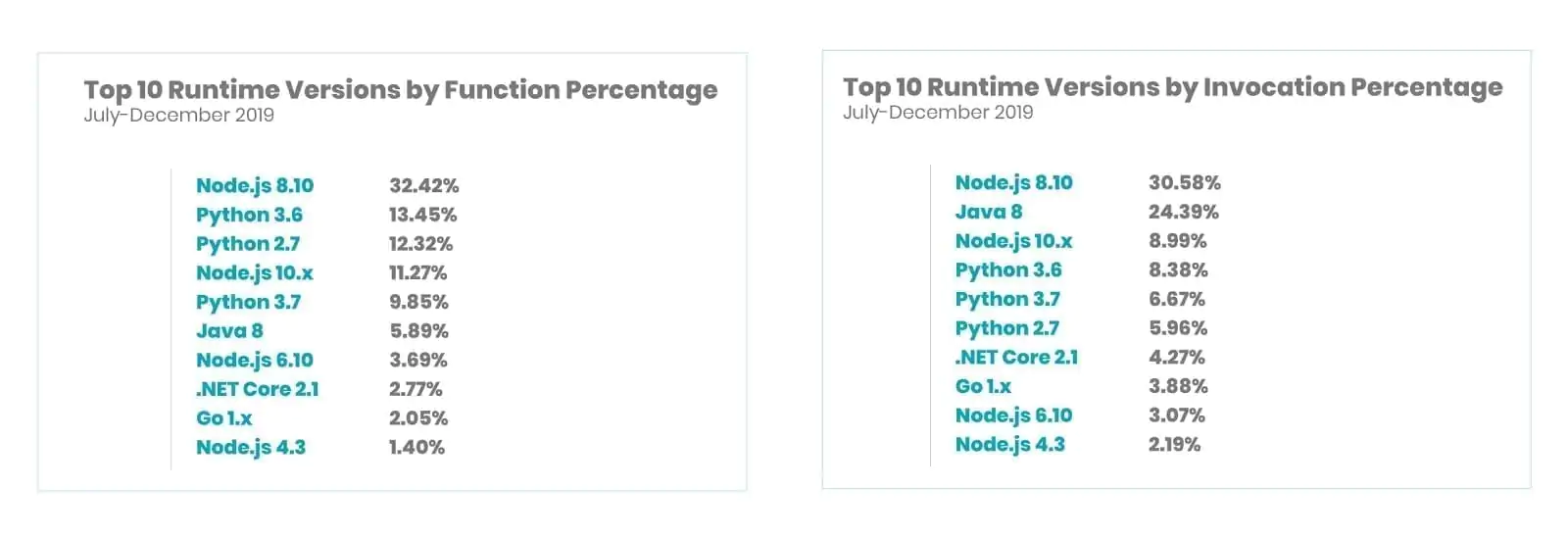
While observing language runtimes for AWS Lambda, the functions monitored for Nodejs and Python were at 52.53 and 35.84 percentages, while invocations monitored in both languages were at 44.96 and 21.01 percentages. NewRelic observed that functions with substantial volume run on versions 6.10 in Nodejs and Python 2.7 and even older versions.
The below graph shows the differences between the percentage of runtime values for different languages Nodejs, Python, Java, Ruby, and .NET.
Pro tips:
Choosing a language for functions is dependent on your comfort and your resources.
But if the performance is the driving considerations, then you need to closely map out the performance characteristics of the languages you’re interested in and then choose the best one from them.
If your application may come across very spiky traffic or very infrequent use, we recommend one of the best languages. If your application does not experience large peaks or valleys within its traffic patterns or does not have user experiences blocked on function response times, we recommend you choose the language you’re already most comfortable with.
AWS Lambda Performance: Provision Concurrency
For any basic application, multiple functions are going to execute transactions at the same time. Each transaction will perform various functions and may be separated only by microseconds. To the users, the operations appear concurrent.
