The ecosystem of serverless technologies has witnessed an upvote as Serverless Architecture is being adopted by many organizations for building modern event-driven architectures.
In this blog, we’re going to dive deep into Serverless Database — how it works, key elements, features, benefits, limitations, uses cases, and vendor options — illustrated with Amazon Aurora Serverless (explained in a minute). It will help you to understand how you can use different databases in custom serverless applications.
Before we brief you about what is Amazon Serverless Aurora and why demonstrating my blog with it, we’d like to draw your attention to a common business problem:
We’re sure most of us are aware of the importance of testing environments for software and applications, especially testing databases. They are used infrequently for fewer amounts of time with unpredictable loads.
However, many of us end up investing a major chunk in testing databases. We’ve, personally, taken over many projects that burnt thousands a month in database costs because they preferred replicating the environment for testing branches.
Anyway, Amazon Aurora Serverless — Announced in the AWS re: Invent in 2017 and launched in August 2018 — turned into the biggest game-changer for all.
What is Serverless Database?
Serverless Database is a prerequisite for the serverless computing paradigm. These are specially designed for unpredictable workloads and can scale up/down rapidly without you having to worry about managing the underlying infrastructure. What’s more? This allows you to pay only for the database resources you use on a second-by-second basis.
We are aware of cloud databases, say, Amazon Aurora which is compatible with MySQL or PostgreSQL, fully-managed and automatically scales up to 64TB of database storage.
While creating this database, you choose the desired instance size and this works really well in an environment where there are predictable workload, request rate and processing requirements.
However, in the cases where the workload isn’t predictable and there is a burst of a request for a few minutes a week or a day, arranging right amount of capacity can be a lot of work. At the same time, paying for it on a continuous basis might not be the best solution.
And here’s where serverless database comes in the picture.
How does Serverless Database Work?
Let’s take the example of Amazon Aurora Serverless to better understand the concept.
What is Amazon Aurora Serverless?
“Amazon Aurora Serverless is an on-demand, auto-scaling configuration for Amazon Aurora (MySQL-compatible edition), where the database will automatically start up, shut down, and scale capacity up or down based on your application’s needs. It enables you to run your database in the cloud without managing any database instances. It’s a simple, cost-effective option for infrequent, intermittent, or unpredictable workloads.”
In the case of Amazon Aurora Serverless database, it starts up, scales capacity as per your application’s demand, and shuts down when not in use.
Thus, you run your database in the cloud without managing multiple instances or clusters
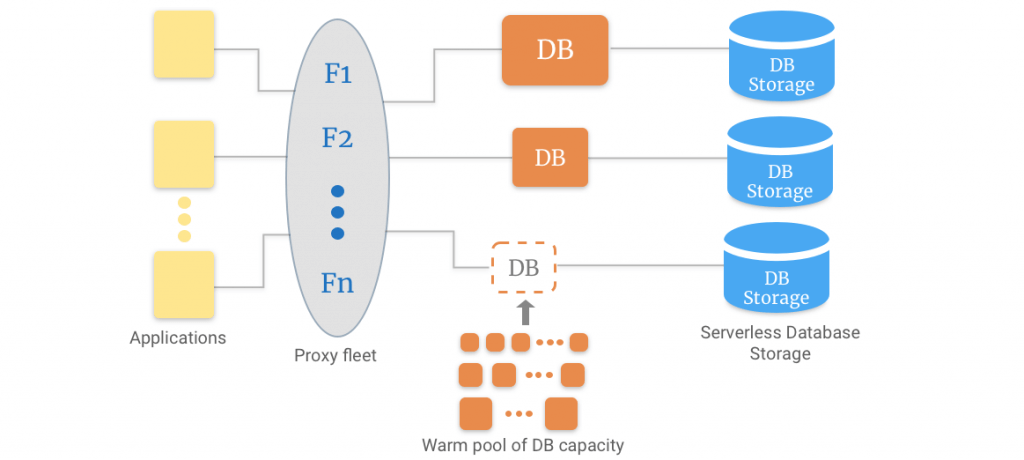
The Serverless Database model is built on the separation of storage and processing.
You create an endpoint, set up the minimum and maximum capacity if you like, and issue queries to the endpoint. This endpoint works as a proxy to a frequently scaled fleet of database resources. This empowers your connections to remain intact while scaling operations occur behind the stage.
The separation of storage and processing brings another benefit as well. You can easily scale down to zero processing and only pay for the storage capacity you use. Whenever your application demands, scaling happens in almost 5 seconds while building upon a pool of “warm” resources which are eager to serve your requests.

