In 2019, an IT outage at Lloyds Banking Group caused hundreds of thousands of payments to become stranded. Customers had to complain about troubles transferring money on Friday morning, which got annoying. By early afternoon that day, the bank had a backlog of roughly 400,000 unprocessed payments, and it had to request customers not to resend the payments since it could result in duplication.
Customers of the Lloyds, Bank of Scotland, and Halifax brands were affected by the outage.
Outages like this are caused by technical faults, as well as the lack of solid systems to back up such important transaction systems that are utilized by millions of people.
This blog explores why you need an architecture that protects your application from outages to safeguard your business, preserve your client base, generate income, and anything else that has to do with your “business money.”
After you’ve figured out “why,” find out what AWS has to offer in this area, then look at some design practices you might be overlooking when building distributed systems that require multi-region databases and architecture.
What are Compelling Reasons to Make Your Database Multi Region?
Disaster recovery
We frequently hear about breakdowns, outages, and revenue losses in the millions of dollars. The most prevalent causes of such outages are the loss of important data and users’ inability to add things to their shopping cart. Even when the ERP systems are integrated, data from the product databases of eCommerce websites may occasionally be missing. Alternatively, consumers may encounter only half-loaded data, resulting in extreme dissatisfaction and a higher bounce rate for the product or website owner.
Multinational enterprises require databases that span many locations and provide rapid failover. In such instances, a powerful and capable database is required to keep the organization running by enabling data replication and prioritizing business continuity over downtime.
Reduced latency for geographically dispersed users
Another major issue that multi-region databases can help you with is latency.
If your application and database are in the United States and your end customers are in Europe, the data flow will be routed through various routers to reach the database. This approach causes a greater delay in large-scale, distributed systems. You can avoid this problem by replicating the data using a multi-region database like DynamoDB in Europe and putting the application in the same area. This is one of the ways you can give your customers the experience they want.
When your application serves many geographies, you’ll need a point of presence in each one. You want the data as close to the end user as possible to reduce latency and provide the optimum user experience. If your users are from all over the world, this means you need to replicate data in the locations where they reside.
Keep latencies under 100 milliseconds as a rule of thumb. However, as data is restricted by the speed of light, keeping latencies under 100 ms can be difficult when a user base is distributed throughout the globe. Low latency is the only way to do that.
To give you an idea about globally scalable applications and the role of multi-region databases in it, here’s an example.
HomeAway(now Vrbo), the world’s top online vacation rental marketplace, seeks to assist families and friends in finding the ideal vacation rental so that they may share wonderful travel experiences.
While many families enjoy vacationing during the holidays, two-thirds of children are concerned that Santa will not find them if they are not at home on Christmas. As a result, during the holiday season in 2016, HomeAway launched a marketing effort to solve the problem. Soon, a website was launched that sends Santa updates about the child’s whereabouts.
Parents could breathe a sigh of relief, knowing that Santa had given their children a personalized letter informing them that he was aware of their whereabouts on Christmas Day. As a result, HomeAway was able to save Christmas for thousands of children (and their parents) all across the world.
The only difficulty here was that the HomeAway team had to launch the campaign globally on a very short timeline. This required the capacity to quickly deploy in many areas and languages worldwide while scaling to meet varying traffic demands.
Finally, HomeAway used AWS multi-region to build a quick, scalable, and global solution that allowed kids to tell Santa where they would be on Christmas. It was designed to be highly available, so even if one instance went down, the website would have remained operational, ensuring that no child missed the opportunity to notify Santa. They also created AWS auto-scaling architecture, and there was not a single failure throughout the campaign!
Active-Active architecture support
Some distributed databases are active/passive, which means that if the primary database fails, you won’t be able to create transactions until a new primary database is selected. Active/active architecture supports writing any node, which is one of its many advantages. When you combine numerous instances of an application with multiple database regions, you can keep serving users even if one of the regions goes down. It enables enterprises to simply increase the number of instances without modifying the application code.
Application architecture flexibility
You can simply scale up and down your applications with a multi-region design or database deployment. Here are the two main reasons behind this:
Cloud deployments
Your application and database will be distributed across numerous servers in multiple areas using a multi-region architecture. AWS, for example, makes this process simple by adding another regional server. And the database and application must be deployed to that specific server. You don’t even have to start from scratch if you already have Docker or Kubernetes deployment configuration files. In new locations, it becomes much easier to deploy apps.