Concurrency is one of the most critical performance issues which you need to monitor closely. Otherwise, your data is vulnerable to undesirable effects on reads and access to uncommitted data.
With the announcement of provisioned concurrency, the concurrency issues in AWS Lambda are addressed and have significantly improved the performance results. Let’s discuss it!
Announcing Provisioned Concurrency in AWS Lambda:
For events like Super Bowl and Black Friday, applications experience a massive spike in users’ visits. However, the unpredictability of affairs could not be measured with human efforts. It could be an unexpected application failure or flooding of hundreds of concurrent requests.
As we all know, servers are the most dominant parts of the event, which helps in reducing the load and ease the performance. While serverless architecture only accounts for money for compute time, AWS Lambda is one of the best options to choose for high-level scalability of application performance.
AWS provisioned concurrency addresses such unexpected application behavior that results in significant failures. These concurrencies help apps to be ready to fight and respond to such events in seconds.
Here are the critical performance aspects offered in the provisioned concurrency by AWS Lambda:
Provisioned concurrency takes significant control over the Lambda functions to help reduce start-up times.
Access to AWS management console, Lambda API, and Application autoscaling made it possible to enable and disable the concurrency requests as per the requirements.
New pricing dimension, paying only for the number of times concurrencies configured and used for the time being.
Provisioned concurrency works well with current run times and functions.
Start ups times per Language
As we’ve discussed this inherent drawback in my previous blog about Serverless Architecture, I’ll just brief you on it.
A cold startup occurs when you execute an inactive function for the first time. This happens when your cloud service provider provisions the runtime container selected by your function and then runs it. This process is popularly referred to as a ‘cold start’ and is known for increasing your execution time.
A typical scenario of cold start duration per language:
It was observed that the startup time for Javascript is at a peak between 0.2 to 0.4 seconds, while for Python, it is 0.2 to 0.25 seconds.
Cold start durations of AWS Lambda in Go and Java showed its spike between 0.3 to 0.4 seconds and 0.34 to 0.4 seconds. Whereas the language Ruby and C# showed a different set of numbers varying from 0.24 to 0.3 for Ruby and 0.6 to 0.7 for C#.
Hence, 67% of the durations are in darker ranges, which is the most common scenario, while the lighter fields include 95%.
The performance of your serverless application is hugely dependent on the logic you need the cloud function to execute and what the dependencies are. The serverless developers should understand the granularity in a microservices architecture.
If there are many function invocations, it will make the application complex to run and debug. While the scope of optimization is different for each application, there are some best practices to optimize your code for functions.
Following are some of the best practices-
#1. Container reuse: Any externalized configuration or dependencies that your code retrieves should be stored and referenced locally after initial execution. The cloud architect should limit the re-initialization of variables on every invocation and use static initialization, global/static variables, and singletons instead. Also, keep alive and reuse connections (HTTP, database, etc.) that were established during a previous invocation.
#2. Optimize the coding practices for deployment: The cloud functions will support many language-specific SDKs. To enable the latest set of features and security updates, cloud providers (e.g., AWS Lambda or Azure functions) will periodically update these libraries. These updates may introduce subtle changes to the behavior of your function.
To have full control of the dependencies your function uses, it is recommended to package all your dependencies with your deployment code. It is also essential to minimize the package size to its runtime necessities. This will reduce the amount of time that it takes for your deployment package to be downloaded and unpacked ahead of invocation.
For example- Google functions authored in Java or .NET Core; avoid uploading the entire GCP SDK library as part of your deployment package. Instead, selectively depend on the modules which pick up components of the SDK you need (e.g., Datastore, Google cloud storage SDK modules, and Google function libraries). Prefer more straightforward frameworks that load quickly on container startups such as Dagger and Guice.
#3. Separate the point of entry for function and core logic: For example, keep the AWS Lambda handle separate from core logic. This makes unit testing of the function easier.
