SPAR NL, a leading convenience store chain in the Netherlands with nearly 450 locations, struggled with fragmented systems that slowed down order processing and limited real-time visibility across stores. To address this, the company rebuilt its integration layer using an event-driven, serverless architecture on Microsoft Azure.
From powering real-time retail operations to enabling modern digital platforms, serverless architecture has become a foundational approach for building scalable, efficient systems. It allows organizations to focus on business outcomes while cloud platforms handle infrastructure, scaling, and execution.
So, what exactly is serverless architecture? And how does it help reduce resource management? We will discuss serverless architecture’s aspects, including challenges, benefits, examples, etc. Let’s begin with the basics first!
What is Serverless Architecture?
Serverless architecture is a way to build and run applications that reduce the need for resource management. Such an approach enables organizations to run applications without managing the physical servers.
Cloud providers play a key role in serverless architecture by executing code and dynamically allocating resources and scaling infrastructure. Examples of serverless computing platforms are AWS Lambda, Azure Functions, Google Cloud Functions, etc.
Serverless offerings are divided into two main categories.
- Backend as a Service (BaaS) lets developers focus on managing the front end of applications and rid them of backend development tasks like hosting cloud storage and database management.
- Function as a Service (FaaS) is an event-driven execution model that executes small code modules. It triggers the functions when the execution of certain events happens in application modules.
Now that we know what serverless is, here is “what isn’t serverless?”
Platform as a Service (PaaS) is not the same as serverless FaaS.
