Whether you are building a brand new mobile application or want to add more features to the existing app, choosing the right database can be overwhelming given all the choices available today. There’s a huge possibility that your current database is not sufficient to handle millions of users and frequent updates.
Crisp a messaging platform built their original platform with Firebase as the database. But, they quickly ran into the following challenges:
- Difficulties in handling complex queries
- Storing data offline
- Managing object relations at web scale
For Crisp, it was extremely important that their users are able to effectively communicate with their customers. But customers were often missing important communications sent via the app. Thus Firebase proved to be a bad fit here!
They, later on, moved to a SQL database for data storage and MongoDB to store the messages for better performance and scalability.
Crisp isn’t the only story where a database dramatically compromised the quality and performance of an application.
The face of disruption, Uber had to migrate their database from PostgreSQL to MySQL. Uber made this choice as they faced inefficient database replication features and constant migration from one PostgreSQL version to another.
Popular Mobile App Databases
Here are some popular databases to build Android apps and iPhone apps. You can select the best database for your mobile app based on your requirements.
MySQL: An open-source, multi-threaded, and easy-to-use SQL database.
PostgreSQL: A powerful, open-source object-based, relational database that is highly customizable.
Amazon DynamoDB: It’s a fully-managed, serverless key-value NoSQL database service with consistent single-digit millisecond performance at any scale.
Redis: An open-source, low maintenance, key/value store that is used for data caching in mobile applications.
MongoDB Realm– It’s a fully managed backend service to build, deploy and scale mobile apps effortlessly. It is known for its ability to build offline-first apps and sync data between Realm mobile database and the cloud.
Memcached: A distributed cache system that is multi-threaded, and used primarily for caching objects to speed up applications by alleviating database load.
Elasticsearch: Known for its ability to fetch faster results from a large number of inventory items. It is widely used as a distributed text search engine for working with large datasets in real-time.
MariaDB: A popular open-source relational database that was created by the original developers of MySQL.
Cassandra: A free and open source, NoSQL database which is designed to handle a large amount of unstructured data at any scale.
SQLite: Embedded database, common usage is to provide local data storage capabilities on mobile phones.
Neo4j: Powered by a native graph database, Neo4j maintains data relationships and delivers unmatched performance by providing lightning-fast queries and deeper context for analytics.
InfluxDB: An open source, fast and time series database which is written in Go.
RethinkDB: An open-source, and document-oriented database which stores data in JSON format and sync in real time with the application.
Riak DB: A distributed NoSQL database, which offers high availability, fault tolerance and data resiliency as its core feature.
CouchDB: A document-oriented NoSQL database which uses JSON to store data and javascript as its main query language.
Couchbase: A full Stack NoSQL database that supports offline sync, full CRUD, and query capabilities and runs locally on the device.
ArangoDB: An open source NoSQL database which is known for its multi-model, graph and geo algorithm features.
Selecting the right database for Mobile applications(with multiple layers of data) is a big challenge. I was shocked to see the challenges that developers face when they integrate the mobile app with databases.
General Criteria to Select Right Databases for Mobile Apps
What is the structure of your data?
Structure focuses on how you need to store and retrieve your data. Mobile applications deal with data in a variety of formats. Offline apps store all the data on the mobile device whereas Online apps depend on access to a server for their stored data to function. For example, E-commerce apps fall into the online apps category.
There are other types of apps called Synchronized apps. These apps store all their data on the mobile device and thus can be used offline, but the stored data may be updated on the server when the device is periodically online.
What’s the Size of your data?
The size of data refers to the quantity of the data you need to store and retrieve as critical application data. The amount of data may vary depending on a combination of the data structure selected, the ability of the database to differentiate data across multiple file systems and servers. So you need to choose our database keeping in mind the overall volume of data generated by the application at any specific time and the size of data to be retrieved from the database.
Speed and Scale
Speed and Scale address the time it takes to service incoming reads and writes to your application. Some databases are designed to optimize read-heavy apps, while others are designed to support write-heavy solutions. Selecting a database that can handle your app’s I/O needs goes a long way to a scalable architecture.