#4. Avoid long-running functions: Functions can become large and long-running due to language and external dependencies. This can cause unexpected timeout issues. Refactor large functions into smaller function sets that work together and return faster responses.
For example, an HTTP trigger function might require an acknowledgment response within a specific time limit. The HTTP trigger payload is queued to be processed by a queue trigger function. This way, you can defer the actual task and return an immediate response.
#5. Initializing database connections: After a function is executed, the serverless provider (AWS Lambda) maintains the runtime container for some time. This is done in anticipation of another function invocation. So for establishing database connection leveraging global scope is very important. Instead of re-establishing the connection, the original connection should be used in subsequent invocations.
Declare database connections and other objects/variables outside the Lambda function handler code to provide additional optimization when the function is invoked again. You can add logic to your code to check if a connection already exists before creating one.
#1. It was observed that the initial time for loading the packages could hamper the cold start time for AWS Lambda. Reducing the number of packages could help to optimize the cold start time for AWS Lambda. Several efficient plugins like serverless plugin optimize, Browserify help to reduce the number of packages.
#2. The performance of AWS Lambda cold starts varies depending upon the selection of programming language. Hence, it was experimented and observed that comparatively, Python, Go, and Node take less time than Java or .Net. However, depending on the memory location, the time may vary, but as compared to Java and .Net, these languages take much less time in initializing.
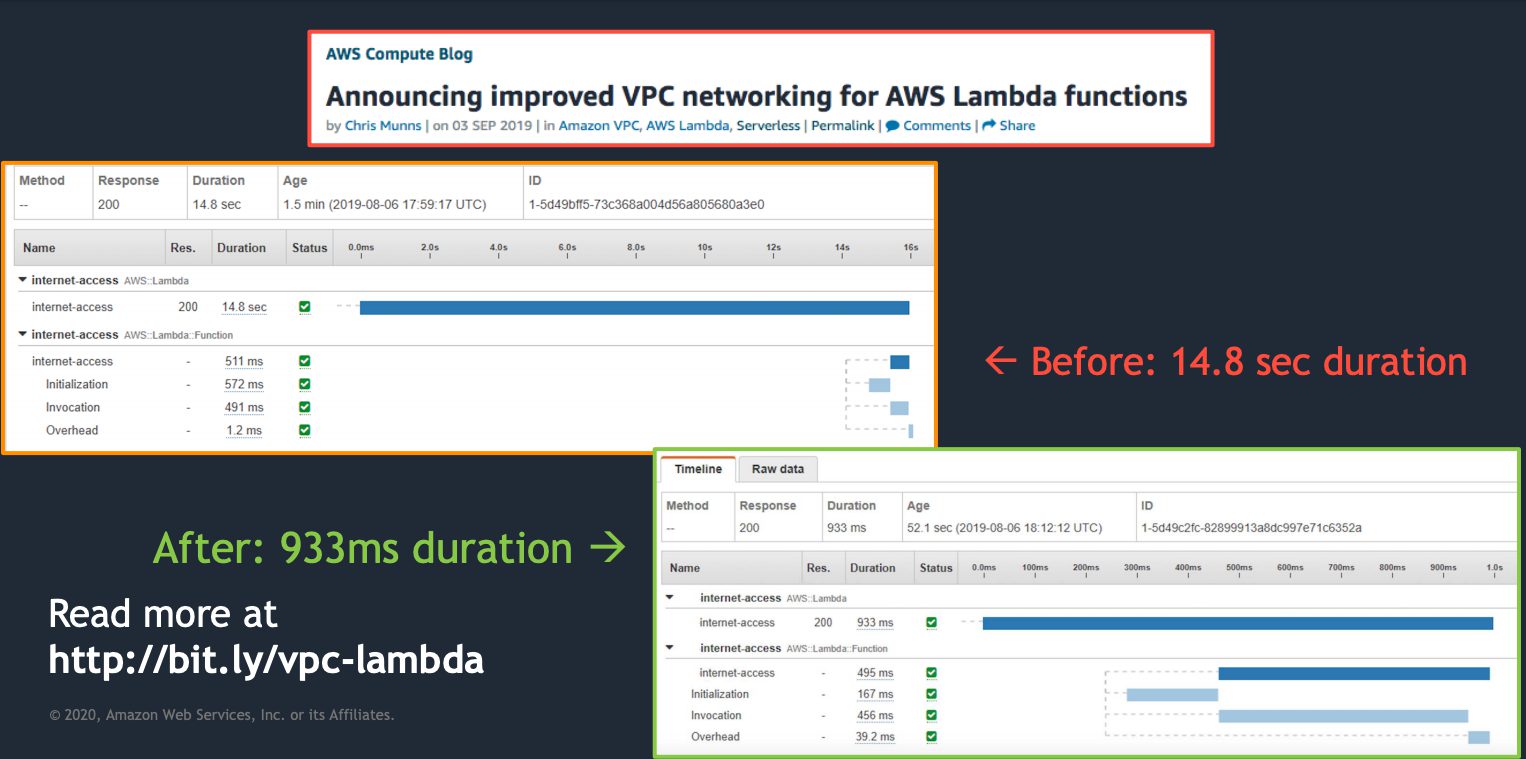
#3. Lambda to be kept out, VPC environments are observed to be more performant when compared to inside VPC. However, the improvements published in September 2019 unquestionably approves of promising performance of AWS Lambda inside VPC.
AWS Lambda Performance: Predictable Start-up times
Provisioned concurrency further helps in predicting function start times. A predictable schedule of start-up times supports apps with heavy loads where frequent changes in the number of concurrent requests are regular. Predictable start-up times are useful when you want to increase and decrease the concurrency based on the demands.
AWS auto-scaling configures such schedules for concurrency, adds or removes the concurrencies as required in real-time. It does not require any changes in code or Lambda payers and runtime configurations.
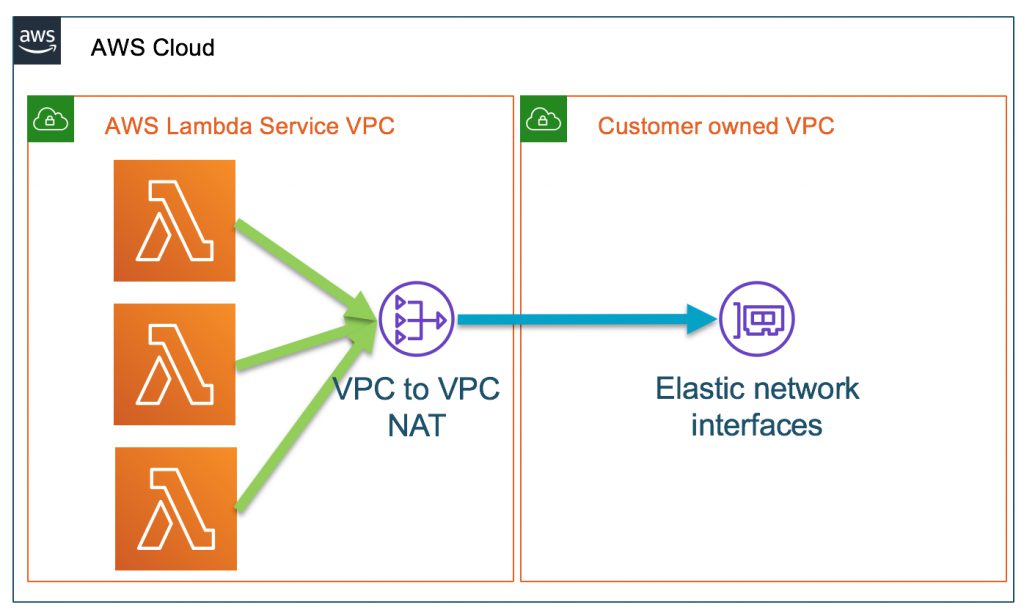
VPC Improvement
Amazon’s virtual private cloud has improvised its patterns to connect functions. They have started to leverage the Hyperplane for providing NAT capabilities from Lambda to customer VPCs. (Note: NAT is a network address translation to give internet access to the function.)