Most PaaS applications are not event-driven, while FaaS apps are. You can configure auto-scaling in PaaS, but configuring it for each request without a specific traffic profile is tricky. Hence, serverless FaaS is different from PaaS.
How does serverless architecture work?
Serverless architecture shifts the resource management to third-party service providers and saves time otherwise spent on updating, patching, and managing servers.
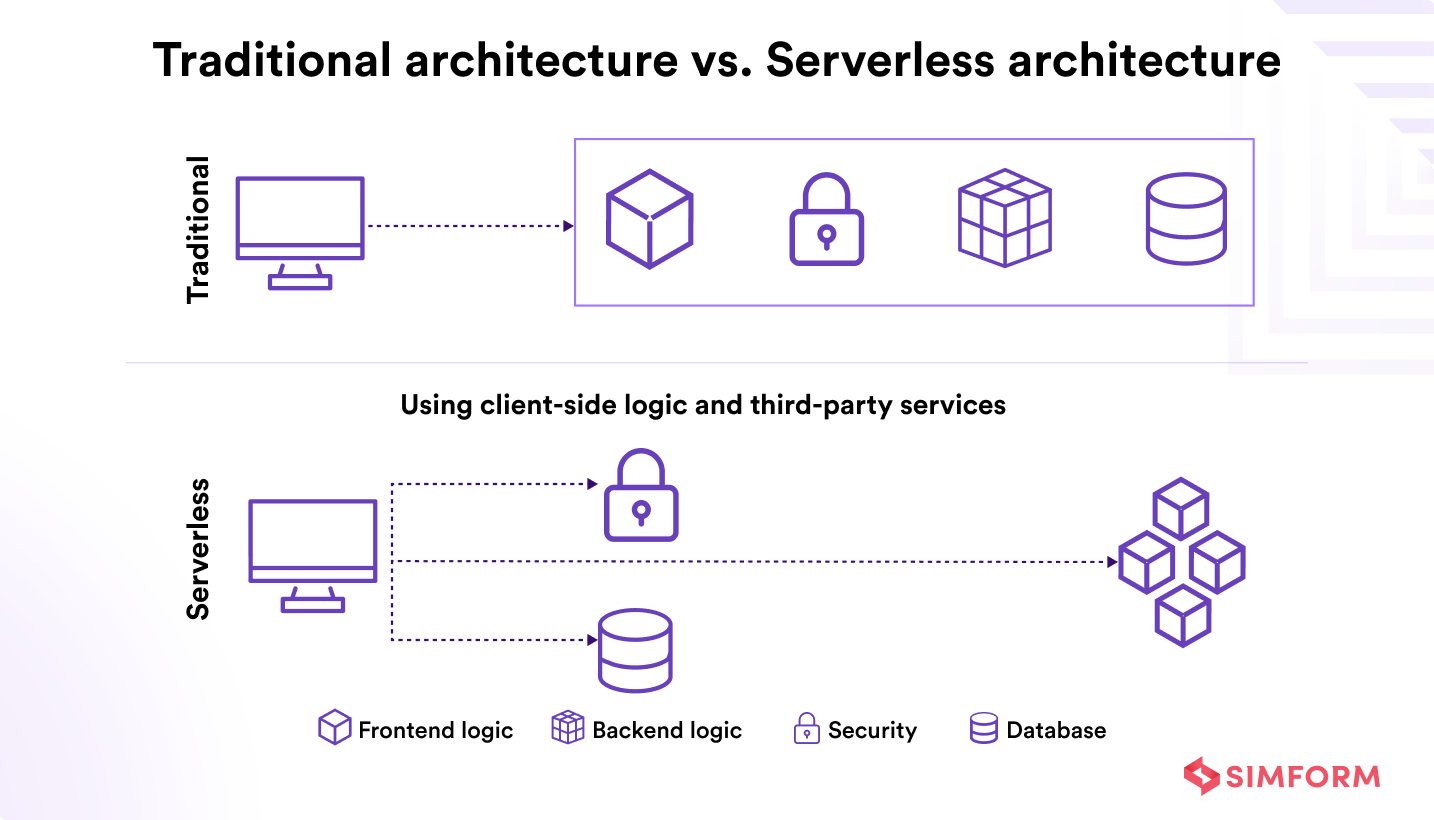
The traditional approach couples the frontend logic, backend logic, security, and database without separating concerns. But this can obstruct businesses from seamlessly adapting to evolving demands.
Thus, businesses need an architecture that can scale as per requirements and is flexible and reliable.
The serverless approach encourages the separation of concerns. The frontend logic is decoupled from backend logic, database, and security services. All the backend services communicate with frontend logic through APIs.
Let’s look into these building blocks that define how serverless architecture works.
Key elements of serverless architecture
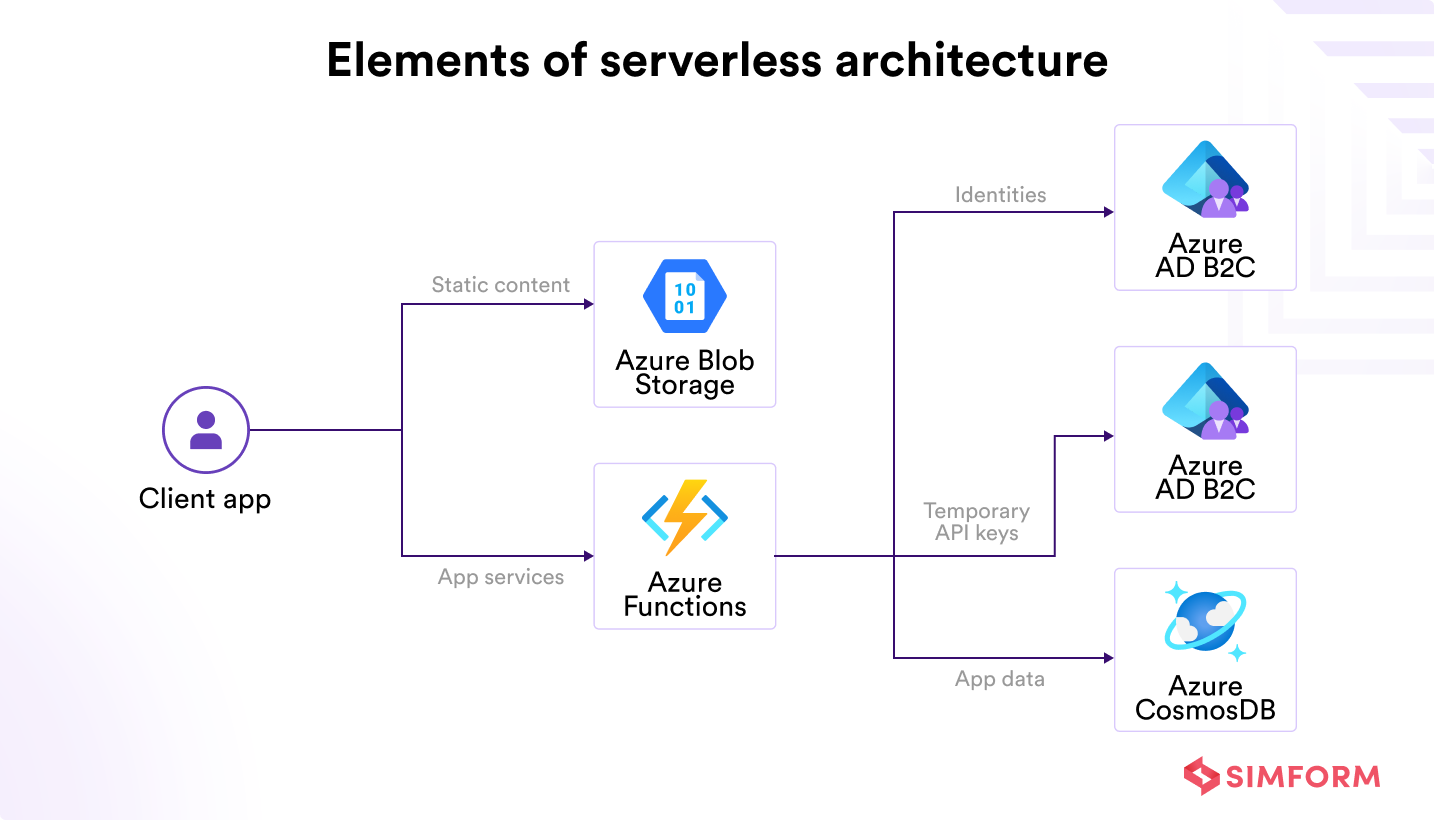
(To better explain how these elements work in unison, here is an example of an Azure serverless architecture.)
The key components of a standard serverless architecture includes,
- Client app is where the user interface is rendered, typically using a modern JavaScript framework (React, Angular, etc.). The client app is often hosted on a static web server and communicates with backend services via API calls.
- Static content hosting is handled using Azure Blob Storage with static website hosting, which serves HTML, CSS, and JavaScript files efficiently at scale.
- Azure Functions (FaaS) serve as the compute layer that executes backend code in response to events, such as HTTP requests, queue triggers, or changes in data. For example, you can implement login validation or data processing logic in Azure Functions, scaling automatically with demand.
