From the get-go, it becomes imperative to employ the right framework, database, and an architecture that can scale your web application within a short span of time.
The initial success of your app can seem like a dream come true; however, the app might not hold the firepower to cater to a greater user-base as it grows in popularity.
If your app is facing this hurdle, fret not!
We’ve got just the expert solutions you need.
While most expert opinions promote improving the performance and scalability of a web application, their common crux must not be boiled down in one article because the context of scalability varies with the technology. However, the common aspects of scalability will remain constant across all technologies.
Editor’s note: Here Hardik shares valuable insights accumulated from top Industry experts to help you build scalable web apps. If you’re already inspired to build a scalable web app and need assistance to get started, connect with our web app development experts.
As it goes without saying,
“Scalability talks are like fashion: they follow fads and changes all the time. Some of them are based on merit; some of them are based on emotion.”
Here’s why we’ve pulled together tips from 25+ experts all over the web so that startups can make sure they’re using the best of Web Scalability tips without failure. We’ve also included a bonus Infographic at the end that will help you to extract these expert tips for building scalable web apps, without looking back.
But before we find out what these expert tips are, let’s uncover the most common myth that prevails in the developer’s community.
Unrevealing the most common myth regarding Scalability
Let’s say it immediately and clearly,
Web Scalability ≠ Web Performance. Period.
Yes, you read that right. Scalability and Performance, although quite confusing to many, are entirely different beasts. Both of them have different metrics and get measured in different ways.
In most conferences and talks on scalability, some people mostly talk about performance and high availability, but in reality, they were referring to scalability.
In the words of Royans K Tharakan (Head of US technical solution engineering at Google),

Let’s get to the real meaning behind these terms: scalability & performance.
When we talk about performance, we mean response time — or simply the raw speed of an application. So when an application isn’t responsive to 100 concurrent users, the real performance challenge lies in improving the average response time for the same 100 concurrent users.
On the other hand, scalability deals with the ability of an application to accommodate a sudden increase in demand. So when an application isn’t scalable for 100 concurrent users or resources, the scalability challenge lies in handling the arbitrary demand (maybe to scale beyond 100).
But here’s a no brainer: An increase in scalability often creates a negative effect on the performance of a web application. But, that doesn’t mean Scalability is directly related to performance in any sense (See the Graph). An application, irrespective of whether it is performant or not, can still be scalable.
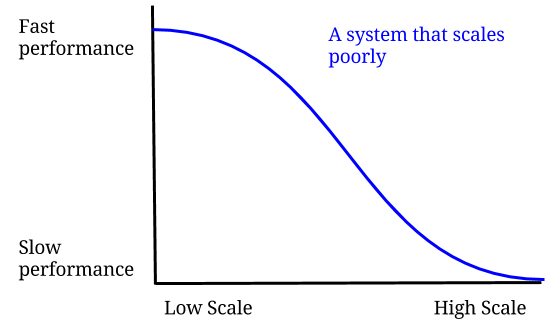
A scalable application, however, can also make sure that no matter how many users use the application –– the performance remains constant throughout the use (See Graph).
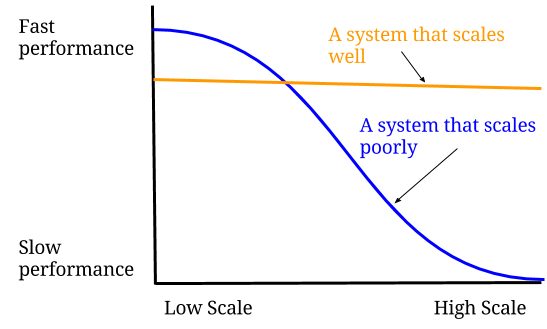
Leon Mergen, a Software developer at Solatis, urges people to focus on achieving the scalability first so that they can work on fixing things to make it performant.

Now that we have uncovered the most common myth regarding scalability, let’s get to know what are the expert tips on building scalable websites.

