Even though Netflix is an entertainment company, it has left many top tech companies behind in terms of tech innovation. With its single video-streaming application, Netflix has significantly influenced the technology world with its world-class engineering efforts, culture, and product development over the years.
One such practice that Netflix is a fantastic example of is DevOps. Their DevOps culture has enabled them to innovate faster, leading to many business benefits. It also helped them achieve near-perfect uptime, push new features faster to the users, and increase their subscribers and streaming hours.
With nearly 214 million subscribers worldwide and streaming in over 190 countries, Netflix is globally the most used streaming service today. And much of this success is owed to its ability to adopt newer technologies and its DevOps culture that allows them to innovate quickly to meet consumer demands and enhance user experiences. But Netflix doesn’t think DevOps.
So how did they become the poster child of DevOps? In this case study, you’ll learn about how Netflix organically developed a DevOps culture with out-of-the-box ideas and how it benefited them.
Netflix’s move to the cloud
It all began with the worst outage in Netflix’s history when they faced a major database corruption in 2008 and couldn’t ship DVDs to their members for three days. At the time, Netflix had roughly 8.4 million customers and one-third of them were affected by the outage. It prompted Netflix to move to the cloud and give their infrastructure a complete makeover. Netflix chose AWS as its cloud partner and took nearly seven years to complete its cloud migration.
Netflix didn’t just forklift the systems and dump them into AWS. Instead, it chose to rewrite the entire application in the cloud to become truly cloud-native, which fundamentally changed the way the company operated. In the words of Yury Izrailevsky, Vice President, Cloud and Platform Engineering at Netflix:
“We realized that we had to move away from vertically scaled single points of failure, like relational databases in our datacenter, towards highly reliable, horizontally scalable, distributed systems in the cloud.”
As a significant part of their transformation, Netflix converted its monolithic, data center-based Java application into cloud-based Java microservices architecture. It brought about the following changes:
- Denormalized data model using NoSQL databases
- Enabled teams at Netflix to be loosely coupled
- Allowed teams to build and push changes at the speed that they were comfortable with
- Centralized release coordination
- Multi-week hardware provisioning cycles led to continuous delivery
- Engineering teams made independent decisions using self-service tools