For example, MongoDB is faster than MySQL when it comes to handling a large volume of unstructured data. On the other hand, MySQL would be faster for structured data.
Data Modeling
Before you choose any database, it’s advisable to perform Data Modelling. It is a representation of the data structures to be stored in the database and very powerful expression of the business requirements.
Data Modelling is very helpful if your app contains features like search queries, reporting, location-based features, etc. Such apps require multiple databases to manage different types of data. For example, Uber uses MySQL, MongoDB and lot of other databases. They use MongoDB for their CDN and MySQL for business logic. Using MongoDB in their case made it very simple to store high volume incoming data.
Data Security
When you’re using synchronized and decentralized storage it is important to access, transmit, and store data securely. To cover this completely, you need to address authentication, data at rest, data in motion and read/write access.
Authentication should be flexible and allow for the use of standard, public, and custom authentication providers. Support for the anonymous access is also important for many apps. For data at rest on the server and client, you’ll want support for both file system encryption and data-level encryption. For data in motion, communication should be over a secure channel like SSL or TLS. For data read/write access, the database should offer granular control over what data can be accessed and modified by users.
Support for the multiple mobile app platforms
Are you planning on supporting iOS, Android, or both? What about IoT devices and wearables? If you plan to support more platforms later, you have to take that into consideration now. A lot of mobile applications today evolve to add a web companion app or a native desktop app, so that’s something you have to think about.
If you are building mobile apps for both iOS and Android platforms then you can use React Native framework. It is easy to simultaneously develop for both Android and iOS as developers can share code on both the platforms. In addition, it supports all types of databases.
Selection Criteria Based on Use Cases
Data Synchronization between local database and backend server
Many mobile applications have features which work offline and requires an internet connection to save local data to the app’s server. For example, In Dropbox, you can edit and create new files, even when you are offline. When you are connected to the internet any changes you made will sync to the cloud.
Data synchronization is a critical part while developing a mobile application. You have to carefully analyze the use cases for your application and know what applies best for each. Are your mobile users going to read data only? Do they modify existing data?
Choose the local database which provides sync service to automatically store the local database to the cloud server and vice-versa.
Couchbase and realm the popular databases which provide Data synchronization between local database and backend server.
Mobile Applications With Multiple Layers of Data
Many applications contain a multi-layer data model in which one set of “fields and tables” is dependent on another set of “fields and tables”. In such apps, it becomes difficult to manage the data.
Generally, most apps change-over-time and require modifications and changes in the database structure. With a structured database(e.g., MySQL, PostgreSQL), you won’t be able to make the changes frequently.
Using an unstructured database like MongoDB Realm would bring in flexibility to change without going through the painful process that you would find yourself in with structured databases. MongoDB allows you to work with unstructured data in multiple layers, adding new app features with flexibility – without the need to change the overall structure of your database.
Users who have a low network issue
When any SQL databases lose network connection with the client side storage, it typically generates an error message instead of transferring the data as needed. If this problem occurs frequently, you may need to re-configure your database. Apart from that, there are other challenges to deal with MySQL and network interruptions such as:
- Persisting local data including unsynchronized transactions and app state
- Getting mobile transactions and operations back to the main server-side database
Above listed issues occur on behalf of network interrupts, keeping a database that offers better reliability and resists connection loss is a better option in this case.
For highly scalable mobile applications
When you think of scaling your application, you think of adding more resources in the form of servers and making the database engine more efficient. The database should be able to utilize the resources and handle the parallel processing, that means the Database must be multi-threaded.
Multithreading allows a database to schedule parallel tasks on the available resources and minimize the workload on the server-side. Apart from multithreading, Distributed Design of a database is significantly important for scalability.
In a distributed designed database, you can split up the services on different threads to minimize the workload on the main database. This drastically improves the parallel processing of databases.
Pushing new app updates and database changes
Pushing new updates to the mobile app requires some changes to the local database. So the developers need to keep up with old database versions. Let’s understand how challenging and important it is for developers.