Expert Tips on Scaling Web apps
Tip #1: Choosing the correct tool with scalability in mind reduces a lot of overhead.
Psychologist Abraham Maslow famously said,
“It is tempting, if the only tool you have is a hammer, to treat everything as if it were a nail.”
Many developers fall prey to the idea of using one technology –– if they have used PHP from start, they will refuse to look beyond the local scope or rethink the existing tech stack.
Brian Zimmer, (VP, Enterprise Solutions at The Climate Corporation) called this as a Golden Hammer analogy which represents an over-reliance on a familiar tool even if the tool isn’t suited for a particular task.
In the words of Brian,

Having said that, the technology or tool you are using from start will always be going to have an overhead associated with it. No one technology or architecture can fulfill all your requirements.
Let’s compare the fact with a real-life analogy: From the beginning of your house construction, it will be a simple 2-room house. It is small, but fully equipped to meet the simplest needs of an MVP. If there is a sudden increase in the number of occupants, the house needs to be constructed accordingly (say a large number of visitors accessing your website). Now, the bigger is the need, greater will be the cost and the no. of functionalities required.
If you still choose to stick to the initial architecture of your house, chances are the base of house malfunctions and it will eventually collapse. Which is why it’s important to implement certain changes (or to revamp your original tech stack), in order to accommodate the new infrastructure requirements.
It is important to note that even Twitter was rewritten several times until it becomes scalable. For instance, in 2011 they migrated a large amount of Ruby and Rails code to the Java Virtual Machine (as JVM is more scalable). A few years back, the team admitted to having completely rewritten the search engine in Lucene (and hence dropping the usual MySQL).
Aditya Agarwal, (former VP of Engineering at Facebook) puts it succinctly during his famous “scale at Facebook” presentation that also covers their architecture,

Tip #2: Caching comes with a price. Implement it only to decrease costs associated with Performance and Scalability
Caching is a technique used everywhere, be it caching the CPU or web applications. However, most developers only understand a small significance of caching: caching helps in scalability or it increases performance. But there is more to caching then just allowing things to be scalable and faster.
According to Davide Mauri (Microsoft Data Platform MVP), this approach has two major problems: the first is that Scalability and performance issues will still persist after some time; the second follows the urge to cache more which will lead to major complexity issues.
In the words of Davide,

His advice?
In his blog “Caching is not what you think it is!“, Davide insists you to asks yourself if the need to implement caching can be something that comes with a lack of knowledge or if it’s really worth implementing due to the limits of resources. The lack of knowledge could be anything: misunderstanding or misleading Information from your colleagues.
If the need don’t come with the lack of knowledge, Davide urges you to carefully evaluate your caching options; either by a database, Redis or Local storage. Using caching strategies make a lot more sense if you are loading the same 5-10 top-rated products on every single request (say you are displaying them on a products catalog page). This way your users and database will thank you for it.
Chris Fauerbach, Founder Fauie Technologies LLC, extends this advice further by explaining the situation where it becomes necessary to cache.