Key Elements of Serverless Database
- Automated Elastic Scale
Serverless databases automatically scale down to zero when there is no demand and scale up when there is a sudden spike in demand. Essentially, these databases meet unexpected workload demands at any time without any interaction from developers or Ops personnel. Such elasticity allows your applications or services to consume only the right amount of resources, ensuring you only pay for what you use.
Moreover, serverless databases also scale geographically to move and store data dynamically, thus, minimizing latency and providing a consistent experience to users.
- Simplicity
Serverless databases are simple, intuitive, and easy to use, even for beginners. For instance, working with them is as simple as working with APIs. Their features, such as self-service starts, fully managed operations, REST APIs, and the ability to create clusters with only a click of a button or a single command, lend them this simplicity and familiarity.
- Speed of Deployment
Managing serverless databases is faster compared to traditional systems. Moreover, they are easy to use, and you can create a new cluster in minutes! Serverless platforms abstract away deployment procedures such as installing, configuring, capacity planning, and scaling your database that you would do manually. It also eliminates tasks of manual server management, scaling API endpoints and load balancers, etc. Thus, they can drastically reduce the time to market.
- Consumption-based Billing
For databases, the two vectors of resource consumption are storage and transactional volume. But when working with a serverless database, you only consume what you need due to its automatic, elastic app/service scale, as discussed above. Thus, you are only billed for storage costs and compute usage, making them a cost-effective option.
Different types of serverless databases
In this section, we’ll study various serverless databases that simplify data management without the hassle of server maintenance. These serverless databases empower you to focus on developing rather than managing infrastructure, ensuring a seamless and efficient data-driven experience. Let’s explore the different types, each offering a unique benefit.
#1. NoSQL Databases:
NoSQL databases are like flexible artisans in data storage, breaking free from the rigid structures of traditional relational databases. They enable data storage and retrieval without the constraints of a fixed schema.
You benefit from the freedom to handle diverse data types, making NoSQL databases an excellent choice for applications where data models evolve over time. Whether it’s JSON, XML, or other document formats, NoSQL databases handle them with finesse.
#2. SQL Databases:
SQL databases follow a predefined schema, ensuring data integrity and relational order. Picture SQL databases as expert librarians meticulously organizing books on shelves. If your application demands structured data and a clear relationship between different pieces of information, an SQL database might be your trusted companion.
#3. In-Memory Databases:
Unlike traditional ones that use disks, in-memory databases reside entirely in a computer’s main memory. With this type, data retrieval happens at lightning speed. Imagine fetching information from your brain’s memory rather than a distant library. In-memory databases are your go-to for applications requiring rapid access to frequently accessed data.
#4. Time-Series Databases:
Time-series databases shine in scenarios where time is of the essence. They specialize in handling data points indexed by time, making them perfect for applications tracking changes over time.
Think of time-series databases as the personal diaries of your data, chronicling every event with a timestamp. This database type is your trusted companion for monitoring, IoT applications, and financial data analysis tasks.
#5. Graph Databases:
Graphic Databases excel at representing and navigating relationships between data points. Consider a graph database as the matchmaker, connecting entities based on their relationships. This type shines in social networks, fraud detection, and recommendation engines.
#6. Key-Value Stores:
Key-value stores offer a straightforward approach to data storage. Each piece of information is linked to a unique key, making retrieval a breeze. Think of key-value stores as a treasure chests where each key unlocks a specific piece of valuable information. This simplicity makes them ideal for caching, session storage, and scenarios where speed is paramount.
Features of Serverless Database
Serverless Databases come with some of the exciting features like:
#1. Multi-tenant Architecture:
One of the bonuses of serverless databases is that they can function as a single pool of resources that can be used by multiple projects within your organizations.
This is a huge plus for the development team as they are not required to build application-specific siloed data sources.
This is possible due to its multi-tenant architecture. This enables developers to set up, configure and deploy multiple applications within the same database cluster.
#2. Dynamic Quality of Service:
Multi-tenancy opens up the possibility of assigning priority to each tenant. Under this, you can assign priority to specific tenants as a result of which system resources will be consumed in accordance.
This empowers operation teams to make maximum use of resources across their organization’s projects. However, it must be kept back in mind that this will demand a high transparency rate across the whole database cluster.
With this practice, your resources can be run at 60-80% utilization. If any spike is observed towards 90% or above, it will result in throttling of lower-priority workloads.