For example, some of your app users are using V1.0 version and you recently pushed V3.0. Now V1.0 users update to V3.0. Note that these users have skipped V2.0 altogether.
The local database you choose should be able to handle such scenarios. The database should be able to add new fields and tables as well as can manage old APIs and database structure for the users who use the latest app version.
You can choose SQLite with any server-side database, and it would work fine. SQLite has built-in OpenHelper tool to check database versions and to call functions such as onUpgrade or onCreate.
Resolve data conflicts between devices
For a mobile application which modifies the same data on multiple devices simultaneously can create conflicts. The database needs to support a mechanism for resolving those conflicts. The flexibility of the conflict resolution mechanism is important and should allow resolution automatically, on the device, in the cloud, by an external system, and by a human.
For more specific use-cases, refer to this table to determine which database would be more suitable for your specific requirement.
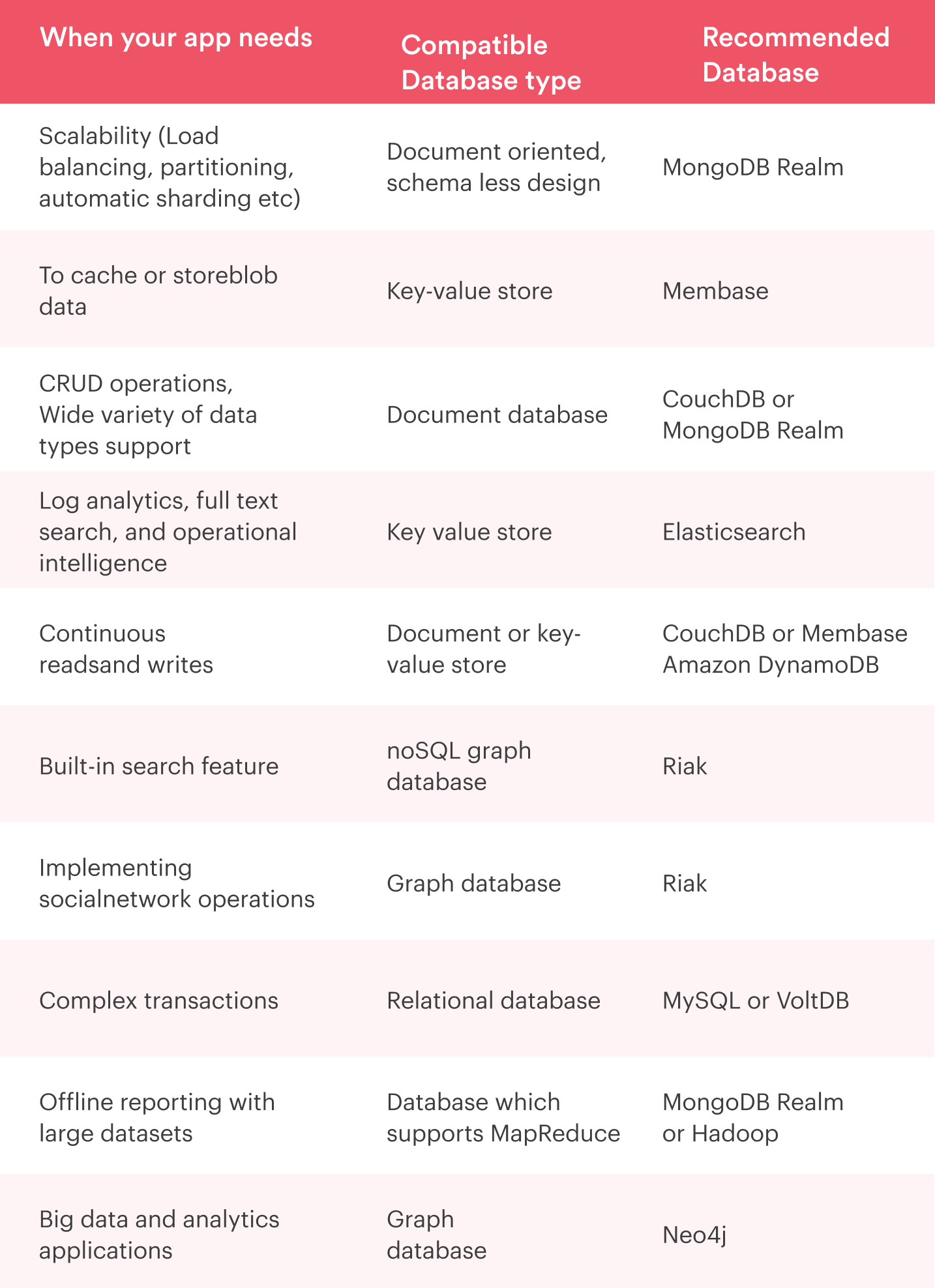
Best Practices for Working with Mobile App Databases
Predictive Caching
Predictive caching can be applied to improve the performance of your mobile app by looking at how, when, and where your users are using your application. A segment of users can be identified and can be served with specific information they always lookup based on their behavioral traits.