The Hyperplane ENI network controls multiple executions and ensures secure access inside the VPCs, while in the previous versions, it provided direct access to the Lambda execution environments.
Want to improve a performance of your Serverless application?
Let our extended team be part of your journey and help you step into the cloud.
Take Away!
Armed with this knowledge, now you can make a better decision on how to configure your AWS Lambda functions.
The other lesson, I’d like to impart to you is that function benchmarks are supposed to be gathered over the course of time and not in hours and minutes. Hence, AWS Lambda performance monitoring is a continuous process.
We’ll be refurbishing this blog from time to time and try to be updated in our custom software development practices. So, keep in touch to stay updated about AWS Lambda best practices.
Jignesh is Director of Sales at Simform leading through a consultative approach and aligning the right team for tech initiatives, and helping organizations achieve advanced digital engineering goals.
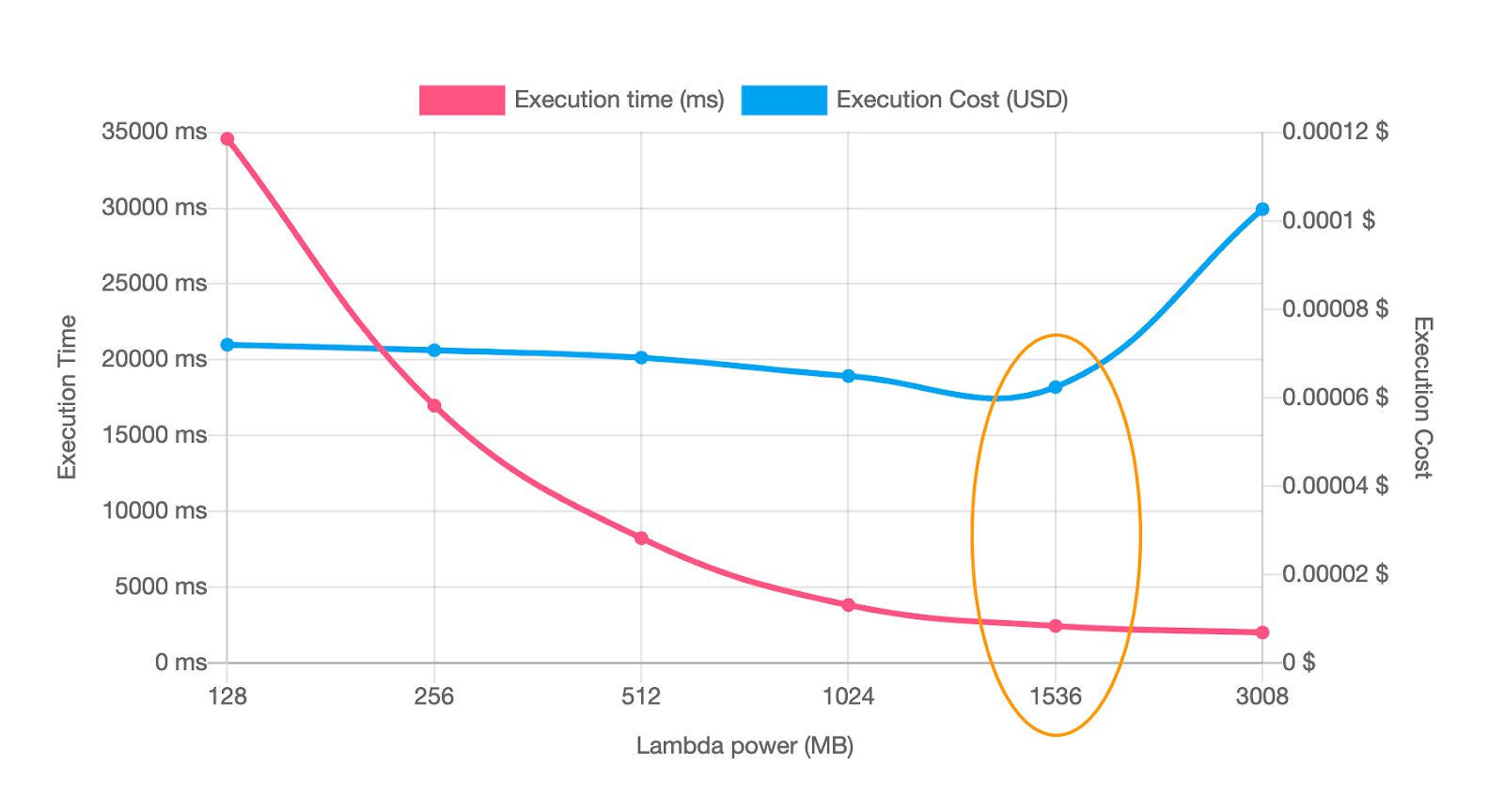 Execution time goes from 35s with 128MB to less than 3s with 1.5GB, while being 14% cheaper to run.
Execution time goes from 35s with 128MB to less than 3s with 1.5GB, while being 14% cheaper to run.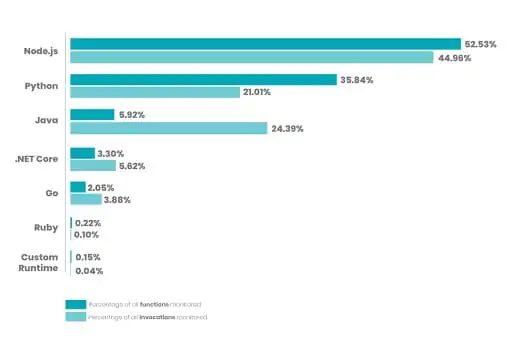

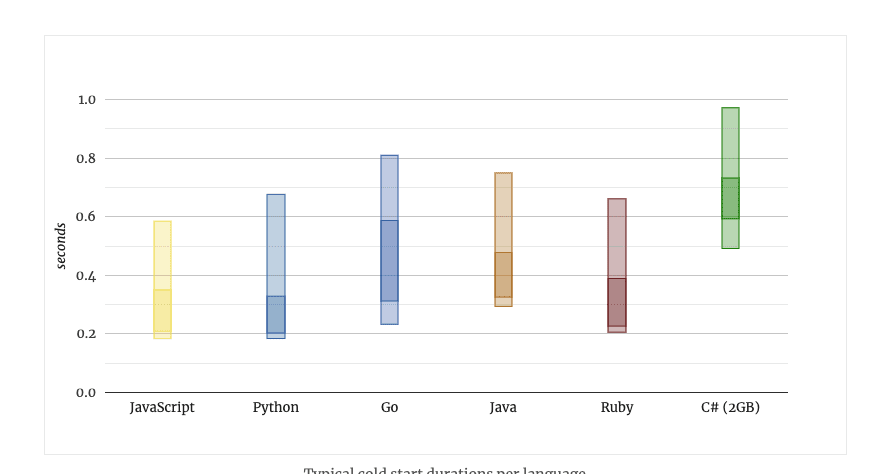
 The Hyperplane ENI network controls multiple executions and ensures secure access inside the VPCs, while in the previous versions, it provided direct access to the Lambda execution environments.
The Hyperplane ENI network controls multiple executions and ensures secure access inside the VPCs, while in the previous versions, it provided direct access to the Lambda execution environments.