- Security token service(STS) is a temporary credential-generating service to invoke Azure functions for the client application.
- User authentication service ensures that data access is provided based on the user’s identity and pre-defined privileges. For example, Azure Active Directory B2C allows you to add signup and authentication across different devices. It also enables organizations to issue temporary credentials and authenticate users for data access.
- A fully managed NoSQL database provides high availability, low latency, and elastic scalability for your web applications in a serverless architecture.
The above elements collectively contribute to the efficiency, scalability, and modularity of serverless systems. However, it is also crucial to understand the core principles/concepts that underlie serverless architecture.
Fundamental concepts in serverless architecture
Here are several key terms and concepts commonly employed in the context of serverless technology architecture.
- Functions
At the heart of serverless architecture are functions or pieces of code that are executed in response to events or triggers. These functions are small, stateless, and typically short-lived.
- Invocation
It is the triggering of a serverless function in response to an event or request.
- Duration
It represents the time it takes for a serverless function to execute from start to finish.
- Cold Start
Cold start occurs when a function experiences increased latency when invoked for the first time or after being idle for a while.
- Concurrency Limit
Concurrency limit is the maximum number of instances of a function that can run simultaneously in a serverless environment.
- Timeout
Timeout is the maximum allowable execution time for a serverless function before it is terminated.