For example, high priority workload might be an issue in making a purchase, while low priority workload might be batch reporting processes.
#3. Geo Distribution:
Given the fact that most of the businesses are working on a global scale, it is a prerequisite for the organizations to have their data needs available around the world.
With the close proximity of data centres, the real-time experience is enhanced to a greater extent. Moreover, the risk of an outage is highly unlikely as there is no point of failure.
Serverless database lets you replicate multiple datasets across the world without any additional tooling or custom developments. Various protocols embedded in the serverless database networking layer makes sure that it responds correctly to failures and performance degradation.
#4. ACID Consistency:
There is no way possible that we can compromise data accuracy over its real-time availability. In other words, we can’t afford the serverless database to sacrifice its transactional consistency for speed and scale.
Serverless databases support ACID transactions with the new approach of classifying sequencing and scheduling functionality within a single layer above the stored data system. Thus, queries incoming from the end user application is managed before the DBMS interacts with the data storage system.
This gives enough time for the nodes in a cluster to decide which node will handle this transaction before the write begins while making sure that two simultaneous processes don’t modify the dataset. In this manner, it is possible to scale while making room for ACID-compliant transactions as well.
#5. Single Transactional Query Language:
Serverless databases facilitate a single pool of resources to multiple applications. However, the imposition of a particular data structure or a single model for all its applications consuming that data could cause a serious problem for the development team. Also, this way, it’d be impossible to store data in the way it was originally meant to be.
Moreover, some applications might need strong schema while some might need a schema-less model. To all these problems, an ideal serverless database supports structured as well as unstructured data.
Schema optionality empowers the development teams with the support of use cases of structured and unstructured data. It also facilitates all the advantages of having a schema with none of the inherent disadvantages.
Benefits of Serverless Database
#1. Real-time Access:
You have access to your data at a granular level. The data gets indexed by default and it makes those indexes available immediately.
This means you’ll be able to constantly query, read, write, update and add new items to your serverless database. What’s more? It will have easy and instant access via functions.
#2. Infinite Scalability:
Serverless databases can be scaled up or down anytime you want as they start-up or shut down as per the application’s need.
If your functions are querying, reading or writing data to the same database cluster, it will scale the compute resources (ACU in the case of Aurora Serverless) to handle the load.
Due to this automation, all your functions will be able to work in parallel and your data is guaranteed to be consistent.
#3. High Security:
Modern applications are exposed to the untrusted and malicious audience at a global level.
Serverless database takes care of it by making sure that all the applications interacting with the same dataset passes the same protocol of access control. As a result, it reduces the attack surface, a critical risk for today’s business-critical applications.
#4. Availability:
Serverless database empowers you with that which helps you in reducing the latency and performance issues. With this approach, data from event-driven functions is read where it is closest to the user.
#5. Schemaless:
With Schemaless you can handle any data output from your functions. This ‘handle anything’ approach makes it extremely easy to integrate serverless databases with your functions. An uncommon feature amongst other Serverless databases.
#6. No need for manual server management:
With serverless databases, you can overcome the complexities of server maintenance. No more wrestling with hardware configurations or worrying about software updates. Instead, focus on what truly matters – your data and applications. The platform handles the heavy lifting, allowing you to invest your time and energy where it counts the most.
#7. Built-in resilience:
Serverless databases have built-in resilience, meaning your data is automatically backed up and redundantly stored. In the face of unforeseen challenges, your database adapts seamlessly, ensuring uninterrupted access. Enjoy the peace of mind that comes with knowing your data is safeguarded without any extra effort on your part.
#8. Consumption-based pricing:
Budget constraints are a thing of the past with consumption-based pricing. Pay only for the resources you use, aligning costs directly with your application’s needs. It’s a cost-effective approach that eliminates the burden of paying for idle resources. As your application scales, so does your expenditure, ensuring a fair and transparent pricing model.
#9. Geographic scaling:
Serverless databases enable you to effortlessly expand your operations across regions, reaching users wherever they are. Whether you’re catering to a global audience or targeting specific markets, geographic scaling ensures optimal performance and reduced latency, delivering a seamless experience to your users worldwide.
#10. Transactional guarantees:
Serverless databases offer robust transactional guarantees, ensuring the integrity of your data. With the serverless database, your transactions are handled precisely and accurately. Whether it’s financial transactions, user interactions, or any other critical operation, rest assured that serverless databases deliver consistent and reliable results.