As a result, it helped Netflix accelerate innovation and stumble upon the DevOps culture. Netflix also gained eight times as many subscribers as it had in 2008. And Netflix’s monthly streaming hours also grew a thousand times from Dec 2007 to Dec 2015.
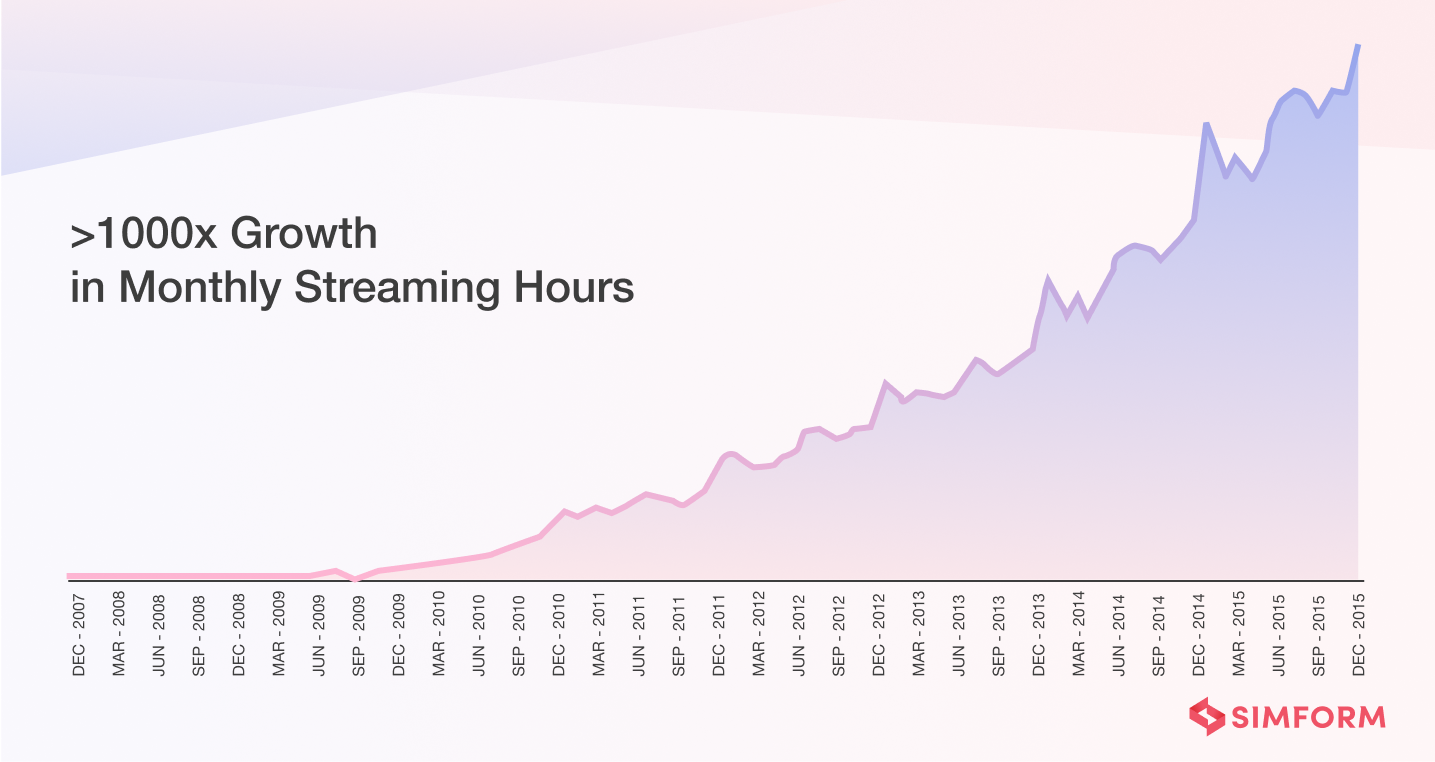
After completing their cloud migration to AWS by 2016, Netflix had:

And it handled all of the above with 0 Network Ops Centers and some 70 operations engineers, who were all software engineers focusing on writing tools that enabled other software developers to focus on things they were good at.
Netflix’s Chaos Monkey and the Simian Army
Migrating to the cloud made Netflix resilient to the kind of outages it faced in 2008. But they wanted to be prepared for any unseen errors that could cause them equivalent or worse damage in the future.
Engineers at Netflix perceived that the best way to avoid failure was to fail constantly. And so they set out to make their cloud infrastructure more safe, secure, and available the DevOps way – by automating failure and continuous testing.
Chaos Monkey
Netflix created Chaos Monkey, a tool to constantly test its ability to survive unexpected outages without impacting the consumers. Chaos Monkey is a script that runs continuously in all Netflix environments, randomly killing production instances and services in the architecture. It helped developers:
- Identify weaknesses in the system
- Build automatic recovery mechanisms to deal with the weaknesses
- Test their code in unexpected failure conditions
- Build fault-tolerant systems on day to day basis
The Simian Army
After their success with Chaos Monkey, Netflix engineers wanted to test their resilience to all sorts of inevitable failures, detect abnormal conditions. So, they built the Simian Army, a virtual army of tools discussed below.

- Latency Monkey
It creates false delays in the RESTful client-server communication layers, simulating service degradation and checking if the upstream services respond correctly. Moreover, creating very large delays can simulate an entire service downtime without physically bringing it down and testing the ability to survive. The tool was particularly useful to test new services by simulating the failure of dependencies without affecting the rest of the system.
- Conformity Monkey
It looks for instances that do not adhere to the best practices and shuts them down, giving the service owner a chance to re-launch them properly.
- Doctor Monkey
It detects unhealthy instances by tapping into health checks running on each instance and also monitors other external health signs (such as CPU load). The unhealthy instances are removed from service and terminated after service owners identify the root cause of the problem.