- Event-driven
Serverless systems are inherently event-driven. Events, such as HTTP requests, database changes, or file uploads, trigger the execution of functions.
- Statelessness
Serverless functions are stateless, meaning they do not store data or maintain state between invocations. Instead, they rely on external storage solutions or databases.
- Microservices
Serverless encourages the decomposition of applications into small, modular, and independently deployable functions or microservices.
These basic concepts are crucial for effectively designing, developing, and deploying applications in a serverless
Why adopt serverless architecture?
Many advantages of serverless architecture make it popular among organizations, such as cost efficiency, flexible scaling, improved app performance, high development speed, etc.
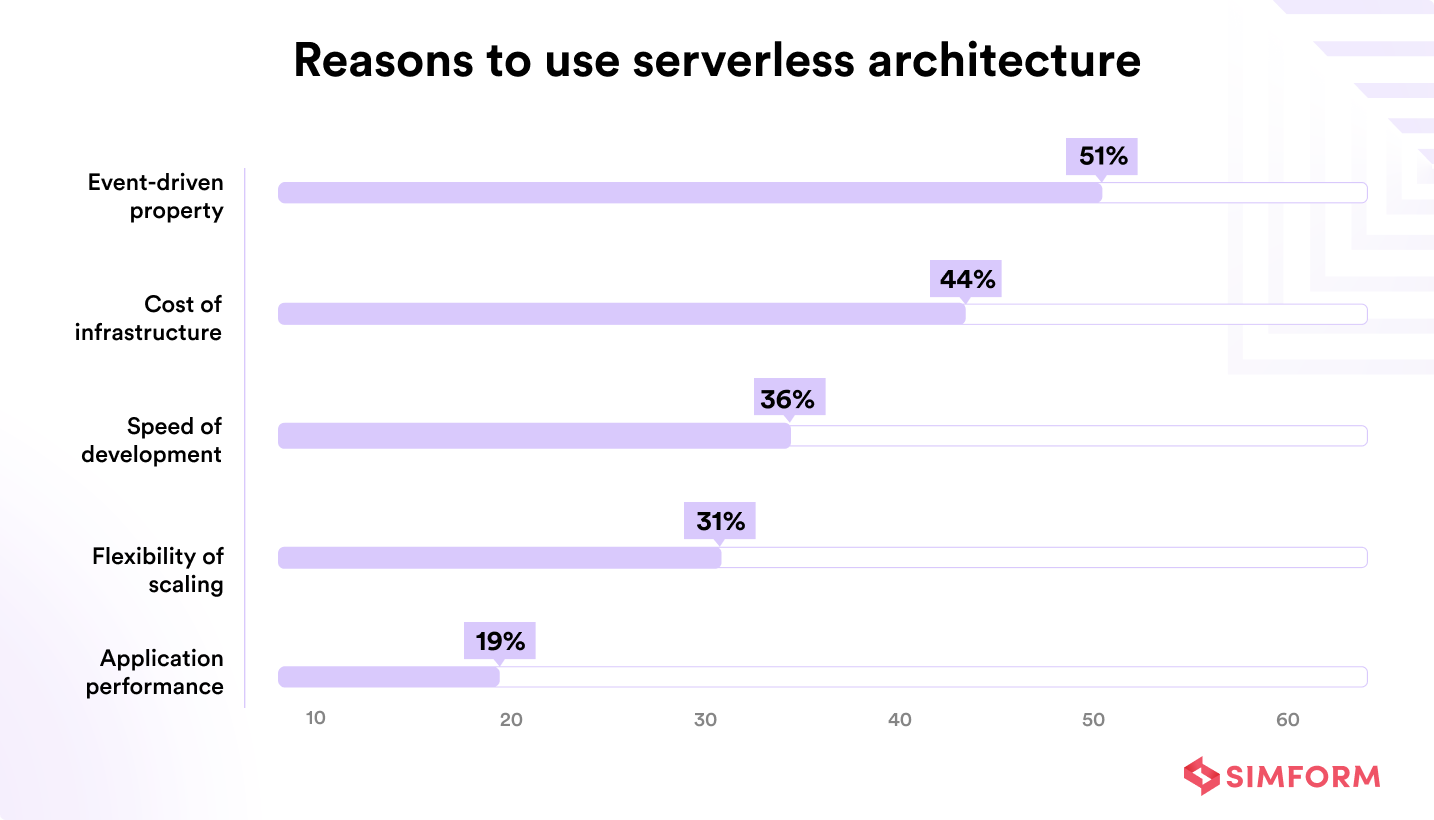
A survey indicates that the adoption of an event-driven approach is the primary reason businesses use serverless architecture.