Application logic
Every time you deploy an application in a new region, you don’t need to specify anything. You can continue to use the same application logic as before. In essence, you don’t need to make any significant code changes. For instance, suppose you’re a bank in one of Europe’s countries, such as Türkiye, and you want to grow in the United States. So if you already had multi-region deployment in the Europe region, it would be easy for you to do.
Less regulatory fines:
Businesses that expand internationally face a complex network of local data regulatory and compliance rules. When you have many applications or applications that serve customers globally, you can lessen the risk of being fined by implementing a method that allows you to store data in a specified location. This will help you comply with regulatory standards.
Minimal operational overhead and costs:
The costs of asynchronous disconnect active/passive systems are reduced by using a single logical database across multiple locations. In turn, it enables organizations to accomplish more with fewer resources because it does not require additional people to manage the database. So, you can run your enterprise with less staff administering the database, addressing problems, and keeping up with worldwide user needs.
What multi-region database architecture on AWS offers?
High availability
High availability is inevitable for apps that are used all over the world. These apps must be available in multiple regions and deliver the content that users worldwide have requested. A region is a physical area where various Availability Zones of AWS are located. These zones are made up of one or more distinct data centers with redundant power and connection that are housed in different locations.
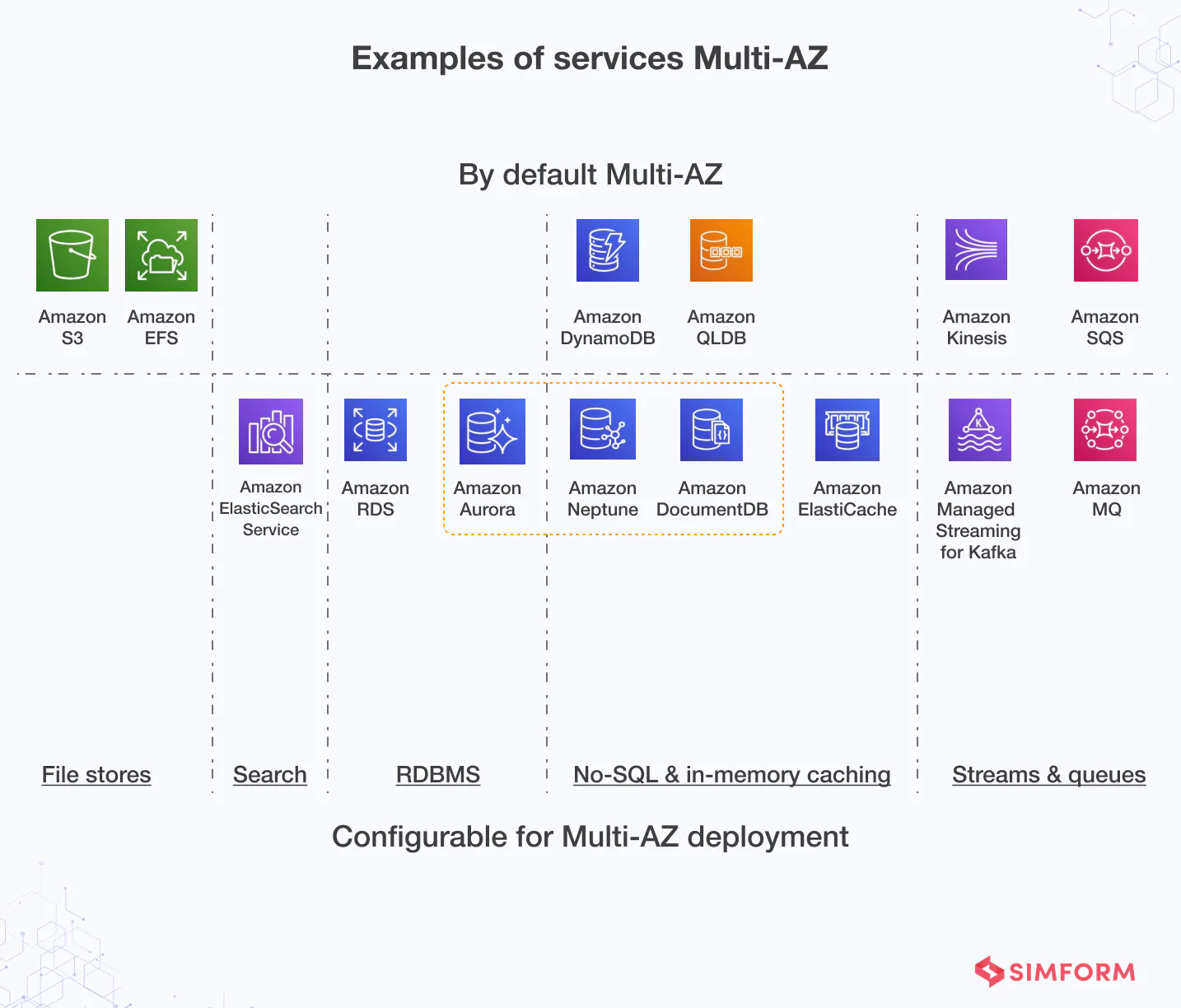
Spanning relational database across regions
Multi-Region capabilities in Amazon DynamoDB global tables enable you to construct global applications at scale. This enables programs to read and write in the Region closest to them, automatically propagating changes to additional Regions..
With global clusters, you can get global reads and fast recovery for Amazon DocumentDB. There is a principal region in these clusters that handles writing operations. Low-latency global reads with a lag of less than one second are possible because of dedicated storage-based replication infrastructure.
Data replication
Maintaining application speed requires keeping in-memory caches warm with the same data across regions. Amazon ElastiCache for Redis provides a fully managed, fast, reliable, and secure cross-Region replica for Redis caches and databases using a global datastore. Writes in one region can be read from up to two different cross-region replica clusters using a global datastore, avoiding the need to write to numerous caches to keep them warm.