- Janitor Monkey
It ensures the cloud environment runs without clutter and waste. It also searches for unused resources and discards them.
- Security Monkey
An extension of Conformity Monkey, it identifies security violations or vulnerabilities (e.g., improperly configured AWS security groups) and eliminates the offending instances. It also ensures the SSL (Secure Sockets Layer) and DRM (Digital Rights Management) certificates were valid and not due for renewal.
- 10-18 Monkey
Short for Localization-Internationalization, it identifies configuration and runtime issues in instances serving users in multiple geographic locations with different languages and character sets.
- Chaos Gorilla
Like Chaos Monkey, the Gorilla simulates an outage of a whole Amazon availability zone to verify if the services automatically re-balance to the functional availability zones without manual intervention or any visible impact on users.
Today, Netflix still uses Chaos Engineering and has a dedicated team for chaos experiments called the Resilience Engineering team (earlier called the Chaos team).
In a way, Simian Army incorporated DevOps principles of automation, quality assurance, and business needs prioritization. As a result, it helped Netflix develop the ability to deal with unexpected failures and minimize their impact on users.
On 21st April 2011, AWS experienced a large outage in the US East region, but Netflix’s streaming ran without any interruption. And on 24th December 2012, AWS faced problems in Elastic Load Balancer(ELB) services, but Netflix didn’t experience an immediate blackout. Netflix’s website was up throughout the outage, supporting most of their services and streaming, although with higher latency on some devices.
Netflix’s container journey
Netflix had a cloud-native, microservices-driven VM architecture that was amazingly resilient, CI/CD enabled, and elastically scalable. It was more reliable, with no SPoFs (single points of failure) and small manageable software components. So why did they adopt container technology? The major factors that prompted Netflix’s investment in containers are:
- Container images used in local development are very similar to those run in production. This end-to-end packaging allows developers to build and test applications easily in production-like environments, reducing development overhead.
- Container images help build application-specific images easily.
- Containers are lightweight, allowing building and deploying them faster than VM infrastructure.
- Containers only have what a single application needs, are smaller and densely packed, which reduces overall infrastructure cost and footprint.
- Containers improve developer productivity, allowing them to develop, deploy, and innovate faster.
Moreover, Netflix teams had already started using containers and seen tangible benefits. But they faced some challenges such as migrating to containers without refactoring, ensuring seamless connectivity between VMs and containers, and more. As a result, Netflix designed a container management platform called Titus to meet its unique requirements.
Titus provided a scalable and reliable container execution solution to Netflix and seamlessly integrated with AWS. In addition, it enabled easy deployment of containerized batches and service applications.
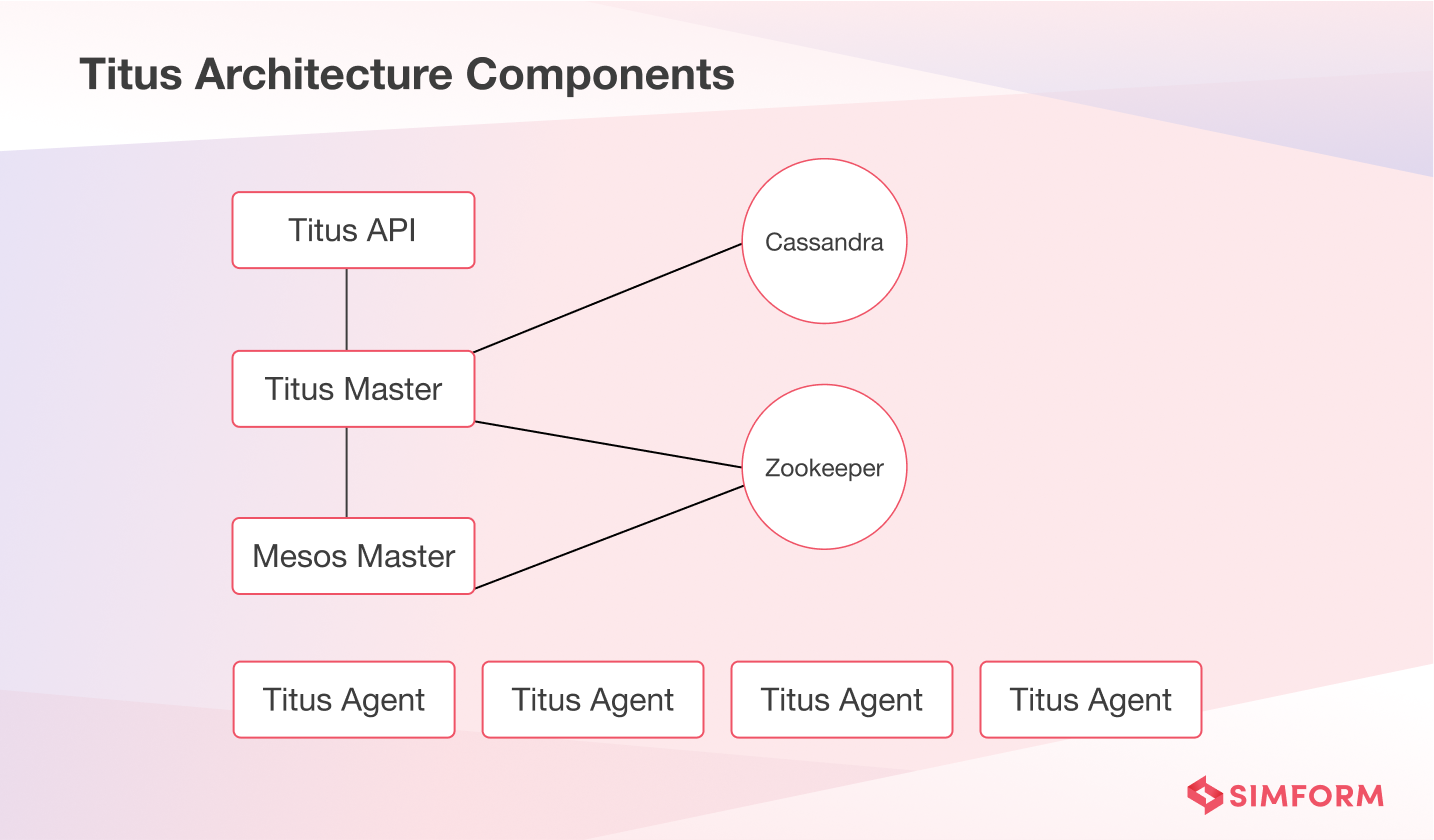
Titus served as a standard deployment unit and a generic batch job scheduling system. It helped Netflix expand support to growing batch use cases.
- Batch users could also put together sophisticated infrastructure quickly and pack larger instances across many workloads efficiently. Batch users could immediately schedule locally developed code for scaled execution on Titus.
- Beyond batch, service users benefited from Titus with simpler resource management and local test environments consistent with production deployment.
- Developers could also push new versions of applications faster than before.
Overall, Titus deployments were done in one or two minutes which took tens of minutes earlier. As a result, both batch and service users could experiment locally, test quickly and deploy with greater confidence than before.
“The theme that underlies all these improvements is developer innovation velocity.”
-Netflix tech blog
This velocity enabled Netflix to deliver fast features to the customers, making containers extremely important for their business.