Business benefits of serverless architecture
- Reduced operational cost- Serverless architecture patterns minimize the need for resource management and offer auto-scaling, resulting in reduced operational costs. Further, you benefit from shared infrastructure and labor cost gains.
- Reduced development cost- Standard functionalities like push notifications and version-specific messages need a shared codebase. However, you can use BaaS services rather than creating a code for each service. For example, if you need an authentication service, you can use Auth0.
- Pay-per-use pricing- You will save money with serverless architecture using FaaS platforms, which allows you to only pay for the computing resources you need. Platforms like Azure Functions manage resource allocation automatically, eliminating the need to provision for peak capacity.
- Brings more agility- Serverless computing lets development teams focus on building core products, designing scalable and reliable systems, and handling the infrastructure. Hence, reducing the products’ time-to-market, providing more agility, and quick deliveries.
- Complete utilization of resources- The serverless architecture eliminates the need for heavy lifting related to scaling and managing servers with its built-in fault tolerance capacity. As a result, it does not require developers to worry about boilerplate code and components.
- Better user experience- With serverless applications, you can ship new features daily and as quickly as possible. This makes for better user experiences as you will fulfill customer demands for new features and quick bug fixes without making them wait longer.
Serverless architecture examples
From leading companies like Chipotle to SPAR NL and many others, serverless architecture has been the go-to solution.
Chipotle rebuilt its web experience using an Azure serverless stack
Chipotle was operating three separate customer-facing websites, each requiring manual updates and developer time, even for small content changes. The company needed a unified, modern solution that could scale quickly and reduce operational overhead.
It rebuilt the site using a serverless architecture on Azure. Static content is served via Blob Storage and CDN, while dynamic interactions like orders and store-level menu updates are handled through Azure Functions. API Management routes these requests to backend systems, and Cosmos DB stores order data in a flexible JSON format.
With Azure’s serverless stack, Chipotle launched the new site in under 8 months, enabled real-time content changes without developer support, and eliminated infrastructure maintenance.
SparePartsNow built a scalable B2B marketplace using Azure serverless
SparePartsNow built a B2B platform to connect industrial parts manufacturers with buyers through a single digital channel. The goal was to automate order workflows, reduce infrastructure effort, and support fast feature rollouts with a small team.
The team built the platform using Azure Functions and Durable Functions to automate order workflows like customer verification, payments, and delivery coordination. Azure App Service hosted the Next.js frontend, while Azure AD B2C handled user authentication across buyers and retailers.