Key features of Replication:
Scalability: As the volume of data grows, it is difficult to access and work with data. With multiple data copies accessible with replication, customers can expand their data reserves and recover any earlier version in case of any mistakes or malfunctions.
Performance: When data is accessible across different devices and servers, it can be easily retrieved even from unexpected and sudden failures. Data availability and security are always guaranteed with replication.
Availability: You don’t need to be worried about data failures if you’ve replication in place. You can simply retrieve the same up-to-date data from a secondary reserve in the event of primary data failures. This greatly enhances data accessibility.
Networking
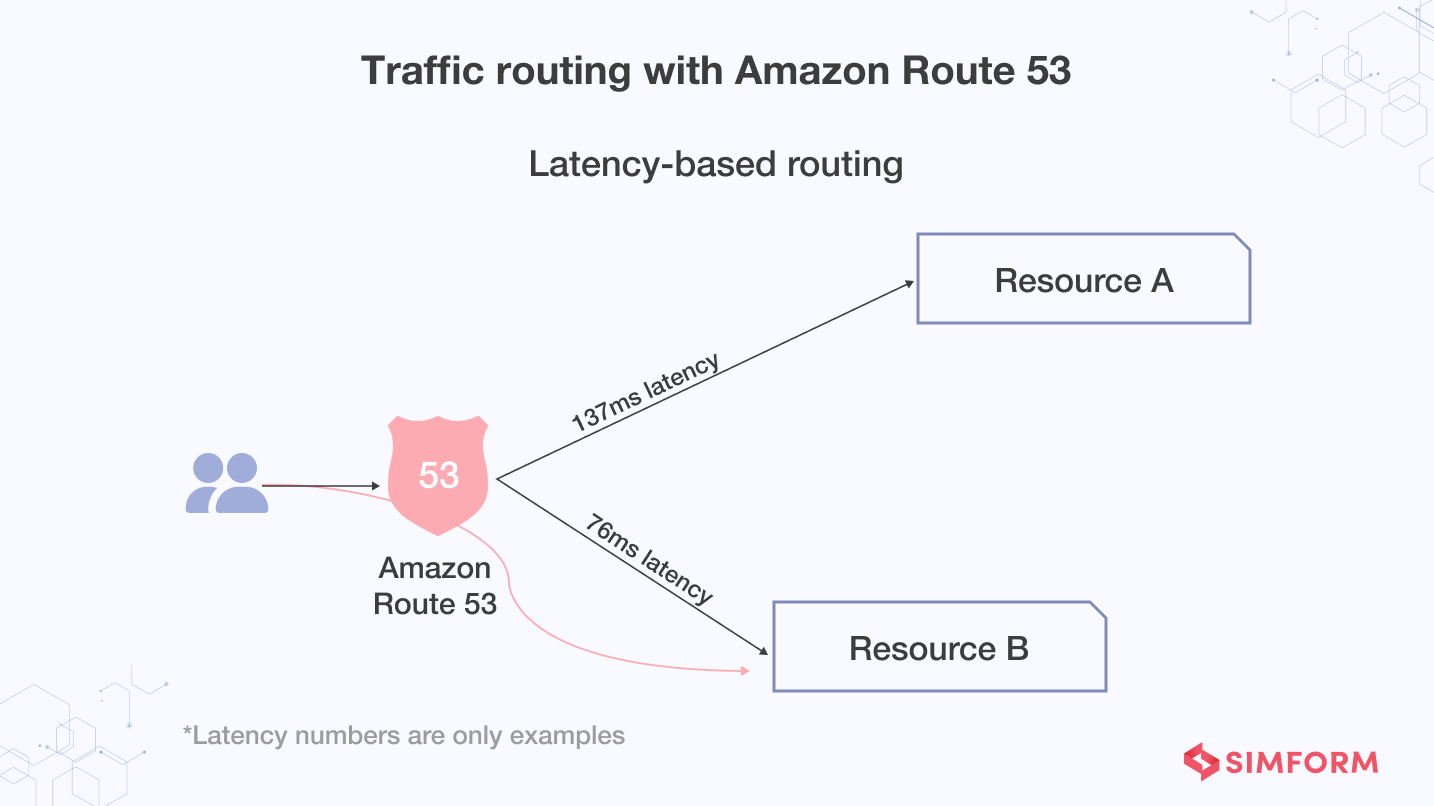
Traffic routing
Modern DNS services like Amazon Route 53 are used to route traffic based on multiple criteria, such as endpoint health, geographic location, and latency. The nature of AWS servers is distributed, ensuring a consistent ability for routing end users to the application. Amazon Route 53 Traffic Flow and routing control helps you improve reliability for easily-configured failover. And also helps reroute your users to an alternate location if your primary application endpoint becomes unavailable.