Limitations of Traditional Databases
Traditional databases are coming off with huge limitations as new technologies step in. Here are some limitations that impact businesses:
#1. Overspending on Resources
To manage huge data infrastructure, companies spend an immense amount of money. Traditional database infrastructure means they benefit very little from resource sharing, and they keep on wasting money with isolated teams and their dedicated resources.
#2. Locality of Data
To maintain data availability and low latency, the database is replicated across various data centres. However, due to networking infrastructure, it is impossible to ensure that the requested data is returned from the same geographic location.
#3. Higher Fulfillment Time
Even after years of investment, large organizations often come across what we call ‘database diversity’ problem. With many options in the market, it is quite hard for the development team to add functionality to all of them once in a while. And the result is a higher time of fulfilment period.
Serverless Database Vendors
Plenty of AWS serverless database options are available in the market, and most can be used while making your serverless application. However, the following databases are the top options you can rely on as they are purely meant to be used with functions, and they stand out due to their two distinct features- pricing and real-time responsiveness. We have categorized these top vendors based on two types of serverless databases – relational and NoSQL.
Relational Serverless Databases
#1. CockroachDB Serverless
CockroachDB Serverless is a cloud-native, distributed SQL serverless architecture database designed for automatic scaling and a familiar SQL interface. It is fully managed, elastic, and tolerant service with built-in resilience, allowing developers to build apps instantly. Moreover, you can create a cluster for free and pay only for the resources you use up.
#2. PlanetScale DB Serverless
PlanetScaleDB Serverless is a fully managed, cloud-native SQL database built on the Vitess project. It is a developer-first database that eliminates the need for query planning, cluster sizing, scaling, and other database-related tasks in advance. It is also designed for enterprise-grade scalability and compatibility with all major languages and frameworks.
#3. Amazon Aurora Serverless
Aurora Serverless is an on-demand auto-scaling configuration for Aurora where the database starts up and shuts down as per the application’s needs. There is no complexity in managing database instances and database capacity. It is built on the same fault-tolerant, distributed, and self-healing Aurora storage with 6-way replication to protect you against any data loss. Moreover, it supports the full breadth of Aurora features including Multi A-Z deployments, global database, and read replicas.
#4. Azure CosmosDB
Microsoft Azure CosmosDB is a multi-model database with global distribution and horizontal scalability as its core features. It offers turnkey global distribution across any number of Azure regions by transparently scaling and replicating your data as per the locality of your users. Moreover, CosmosDB guarantees single-digit millisecond latencies performance at the 99th percentile anywhere in the world.
NoSQL Serverless Databases
#1. Google Firestore
Google Firestore is a fully managed, serverless document database that eases and accelerates development of rich mobile, web, and IoT applications by providing direct connectivity to the database. Moreover, it effortlessly scales to meet unexpected demands with no maintenance window and zero downtime and has simple, flexible pay-as-you-go pricing. It also offers other features like identity-based security access controls, real-time data synchronization with offline data access, support for multiple server-side development libraries, etc.
#2. MongoDB Atlas
MongoDB Atlas is a fully-managed database service that provides a scalable, reliable, and secure solution for MongoDB. It allows developers to quickly deploy, manage, and scale their MongoDB clusters in the cloud and access their databases from anywhere in the world, freeing them from any infrastructure management. Moreover, it has automated backups, monitoring, disaster recovery, and a range of security features, including encryption and identity management.
#3. Amazon DynamoDB
Amazon DynamoDB is one of the fully managed NoSQL serverless databases by AWS designed to run high-performance applications at scale. It is highly scalable, fast, and flexible, with support for both document and key-value data structures. DynamoDB is designed for storing and retrieving any amount of data and can handle a wide range of use cases, from simple key-value storage to complex querying and analysis.
#4. FaunaDB
FaunaDB is the only serverless cloud database built on the ground to meet the needs of serverless apps. FaunaDB believes in not managing databases or underlying servers. No provisioning, utility pricing, and built-in security are some of the prominent features that make FaunaDB an ideal option for teams wanting to build serverless applications or new microservices or expand/upgrade existing applications instantly and at a low cost.
Use Cases of Serverless Database
When to Use?
If you’re at any of these stages, Serverless Database is your knight in the shining armour:
#1. New Applications:
An application whose usage might be for a few minutes over the course of a day or week.
For instance, you have a low-volume blog site and you want to pay only for the time any user is accessing your site, this works for you since you pay for the database resource you consume on a per-second basis.
#2. Infrequent Used Applications:
Where you’re unsure how your user base is going to scale.