The best part is that the data can be made available and cached locally before the users even log-in to your app. MongoDB Realm provides predictive caching that allows developers to serve users with predicted-cached data before they even ask for it.
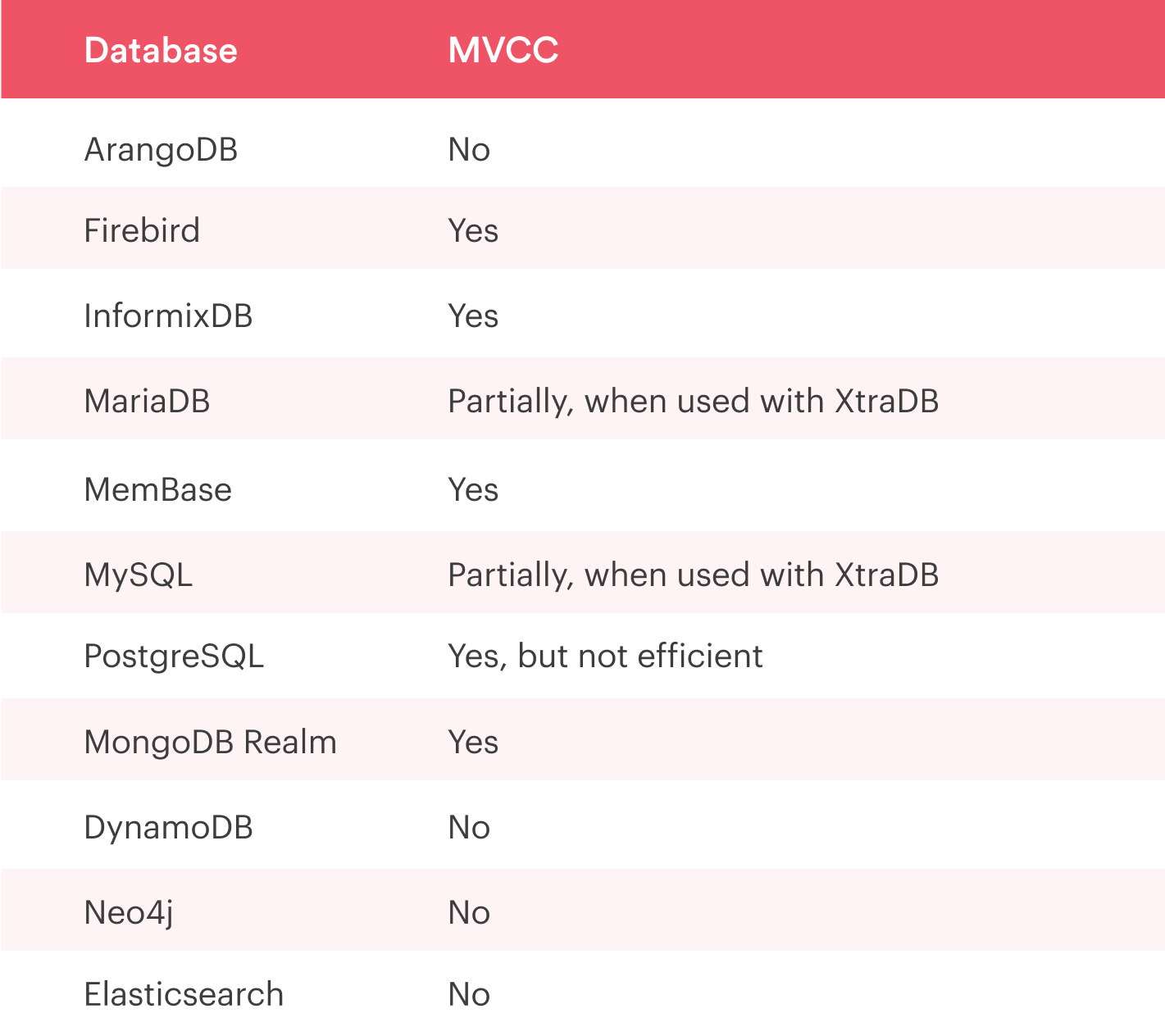
Consider Databases which use Multiversion Concurrency Control (MVCC) Method
Support for Multi-Version Concurrency Control (MVCC) allows simultaneous access without blocking the threads or processes involved.