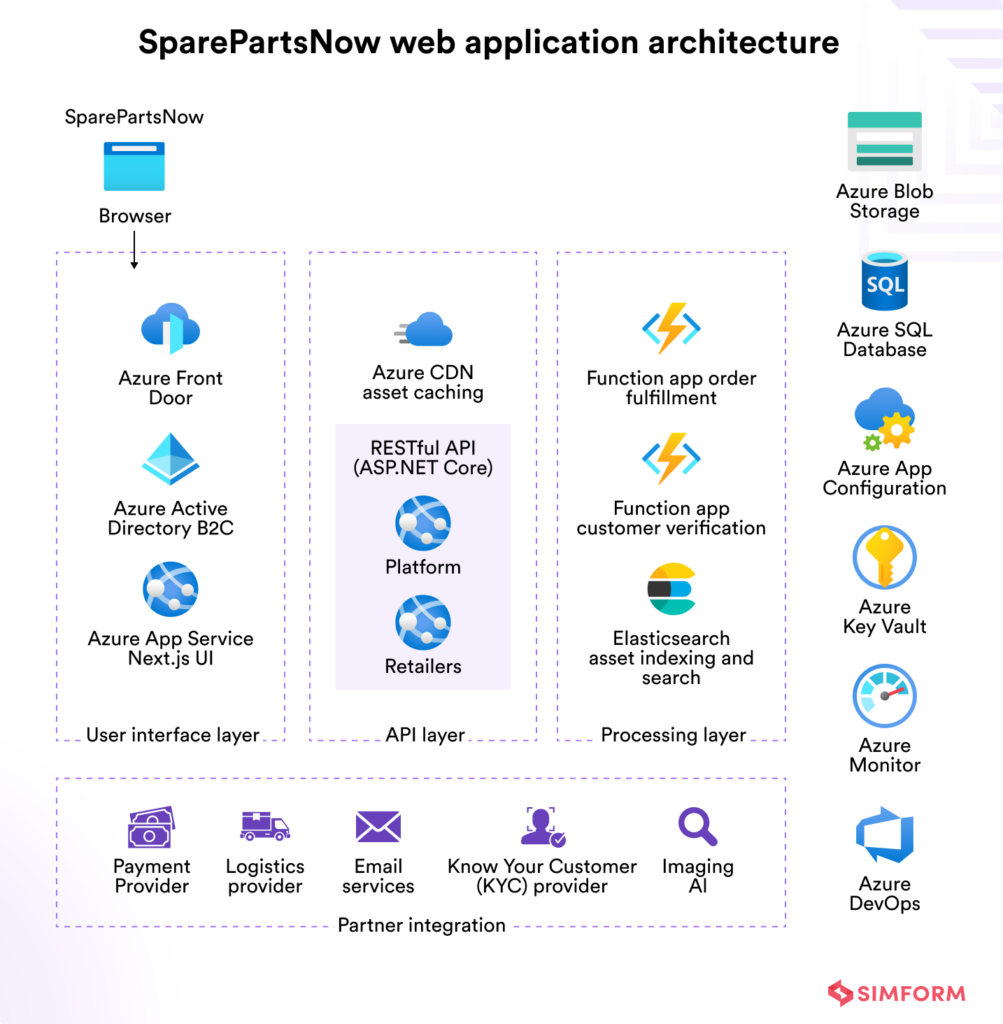
Every order triggered event-driven functions that processed transactions, integrated with logistics partners, and updated inventory in real time. Product data was indexed using Elasticsearch and stored in Azure SQL Database and Blob Storage. Azure Monitor and Key Vault ensured secure operations and visibility across services.
With Azure’s serverless platform, SparePartsNow launched in weeks and scaled reliably, processing thousands of orders daily with minimal infrastructure overhead.
When to use a serverless architecture?
Here is the list of use cases for serverless architecture showcasing the scenarios where it can be implemented in your applications.
- To implement asynchronous message processing in applications
- To process data to enable powerful machine learning insights
- Build high-latency, real-time applications like multimedia apps to execute automatic allocation of memory and complex data processing
- To serve unpredictable workloads for rapidly changing developmental needs, customer demands feature addition and other complex scalability needs
- To dynamically resize images or transcode video and simplify multimedia processing for different devices
- To build a shared delivery dispatch system
- For Internet of Things(IoT)-based applications and smart devices
- In live video broadcasting scenarios based application modules
- For event-triggered computing – scenarios that involve multiple devices to access various file types
- To implement stream processing at scale
- For the orchestration of microservice workloads
- To perform security checks
- To support service integrations for multi-language to meet the demands of modern software
- To implement Continuous Integration(CI) and Continuous Delivery(CD)
No doubt, serverless reduces administrative overhead. It takes the server maintenance off the developer’s plates and reduces overall server costs. But, there are some limitations also.