For instance, you’ve built an app and you’ve no idea how popular it will become and also, you don’t want to take a chance, this works for you. Just create an end-point and let the serverless database auto-scale as per the requirements of your application.
#3. Variable Workloads:
An application where you’re likely to see around, say, 30 minutes of the peak for several hours a few times each day or several times per year.
For instance, applications like HR, budgeting, operational reporting, etc. have highly unpredictable peak load timings and hence, reserving instance is impossible. However, with the serverless database, you don’t have to provide to either peak timings or average capacity.
#4. Test Databases:
A test database, it is going to be used only during the working hours of your organisation, well why pay for it when it is not in use? Serverless here is the best fit as it shuts down automatically when not in use.
Where to Use?
#1. Telecommunications & IoT:
Let us assume the scenario of connected cars. You can use events to trigger functions related to car alerts. Let’s take an example of checking an engine light ON in a connected car.
A function is created which invokes as soon as there is any data-change to the sensor data collection. Moreover, if it meets the threshold limit, another function is triggered which sends a notification to the warranty department.
Another function is created which sends the maintenance mailers as soon as the threshold conditions from the sensor data collection are met. Since, all these events need to occur in a real-time, serverless database can be used here as a most feasible solution.
#2. Finance:
Let us take the case of financial applications. With these applications, you can use events to trigger functions related to the bank account of a particular user. This function can be set whenever the account balance is below a certain limit.
With an API call, you can access the data stored in the serverless database. The conditions to invoke these functions can be set to weekly or monthly and for what would be considered as a low balance. Since you can’t predict the occurrence of these events, the serverless database is best.
#3. Marketing & Retail:
Let us take the case of the retail business. Whenever a user adds a particular item in their cart, you can set up serverless functions which trigger further business pipeline components like, updating inventory totals or send customer information for certain products to the marketing department, who sends them a promotional mailer.
In this case, since the function is decoupled from the app and database itself, you don’t need to keep them spinning all the time.
#4. Ecommerce:
Let us take the case of e-commerce apps where 3rd party payments are inevitable. Serverless databases streamline the user experience by letting you call these payment APIs securely without setting up your own servers.
When a user reaches for the payment, you collect their payment information and pass it to your database, then you process their payment by making requests to a third-party payment processing API over HTTPS, write the order to the serverless database, and return a confirmation message to the user once it is finished. All securely, without managing servers.
How to Build an E-commerce App using Serverless Technology?
How can a serverless database optimize cost?
Optimizing costs with a serverless database is like having a superhero for your budget. After all, you pay only for what you use and that’s a boon in terms of cost-effectiveness.
Here’s how it slashes costs without sacrificing performance:
- Automatic scaling: With a serverless database, you benefit from automatic scaling. This means the database adjusts its resources based on demand, allowing you to pay only for what you use. No need to worry about overprovisioning or underutilization – costs scale with your actual workload.
- Pay-per-use pricing: Serverless databases typically follow a pay-per-use pricing model. You’re charged for the actual resources consumed during each transaction or query. This ensures cost efficiency, especially during periods of low activity when traditional databases might still incur fixed costs.
- Zero idle costs: Unlike traditional databases that require continuous server maintenance, a serverless database incurs zero costs when idle. You’re not paying for idle servers; costs are incurred only when active transactions or queries align expenses with actual usage.
- Managed infrastructure: Serverless databases eliminate the need for managing infrastructure. This reduces operational overhead and the associated costs. Focus on your application and let the platform handle database maintenance tasks, freeing you from the expenses tied to infrastructure management.
- Optimized resource allocation: Serverless databases automatically allocate resources based on workload, ensuring optimal performance. This dynamic resource allocation prevents over-provisioning, saving you from unnecessary costs while maintaining the database’s responsiveness to varying workloads.
- Built-in high availability: Serverless databases often come with built-in high availability features. This eliminates the need for additional investments in redundant infrastructure. Your data is automatically distributed across multiple nodes, ensuring reliability without added costs for high-availability configurations.
Conclusion
The future of Serverless Databases, especially Amazon Aurora Serverless, look promising. The features of this modern technology have enabled us to draw focus on essentials like real-time access, scalability, security, and availability.
Having said that, it is not feasible to ditch existing databases all at once. Infrastructure support and management is challenging and, you could end up losing focus from the real problem of managing databases.
What we would love to talk about is your experiments with any of the serverless database platforms and what are the things you look forward to? If you think we’re missing something, kindly comment or get in touch with me on Twitter @Jignesh_Simform.