Netflix’s “Operate what you build” culture
Netflix invests and experiments significantly in improving development and operations for the engineering teams. But before Netflix adopted the “Operate what you build” model, it had siloed teams. The Ops teams focused on deploy, operate and support parts of the software life cycle. And Developers handed off the code to the ops team for deployment and operation. So each stage in the SDLC was owned by a different person and looked like this:
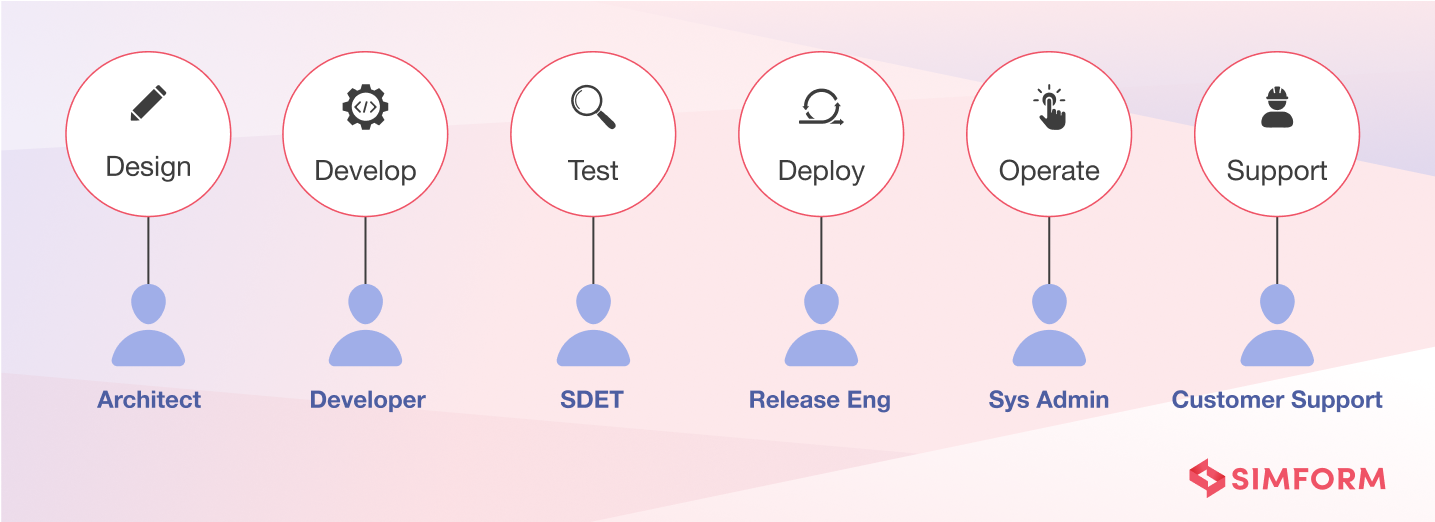
The specialized roles created efficiencies within each segment but created inefficiencies across the entire SDLC. The issues that they faced were:
- Individual silos that slowed down end-to-end progress
- Added communication overhead, bottlenecks and hampered effectiveness of feedback loops
- Knowledge transfers between developers and ops/SREs were lossy
- Higher time-to-detect and time-to-resolve for deployment problems
- Longer gaps between code complete and deployment, with releases taking weeks
Operate what you build