When not to use a serverless architecture
Serverless shouldn’t be considered when:
- You need control over the hardware
- You need a deep feature set
- When workloads require a high level of security
- When you can find a cost-effective, high-performing alternate solution
Challenges of serverless architecture
Serverless architecture has several advantages. Still, implementing it has many challenges, such as cold start, vendor lock-ins, and more.
#1. Cold starts
Cold starts are delays that occur when you invoke serverless functions after a long time. It causes a few seconds of delays for the functions to run and hampers productivity. One of the critical reasons for cold starts is the dependencies of serverless functions.
For example, if you call a serverless function, all the dependencies will automatically get imported into the containers increasing the latency. Another reason for cold startups is large functions requiring more time for setup.
#2. Vendor lock-ins
Vendor lock-ins are a significant challenge for organizations opting for serverless architecture at different levels, like API, cloud services, and more.
For example, many organizations have tightly coupled APIs with serverless infrastructure, causing issues when they want to move away from a specific vendor.
Similarly, many companies use specific cloud services and couple them with serverless architecture. For example, Azure cloud services work best with their serverless offerings like Azure Functions and Logic Apps.
However, if you want to use cloud services from other vendors, a tightly coupled serverless architecture becomes a bottleneck.
#3. Opinionated application design
Serverless architecture has specific requirements you must fulfill while designing your applications. For example, your app design must be cloud compatible. In other words, some app components need to be deployable on the cloud.
Further, serverless architecture works best with the microservices approach. You can add monolithic services to the app with serverless architecture, but performance and efficiency will see some impact.
#4. Stateless executions
Serverless architecture offers stateless executions, which can cause issues as caching might accumulate only parts of the required information.
In other words, the state is not shared between invocation of functions, and you need to design your apps to have all the information before executing internally.
Further, every external state needs to be fetched at the beginning of execution and exported before you finish executing a function.
#5. Debugging insights
Serverless architecture inherently restricts application debugging insights. For example, the entire infrastructure is in the serverless environment offered by the cloud service providers.
So, you don’t have visibility over the complete code for debugging. You will have access to function logs and specific components to do so.
Criticisms of serverless architecture
Despite being popular for its scalability, affordability, and flexibility, serverless architecture is not without its detractors. Here are some of the potential drawbacks of serverless architecture to be considered.
- Long-running workloads are more costly on ongoing serverless than dedicated servers
- Delays when processing the cold-start request while executing functions
- Higher dependency on your providers for debugging and monitoring tools and limited control over the platform’s architecture and availability
- Increasing complexity and chaos due to a lack of balance between the functions.
- Difficulty in conducting integration testing for a group of deployed functions due to small-sized modules
Best Practices for implementing a serverless architecture
Designing serverless applications with an optimal solution is the best way to start. Your goal of designing a decoupled, stateless application is possible with the simplicity of the design of serverless architectures.
#1. Manage code repositories
You can use serverless development frameworks, such as Azure Functions Core Tools or Azure Static Web Apps CLI, to break application functionality into smaller services, each managed in its own repository.
Managing the entire application logic in a monolithic repo becomes unmanageable as your serverless solution scales. By organizing code in smaller repositories per function or microservice, you ensure modularity, simplify CI/CD workflows, and promote faster iteration.
#2. Use fewer libraries
Minimizing external dependencies helps reduce cold start latency in platforms like Azure Functions. The more libraries a function loads, the longer it takes to initialize.
To improve performance, ensure that your serverless functions only include essential libraries. Keeping function packages lightweight leads to faster execution and better scalability.
#3. Use platform-agnostic programming languages
One of the best ways to reduce dependencies and vendor lock-ins is to leverage platform-agnostic programming languages. Rather than using multiple programming languages, stick to the one that most platforms support.
For example, Javascript is an excellent choice for serverless architecture as it is supported across many platforms.
#4. Analyze instances and memory requirements
Knowing the number of active instances and their related costs is essential before designing a serverless application. Also, know how much memory is required to execute the functions.
This will help you develop scalable serverless applications and help you build less complex serverless applications.