The Route 53 data planes are responsible for DNS queries and perform certain health checks.
Route 53 application recovery controller also gives you full control over highly available applications’ failover. It provides two features to manage and successfully failover: readiness checks and routing controls. Moreover, you can also use a process called “standby takes over primary” (STOP) for a healthy standby Region and application. Here you’ll need to use a resource in the standby Region to control the failover. However, it lets you initiate a failover without depending on resources in the primary Region.
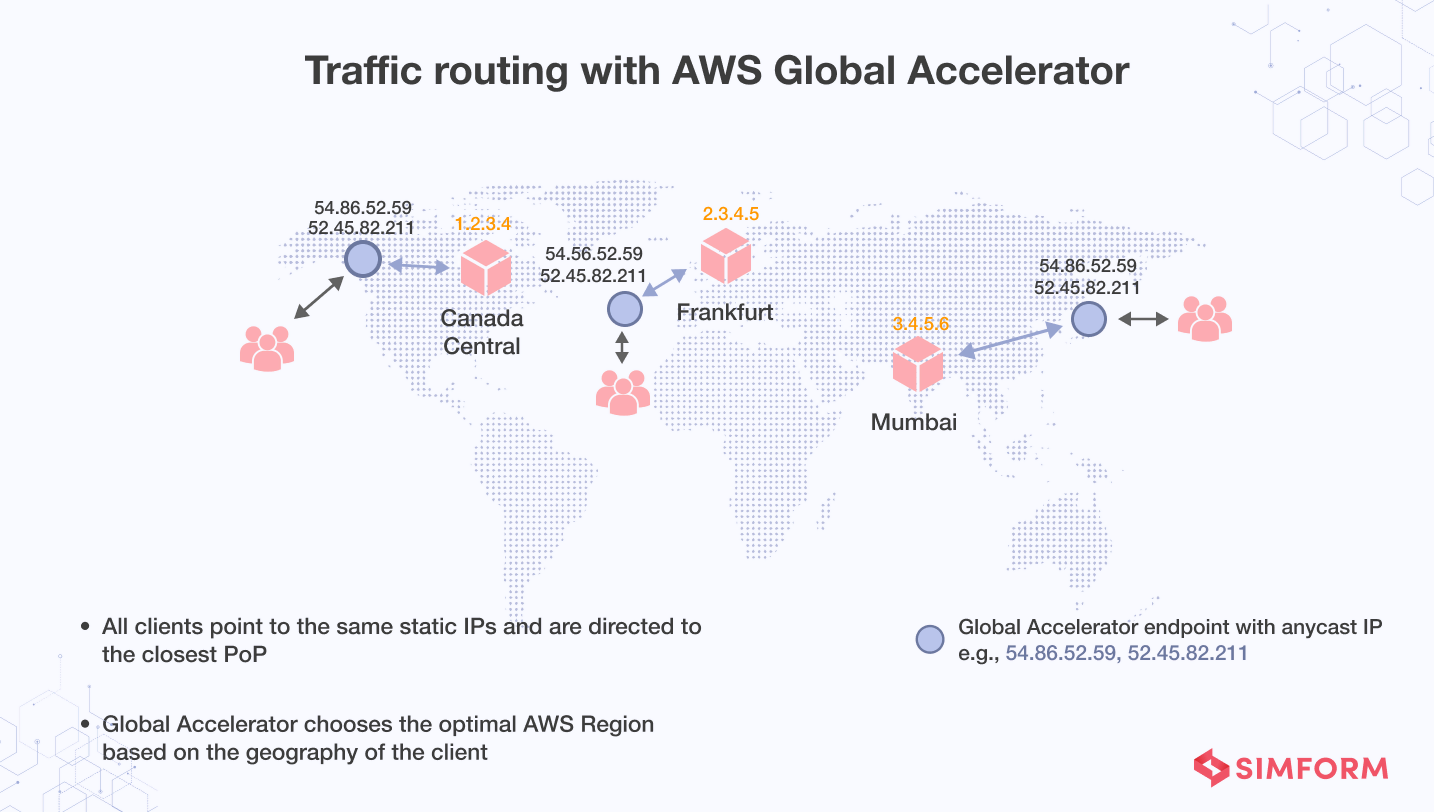
AWS Global Accelerator, on the other hand, is a networking solution that uses AWS’s global network infrastructure to boost the performance of users’ traffic by up to 60%. It’s useful for applications with an increasing number of endpoints and IP addresses that make adding and removing endpoints difficult. AWS Global Accelerator makes this procedure easier by giving users two static IP addresses that only need to be configured once.
Other use cases include increasing application resiliency and availability across several Availability Zones in a single AWS Region, as well as defending apps from malicious attacks.