To deal with the above challenges and drawing inspiration from DevOps principles, Netflix encouraged shared ownership of the full SDLC and broke down silos. The teams developing a system were responsible for operating and supporting it. Each team owned its own deployment issues, performance bugs, alerting gaps, capacity planning, partner support, and so on.
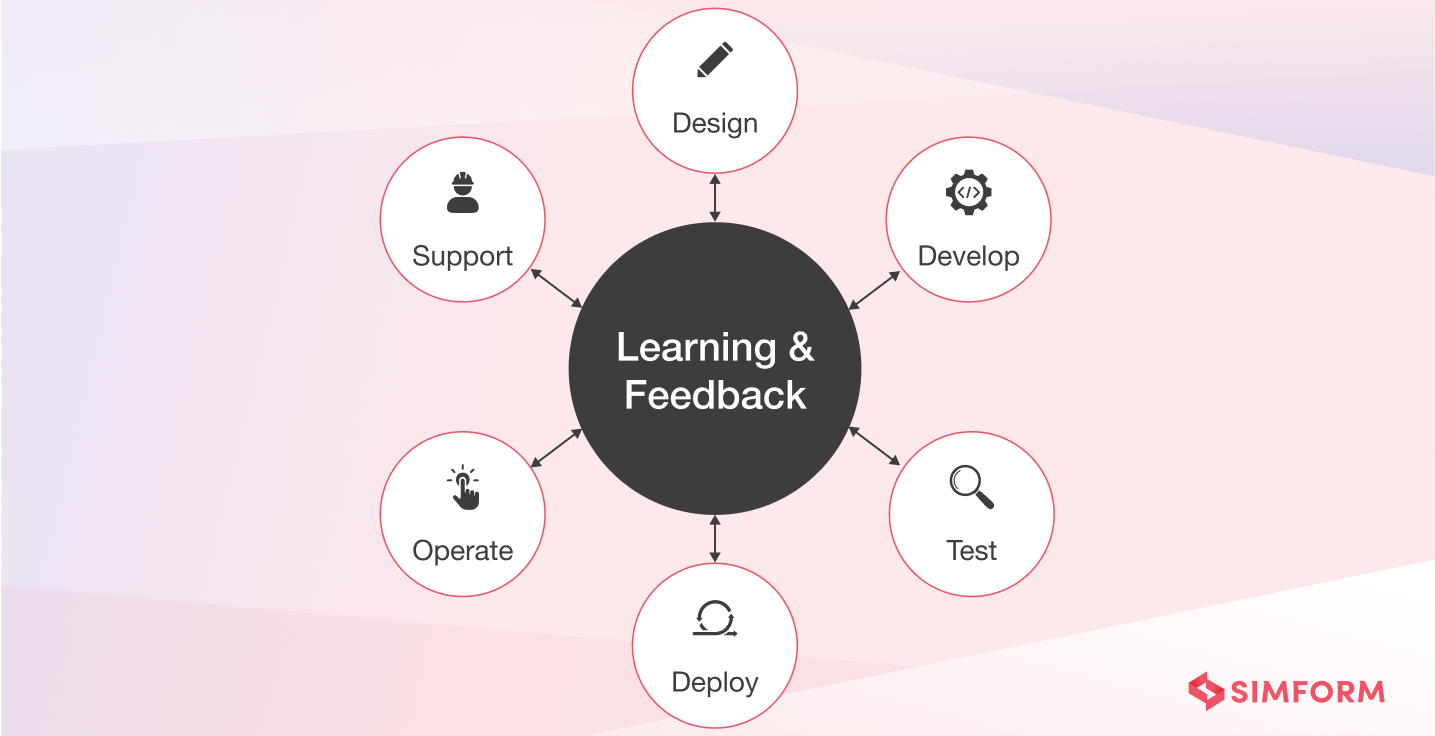
Moreover, they also introduced centralized tooling to simplify and automate dealing with common development problems of the teams. When additional tooling needs arise, the central team assesses if the needs are common across multiple development teams and built tools. In case of too team-specific problems, the development team decides if their need is important enough to solve on their own.
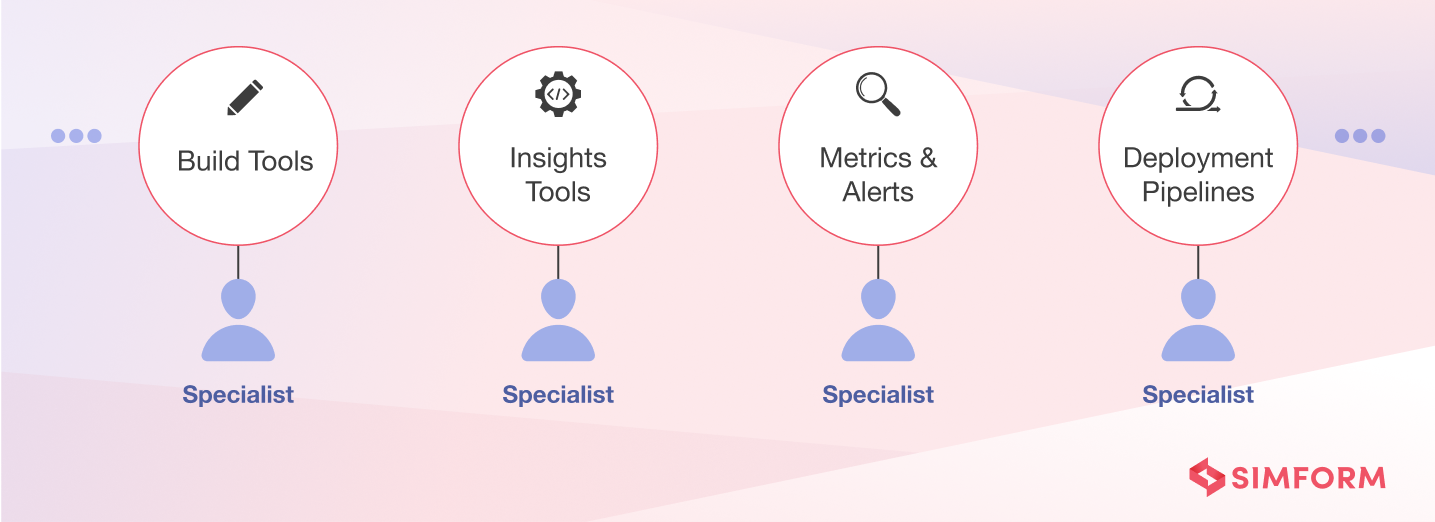
Full Cycle Developers
Combining the above ideas, Netflix built an even better model where dev teams are equipped with amazing productivity tools and are responsible for the entire SDLC, as shown below.