Tip #3: Use Multiple levels of Caching in order to minimize the risk of Cache Miss
While Davide and Chris advices to think harder before caching, Jared Ririe, Software Engineer at Qualtrics, takes it one step further. According to Jared, scalable and performant applications require multiple layers of caching with participation from both clients and servers. The best developers implement multiple layers of caching to reduce cache misses.
This realization didn’t come to Jared immediately, though. It’s something he understood when he was building one of the backend systems at Qualtrics. His was a storage system that many services relied on, yet had no service dependencies itself. The system suffered from a condition Jared referred to as “the multiplier effect”.
Just by clicking a button on the UI caused a single request to be multiplied into thousands of requests making it to the back of the backend. (See the Image for illustration). 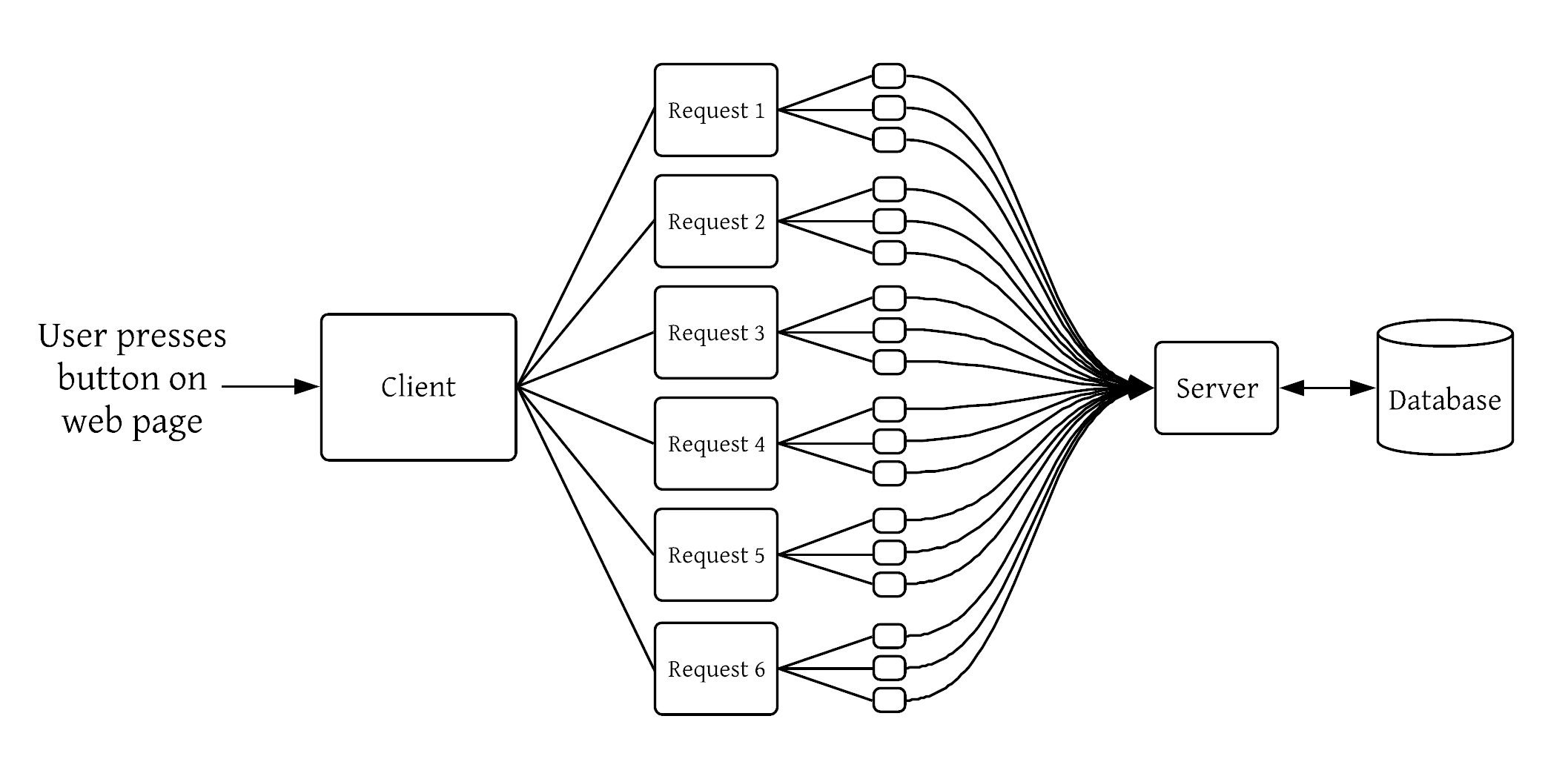 Luckily, Jared finds his solution in the multiple layers of caching. He used an external API that acts as a reverse proxy caching service. You can read Jared’s experience in his own words on his blog titled “Multiple layers of caching“.
Luckily, Jared finds his solution in the multiple layers of caching. He used an external API that acts as a reverse proxy caching service. You can read Jared’s experience in his own words on his blog titled “Multiple layers of caching“.
Jared further expresses his validation in the form of this statement,