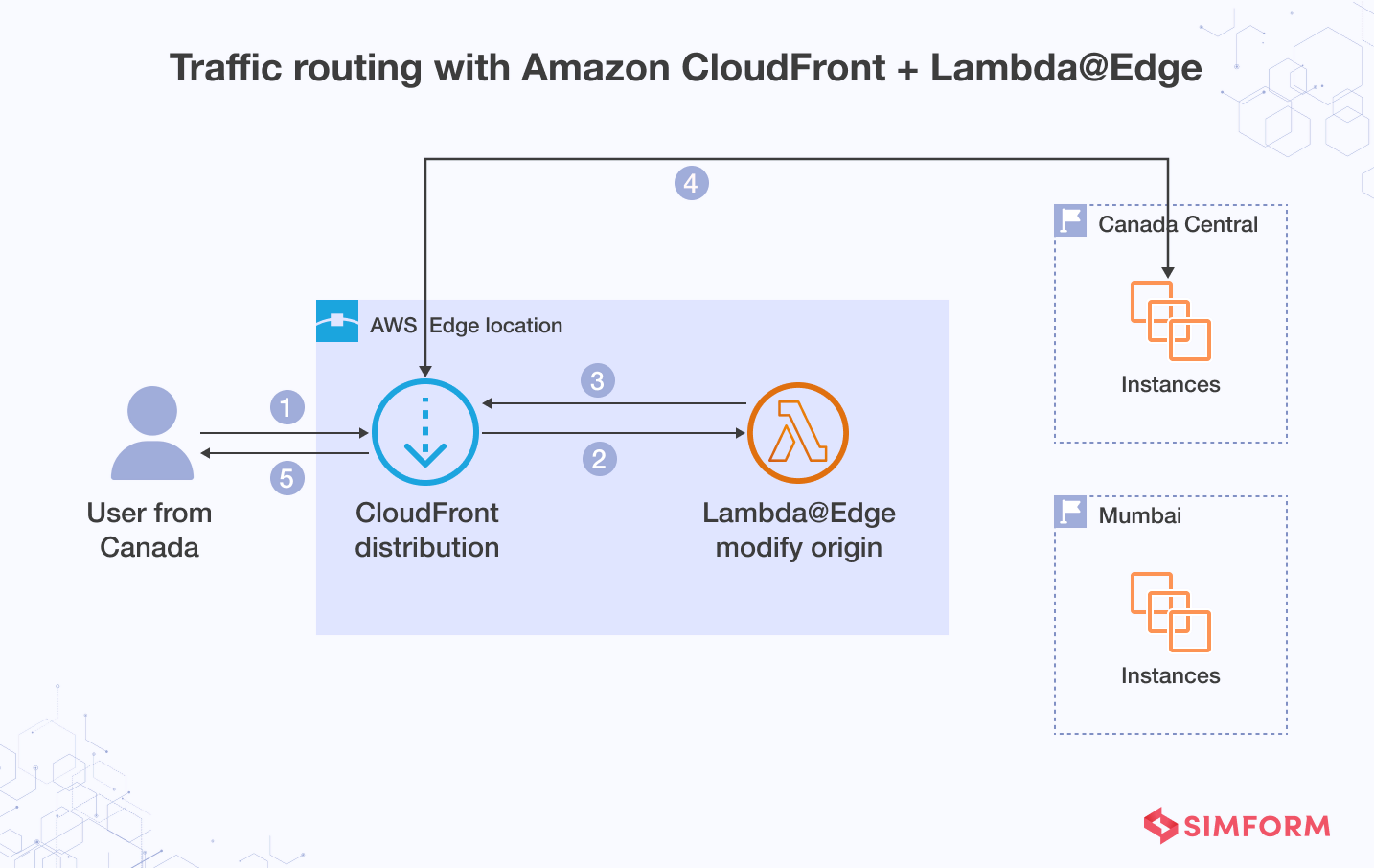
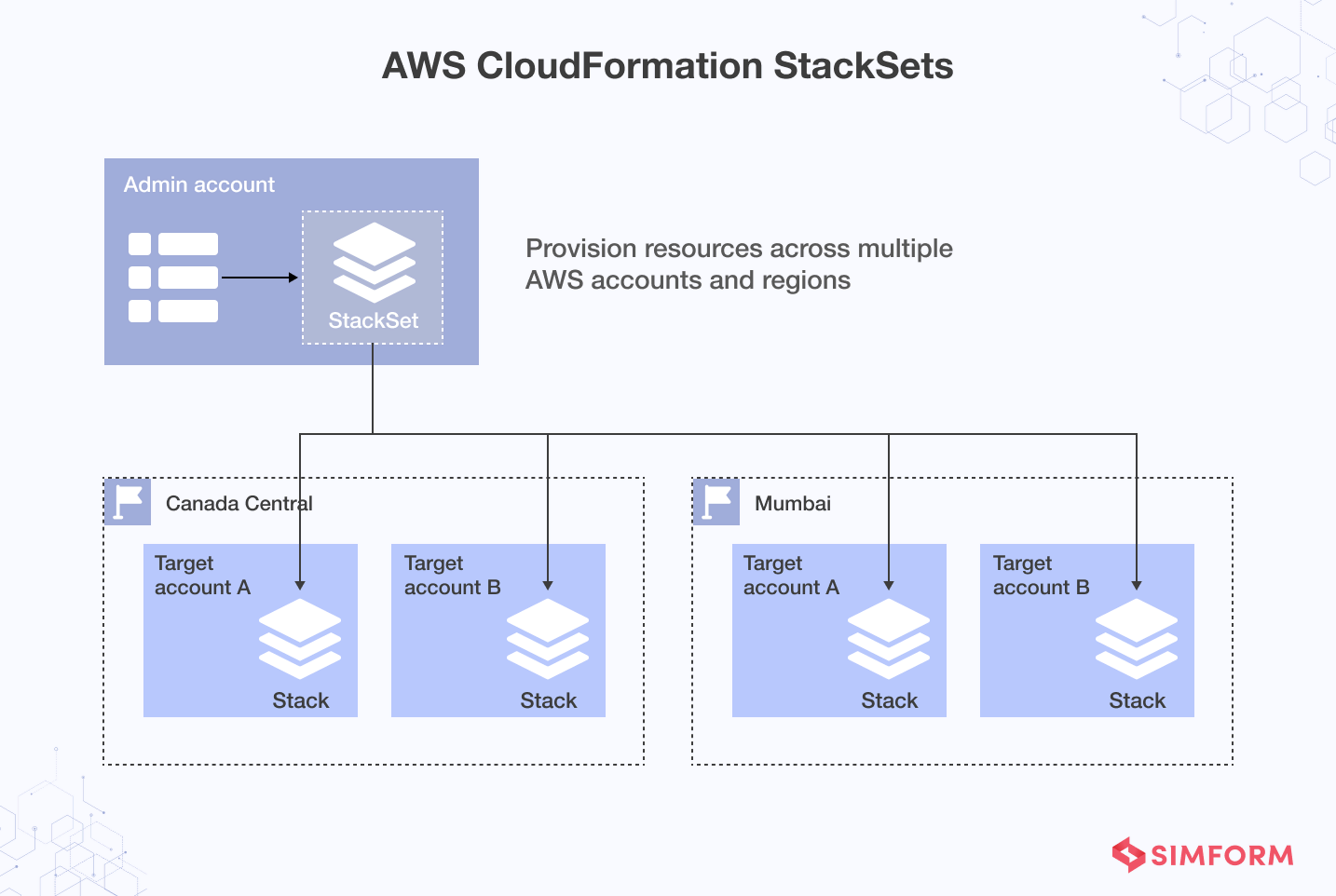
Management
Design practices for distributed systems
Software applications running on distributed computing systems require a communication network to connect multiple computers. These technologies, in general, convey data generated in one physical area to another. For example, a geographically distributed system could be massively played online games or social networking sites like Facebook.
Often, programmers mistake assuming false theories regarding distributed applications and end up with unexpected errors. For example, if proper practices or design principles are not followed,
- Applications with the distributed network may have to deal with networking errors due to poor error handling and failure to be available in network outages, and in some cases, it needs a manual restart.
- Easily becomes prone to security threats.
- Problems regarding bandwidth occur, resulting in performance bottlenecks.
- Scalability and concurrency issues persist.
It’s critical to keep some design techniques on hand to avoid such problems. We’ve gone through some of the most frequent and useful design principles used by businesses. These approaches are recommended for applications that place a high focus on consistent speed and scalability in their projects.
Make API responses idempotent
In distributed systems, it’s easy to perform operations or make requests at least once, but there’s no guarantee that it will be performed correctly. This uncertainty causes a client to send requests multiple times, resulting in multiple retries without a fear that the request will be erroneously processed. So here, it’s important to make all responses idempotent. One can do this by using idempotent tokens in APIs, which mutate the API requests and create repetitive records or side effects.
Use throttling of requests
Use this mitigation technique to deal with a sudden surge in demand. Requests are processed to some extent in distributed systems, but once they reach a certain threshold, they are refused and a message indicating that they have been throttled is returned. You must plan services based on the capacity of each node or cell to process requests. This amount can be estimated by performing load testing, which allows you to observe the rate at which requests arrive and determine if the temporary pace surpasses the rate at which requests are throttled. Throttling requests is made easier with the Amazon API Gateway. Amazon SQS and Kinesis buffer these requests, avoiding the requirement for throttling.