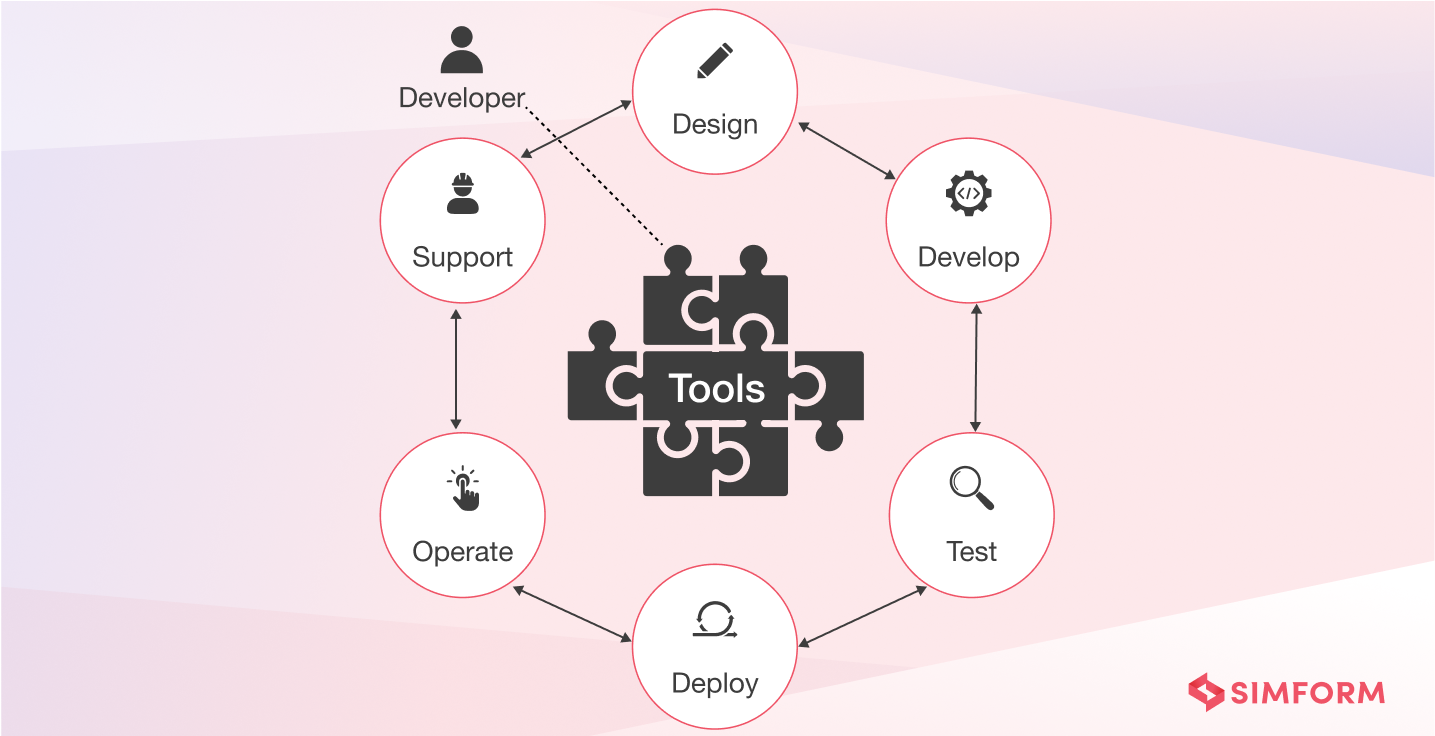
Netflix provided ongoing training and support in different forms (e.g., dev boot camps) to help new developers build up these skills. Easy-to-use tools for deployment pipelines also helped the developers, e.g., Spinnaker. It is a Continuous Delivery platform for releasing software changes with high velocity and confidence.