However, Don’t take only Jared’s word for this. After all, he is not alone who finds multiple levels of caching as profitable.
In his blog “Why do we cache?”, Alex Landau explains the challenges to create a robust caching system. He explained the concept of a cache miss with a real-life example of a web app named Lineup, which includes an autocomplete feature to search for artists from Spotify as you type. Each time it fires, a request is made to Spotify’s search API to get back the top 5 matching artists for the query. That’s a lot of requests to Spotify’s API! Imagine a few thousand people using Lineup at once.
Turns out, Alex’s intuition was right! With five threads running the requests in parallel, here are the results:
| 33016 cache hits, 2986 cache misses |
In this case, it gets very important to have a multilevel caching strategy to improve the performance of the application, especially as it starts to scale.
In the words of Alex,

Tip #4: Use multiple Databases (or SQL + NoSQL) to maintain data consistency and integrity.
Making a choice between SQL and NoSQL has never been more challenging with industry experts being divided on which one of the two databases is more scalable.
In his blog, SQL + NoSQL = Yes !, Frédéric Faure highlights how the term ‘NoSQL’ was used to market introduced an extended version of SQL. He further adds,

In fact, a a survey done by scalegrid.io suggested that 44.3% of businesses amalgamate two or three databases to scale their application. What’s more, SQL and NoSQL was the most popular multi-database combination employed by over 75.6% users.

Furthermore, this model offers the best of both worlds where the distinct functionalities of both database systems are applied to maintain the data’s consistency, reliability, flexibility, fault tolerance, and reduce the overall costs.
In his book, Entity Framework Core in Action, Jon P. Smith demonstrates how SQL and NoSQL can be used in combination. He referred a use case of a book-selling site where one of the core functions is to sort books by average review votes. He faced challenges in showing the list of books, sorting the books by reviews, and showing the top 100. He spent endless hours and found a major difference in the performance (SQL database only vs multi databases (SQL+NoSQL CQRS version).
Jon learned a powerful lesson: By using multiple databases, a web app can handle a number of users simultaneously while still providing ‘good’ performance. By using and locating databases geographically across the world, it provides the shortest access time. In short, SQL+NoSQL : Excellent Performance + scalability
Here’s a quote from Jon P. Smith is elucidating more clearly :

[et_bloom_inline optin_id=optin_173]
Tip #5: Avoid using Local Disks and Use Object storage API of cloud to make data storage manageable
When you come to a point when your data becomes hard to maintain/ manage or it is highly unstructured, using cloud native solutions should be your go-to approach.
Today, your cloud-native data is shaped in all different ways and resides in a number of places. For instance, your cloud-oriented data could be stored in the event log, relational database, document or key-value store, object store, network-attached storage, cache, or cold storage.
Furthermore, you have a choice between file storage and object storage methods to store your data such as blob, user uploads, files, etc.
Although, your ideal choice will always depend upon the situation but it is always recommended to leverage the object storage capability of the cloud.
Andrew Boag, Managing Director, Catalyst IT Limited, gave an awesome presentation titled “Why mess with file systems? The future of storage is object-based.”
In the words of Andrew,
 The reason why Andrew is so obvious about the future of Object Storage API is due to traditional file-based storage as it needs more management the larger systems get larger. However, object storage extracts the work like capacity management, backup, and concerning about separate disks.
The reason why Andrew is so obvious about the future of Object Storage API is due to traditional file-based storage as it needs more management the larger systems get larger. However, object storage extracts the work like capacity management, backup, and concerning about separate disks.
Object storage does not make use of complicated hierarchies, folders, and directories. However, the object includes data, metadata, and a unique identifying ID number that an app uses to locate and access it. In this scenario, metadata is more detailed than the file-based approach and can be customized with extra context.
Moreover, with object storage, you will get a higher level of scalability and can store/manage data volumes that are close to terabytes (TBs), petabytes (PBs) & even greater. However, scalability is hard to achieve with traditional file or block-based storage.
Therefore, if your main goal is to store media files where durability matters, it makes a lot more sense to use Object Storage.
Alex Gaynor, a startup owner of Alloy, describes this aptly in his blog: Tips for scaling web apps