Think about consistency in the future
Banking, emergency services, and investment are examples of applications that require high availability. The recovery times for these apps are extremely quick. In such cases, you can use a Warm Standby method in AWS regions to reduce recovery times even more.
Read more about disaster recovery options in the cloud here.
You can distribute the full burden over both Regions, with your passive site being scaled back and all data eventually becoming consistent. In their respective regions, both deployments will be statically stable. Distributed system resiliency patterns should be used to build the applications. You’ll need to build a lightweight routing component that checks workload health and can divert traffic to the passive region if necessary.
Split services based on function
The first step is to divide the application into proper components.
Microservice-based architecture means creating software components that are easy to develop, scale and manage without depending on the other application units. The goal of designing a distributed system is to keep each component self-contained. Also, to maintain communication between the components. Most importantly, it’s about designing the architecture that isolates underperforming components or units and allows modification without affecting other units.
Practice sharding of services
A better option for replica-based designs is to construct a set of services that each fulfills a certain type of request. This is referred to as “sharding.”
As the size of the state is often too enormous for a single stateless container, sharded services are commonly utilized to develop stateful services. Sharding allows you to scale each shard to fit the size of the state.
You can also handle high-priority queries faster with sharded services. Shards dedicated to high-priority requests are always accessible to handle such requests as soon as they arrive.
Consider static stability
One of the most important factors to consider for large-scale applications is static stability. Instead of purchasing multiple new resources at once, it is recommended to achieve high availability. It is also employed to avoid the possibility of bimodal behavior in these systems. When a workload exhibits bimodal behavior, it behaves differently in normal and failure modes. For example, if an availability zone fails, you must rely on producing new instances. Instead of relying on instances, you should create a long-term system that is statically stable and only operates in one mode.
Static stability can be achieved using AWS Availability Zones, and you can see the factors that influence workload reliability, such as cost optimization. In large-scale systems, you need to analyze trade-offs like spending more on EC2 instances to achieve static stability or relying on automatic scaling when more capacity is required.
Expedia Group, for one, is a classic example for making applications more resilient using AWS services. After 2018, the company planned to move 80 percent of its mission-critical apps from on-premises to the cloud.
Thanks to AWS services for offering the ability to automatically scale to fit load requirements. The company was no longer required to meet peak hours needs using traditional data centers resources.
The engineering team at Expedia made applications more resilient using a multi-region, multi-availability zone design and a proprietary DNS solution.
The group could ensure speedier app development, scalability to process large volumes of data, and promptly troubleshoot difficulties by utilizing the AWS infrastructure in different Availability Zones. They were able to rely on many Availability Zones for availability and disaster recovery. Their engineering team is also working on establishing a monitoring infrastructure throughout the regions.
Adopt Microservices-based architecture
Microservices-based applications feature several independently functioning components that are distributed and kept in sync through communication channels. Each component maintains communication with other components in order to completely support all network operations and meet the system’s future needs.
Microservices in distributed systems employ REST APIs to connect microservices and make the application more resource-oriented. It streamlines the overall flow of the application’s functionalities. Microservices also use container-based virtualization, such as Docker, which provides developers with greater control over resources and functionality.
Last but not least, the scalability provided by microservices design is tremendous. This is because microservices provide concurrency, a key feature of scalable systems, and functionalities are broken down into smaller chunks, making them easier to scale and integrate with third-party systems.
Key Takeaways on Multi-region Databases and AWS Architecture
The multi-region database has many benefits. But still, many enterprises seem to be not adopting such a pattern. One of many reasons could be the costs associated with it. The price is related to the hardware required in each region regardless of its actual usage. But that’s where cloud technologies step in. AWS, for example, offers you a serverless model where you can utilize the pay-as-you-go pricing model to meet the on-demand requests. On-demand scaling of databases is possible, and so is the initialization of it.
Cloud services providers these days offer you a full-stack solution to every problem you deal with. You need an extended team with expertise in building cloud-based enterprise applications like Simform. We’re an Premier Consulting Partner of AWS, making us a strong team of AWS-certified solution architects and cloud consultants. We’ve helped customers facing issues in expanding their apps globally and introduced the true potential of cloud technologies. Get in touch with us on any subject cloud, serverless or multi-region databases, and get a clear idea of what could be your next step!