However, such models require a significant shift in the mindsets of teams/developers. To apply this model outside Netflix, you can start with evaluating what you need, count costs, and be mindful of bringing in the least amount of complexities necessary. And then attempt a mindset shift.
Lessons we can learn from Netflix’s DevOps strategy
Netflix practices are unique to their work environment and needs and might not suit all organizations. But here are a few lessons to learn from their DevOps strategy and apply:
- Don’t build systems that say no to your developers
Netflix has no push schedules, push windows, or crucibles that developers must go through to push their code into production. Instead, every engineer at Netflix has full access to the production environment. And there are neither strict policies nor procedures that prevent them from accessing the production environment.
- Focus on giving freedom and responsibility to the engineers
Netflix aims to hire intelligent people and provide them with the freedom to solve problems in their own way that they see as best. So it doesn’t have to create artificial constraints and guardrails to predict what their developers need to do. But instead, hire people who can develop a balance of freedom and responsibility.
- Don’t think about uptime at all costs
Netflix servers their millions of users with a near-perfect uptime. But it didn’t think about uptime when they started chaos testing their environment to deal with unexpected failure.
- Prize the velocity of innovation
Netflix wants its engineers to do fun, exciting things and develop new features to delight its customers with reduced time-to-market.
- Eliminate a lot of processes and procedures
They limit an organization from moving fast. So instead, Netflix focuses on hiring people they can trust and have independent decision-making capabilities.
- Practice context over control
Netflix doesn’t control and contain too much. What they do focus on is context. Managers at Netflix ensure that their teams have a quality and constant flow of context of the business, rather than controlling them.
- Don’t do a lot of required standards, but focus on enablement
Teams at Netflix can work with their choice of programming languages, libraries, frameworks, or IDEs as they see best. In addition, they don’t have to go through any research or approval processes to rewrite a portion of the system.
- Don’t do silos, walls, and fences
Netflix teams know where they fit in the ecosystem, their workings with other teams, dependents, and dependencies. There are no operational fences over which developers can throw the code for production.
- Adopt “you build it, you run it” culture
Netflix focuses on making ownership easy. So it has the “operate what you build” culture but with the enablement idea that we learned about earlier.
- Focus on data
Netflix is a data-driven, decision-driven company. It doesn’t do guesses or fall victim to gut instincts and traditional thinking. It invests in algorithms and systems that combs enormous amounts of data quickly and notify when there’s an issue.
- Always put customer satisfaction first
The end goal of DevOps is to make customer-driven and focus on enhancing the user experience with every release.
- Don’t do DevOps, but focus on the culture
At Netflix, DevOps emerged as the wonderful result of their healthy culture, thinking and practices.


How Simform can help
Netflix has been a gold standard in the DevOps world for years, but copy-pasting their culture might not work for every organization. DevOps is a mindset that requires molding your processes and organizational structure to continuously improve the software quality and increase your business value. DevOps can be approached through many practices such as automation, continuous integration, delivery, deployment, continuous testing, monitoring, and more.
At Simform, our engineering teams will help you streamline the delivery and deployment pipelines with the right DevOps toolchain and skills. Our DevOps managed services will help accelerate the product life cycle, innovate faster and achieve maximum business efficiency by delivering high-quality software with reduced time-to-market.