#5. Write single-purpose codes
Single-purpose codes are easier to test, deploy, explain, and understand. This will also limit the execution of more functions saving costs with reduced bugs and dependencies.
Writing single functions for your serverless apps will make them less complex and more agile, increasing the development speed.
#6. Develop and deploy powerful frontends.
Designing strong frontends lets you execute complex functionalities on the client side, reducing costs by minimizing execution times and function calls.
This will be easier when users want an immediate and seamless result over their actions. They could easily access the application features, improving application performance and user experience.
Popular serverless platforms
A primary advantage of serverless architecture is offloading all infrastructure management responsibilities to a third party. So naturally, our ability to create serverless applications relies heavily on the services at our disposal.
Today, numerous cloud service providers offer extensive portfolios of well-established serverless services. Let’s take a look at some of the popular ones.
- Microsoft Azure Functions
Azure Functions is Microsoft’s serverless computing platform, seamlessly integrated with the Azure cloud ecosystem. It also supports various programming languages and allows developers to build event-driven, scalable applications with ease.
- Amazon Web Services (AWS) Lambda
AWS Lambda, FaaS by AWS, remains dominant in the serverless ecosystem. It is a compute service that lets you run code without provisioning or managing servers. It supports multiple programming languages, event triggers, container image, and seamless integration with other AWS services. Thus, you can easily create, deploy, and scale functions using Lambda.
- Google Cloud Functions
Google Cloud Functions is Google’s FaaS offering, enabling developers to build and deploy event-driven architectures that automatically scale based on traffic. It’s tightly integrated with Google Cloud services, making it a preferred choice for many organizations using Google Cloud.
Other services also popularly used for serverless computing include IBM Cloud Functions (formerly OpenWhisk), Alibaba Cloud Function Compute, Oracle Cloud Functions, and the popular open-source tool Serverless Framework.
The big picture
Simform built a serverless IoT platform on Azure for Scandinavia’s second-largest general insurer to enable real-time fleet tracking and predictive maintenance.
They needed to process large volumes of telemetric data from vehicle sensors to help fleet managers monitor vehicle health, driver behavior, and unauthorized usage.
Simform designed a cloud-native, serverless architecture using Azure services, where each IoT subsystem was built as an independently deployable microservice. This allowed the platform to scale seamlessly based on data load and usage patterns, ensuring real-time performance and system resilience.
As a result, they achieved a 50% reduction in operational costs and a 2x improvement in the accuracy of insurance and claim generation.
So, if you want to go serverless, sign-up for a 30-minute session with our experts for fantastic ROI!
FAQs
Companies ensure data privacy and security in serverless architecture by implementing robust measures like encryption, access controls, and audits. Choosing reputable third-party providers with strong security protocols further mitigates risks.
Yes, serverless architecture can handle such applications efficiently. While platforms may have limitations on execution time and memory, leveraging distributed computing capabilities allows for efficient processing of large datasets or intensive calculations.
Yes, serverless architecture may pose challenges in debugging due to limited infrastructure visibility and managing dependencies across functions. Tools like version control and CI/CD pipelines are vital for streamlining workflows and fostering collaboration among team members.

David T
I'm curious how would serverless apply to stateful connection-persistent services like live video streaming using RTSP or RTMP. As I understand, service usually needs to establish a persistent connection to a camera and start transcoding incoming packets/frames and then serve to clients of the service (the serving part can be stateless). I can't wrap my head around how to turn this scenario into a fully serverless setup. If you would shed some light on a general direction, I greatly appreciate.
Raul
For me a very critical factor is the cold/warm issue. I don't know about AWS, but with Azure Functions it can take as long as 5 seconds to get a response in a cold start. As of today, we work around this problem with a "ping" to the functions to keep them alive.
Jignesh Solanki
True, cold startup time along with concurrency and identifying optimum memory size are critical for your serverless application. So far we have observed good performance with AWS Lambda - worst startup time being 3000ms. There are many other solutions for this problem such as minimizing deployment package size of the function and leverage the container reuse by lazily loading variables. I have discussed some more challenges in this blog - https://www.simform.com/serverless-performance/