MVCC allows a reader to view a snapshot of the data before the writer’s changes, allowing the read and write operations to continue in parallel.
For instance, look at this table to see which databases have MVCC implementation:
Low Latency Challenges
Low Latency is crucial for real-time applications and online gaming applications. High latency leaves the app users with a bad impression. Anything that goes below 500ms is considered to be a high latency.
Optimizing latency is a continuous cycle, and each database has its own limits to what extent it can be replicated or optimized.
There are multiple methods to reduce latency, and replication of the database is most popular.
Most companies replicate their production database to separate read/write, request queries and static content operations.
Here are some databases with lower latency than the average:
- Amazon DynamoDB
- MongoDB Realm
- PostgreSQL for transactional operations in real time
- RethinkDB built for real-time application
- PipelineDB, SQL database for streaming applications
Caching databases to reduce the load
We often add a caching layer to reduce the load on servers. We often cache data on this caching layer to prevent a recurring request for the same data. This reduces the number of requests going to the server and renders our server efficient for performance.
Mobile applications like Amazon get lots of recurring requests. You can reduce the load from the server by adding the caching layer. It can handle millions of requests with the lowest latency. You can use Redis and Memcached for such requirements.
Conclusion
Because mobile apps are subject change either it’s feature improvement or new feature update, it will affect the database. These criteria will help you to determine the right databases for your mobile app. What’s important here is to find a database that’s highly flexible.
Having experience with developing a variety of enterprise mobile applications for our clients, we consider future requirements and scalability to choose the right mobile app database. Let us know if you are facing scalability issues or want to build data-heavy applications from scratch.

Angel Mendez
It is good to have some basis to better choose the right database for any project. i think i made a kind of mistake developing my API for a e-commerce app, i did select MySQL for the logistic and MongoDB for all other data like invoices and products, after i had almos all the hard work done, i began to think that i could do all of the logistic with MongoDB also and that will take me to avoid using two databases when i really just needed one. but, as it is not such a big database i will eventually move my data from MySQL to MongoDB.
Manoj Jat
Obviously, this article clearly defined each database limitations, now I can choose right database for my application.
Prakul Tomar
Very nice article about Mobile Databases
Aparna Joshi
Hello sir, I am suppose to build an e-commerce app ..That have huge data also the app should have predictability,scalability which db should be used?
Nawaya Josiah
This article has really explained much to me thank you
Dliebel
thanks for the article, it was a great help
Preet R Gandhi
Explanation was very good.
Amit Singh
Very well explained.. Thank you..
Soran
Thanks for your explanation, but I am still doubtful about choosing the right database for my project!
Hameed Khan
It's an awesome explanation. Thanks
Dhiraj
Excellent explanation
Kelvin Kalulu
Very Good explanation
Baljinder
Yes it opened the senses of mind to choose the backend...
Nandhini
Good Explanation..