Tip #6: Make your web applications stateless unless there is a very good reason to have state or store sessions
All over the web, you will find people debating over stateful and stateless architectures. And this seems never-ending.
But, what all the debates have in common has little to no connection with scalability. A general notion prevailing among developers and software architects can be sentenced in a single line: web applications should be stateless, meaning each request should be treated as an independent transaction.
For an initial overview of what we are talking about, Let’s see how Wikipedia defines the term stateless:
“In computing, a stateless protocol is a communication protocol in which no session information is retained by the receiver, usually a server. Relevant session data is sent to the receiver by the client in such a way that every packet of information transferred can be understood in isolation, without context information from previous packets in the session. This property of stateless protocols makes them ideal in high volume applications, increasing performance by removing server load caused by retention of session information.”
The overall benefit of making your web application as stateless boils down to a single line: avoid storing sessions on your server at all cost as it might increase the further load on your server and induce code complexities.
Gregor Riegler at BeABetterDeveloper gave a wonderful explanation in his piece “Sessions, a Pitfall” which explains why storing sessions on your server is bad.

By going stateless, you are simplifying the client/ server communication model of your application. Since the client can request anything from the server without having the need to know the state of the server, you are helping your application to scale out the server implementation since there is no need to change the pool of sessions constantly throughout the application servers.
Although George urges you to use a stateless protocol, Hugh Mckee, Developer Advocate at Lightbend, makes complete sense as to why he thinks there are reasons to do the opposite as well as i.e going stateful. In his blog “How to build successful cloud-native solutions”, Hugh demonstrates the scaling capability of stateful applications by illustrating a shopping cart example.
In the blog, Hugh concludes his opinion on stateless vs stateful debate with the following quote,

We reached out to Hughe for his opinion on building scalable web apps, here’s what he adds,

Tip #7: Use Asynchronous Communication wherever possible to avoid wastage of application resources
You must have heard this countless no. of times: Making things asynchronous is a proven way to increase scalability. But, is it really possible to solve most of (if not all) scalability related problems in an asynchronous way?
These words by Udi Dahan challenges this thinking:

To the point, with asynchronous IO, you can handle thousands and thousands of request at the same time without the need to block requests and wait for the return value from the kernel by the user application. Here’s why some applications which use asynchronous (i.e Non-Blocking), are also built using single-threaded frameworks such as NodeJS.
Clemens Vasters, Technical Software Architect at Azure, explained the benefit of using Asynchronous code to make things scalable.
In the words of Clemens,

But does that means asynchronous programming is the answer to all your scalability related challenges?
The answer will be: It depends. Using Asynchronous programming only makes sense when you are processing the I/O bound and CPU bound requests (requires CPU time). Asynchronous programming will give you tons of complexity when you are starting out, but it’s better than to wait for your system to get out of hand (which usually happens when you are building synchronous systems).
In his blog, Reactive Manifesto 1.0, Jonas Bonar (Founder & CTO of Lightbend) explained why Reactive programming is the go-to way to build applications that are event-driven, scalable, resilient and interactive. Jonas further stressed on why he thinks to go Asynchronous (such as Reactive programming) is important while building web applications.
According to Jonas,

Tip #8: Use Queues to make your tasks atomic so that they can be retrieved easily when fails
Integrating a Message queue in your application makes it more viable to fault-tolerance, thereby increasing its scalability.
Let’s understand this with the help of an example:
In your web application, you have a client and a server talking to each other. With millions of load requests pertaining to your server, it is inevitable to fail.
In such situations, you should have answers to the following questions:
- How will the client react or handle the situation when the server failed? Are your tasks atomic?
- If the server worked again, will clients be able to resend the request?
- What if your server responds and the client failed?
- If millions of clients call a web service on one server within seconds, do you have contention in place?
- Can you expect an immediate response from the server in case of a failure?
Message queues like RabbitMQ provide you with enough buffer to cope with sudden traffic spikes to your application. In the example above, you will benefit from using Message queues in the following ways:
- If the server fails, the queue can still be able to persist the message. Even if it fails, the message will not be added to the queue. The operation is atomic.
- If the server worked again, it receives the pending message.
- If the server gives a response to the call and the client fails, if the client didn’t acknowledge the response the message is persisted.
- You have contention in place. It’s you who decide how many requests are handled by the server or worker.
- You don’t expect an immediate synchronous response, but you can implement/simulate synchronous calls.
The image below is the easiest way to understand Message queues:
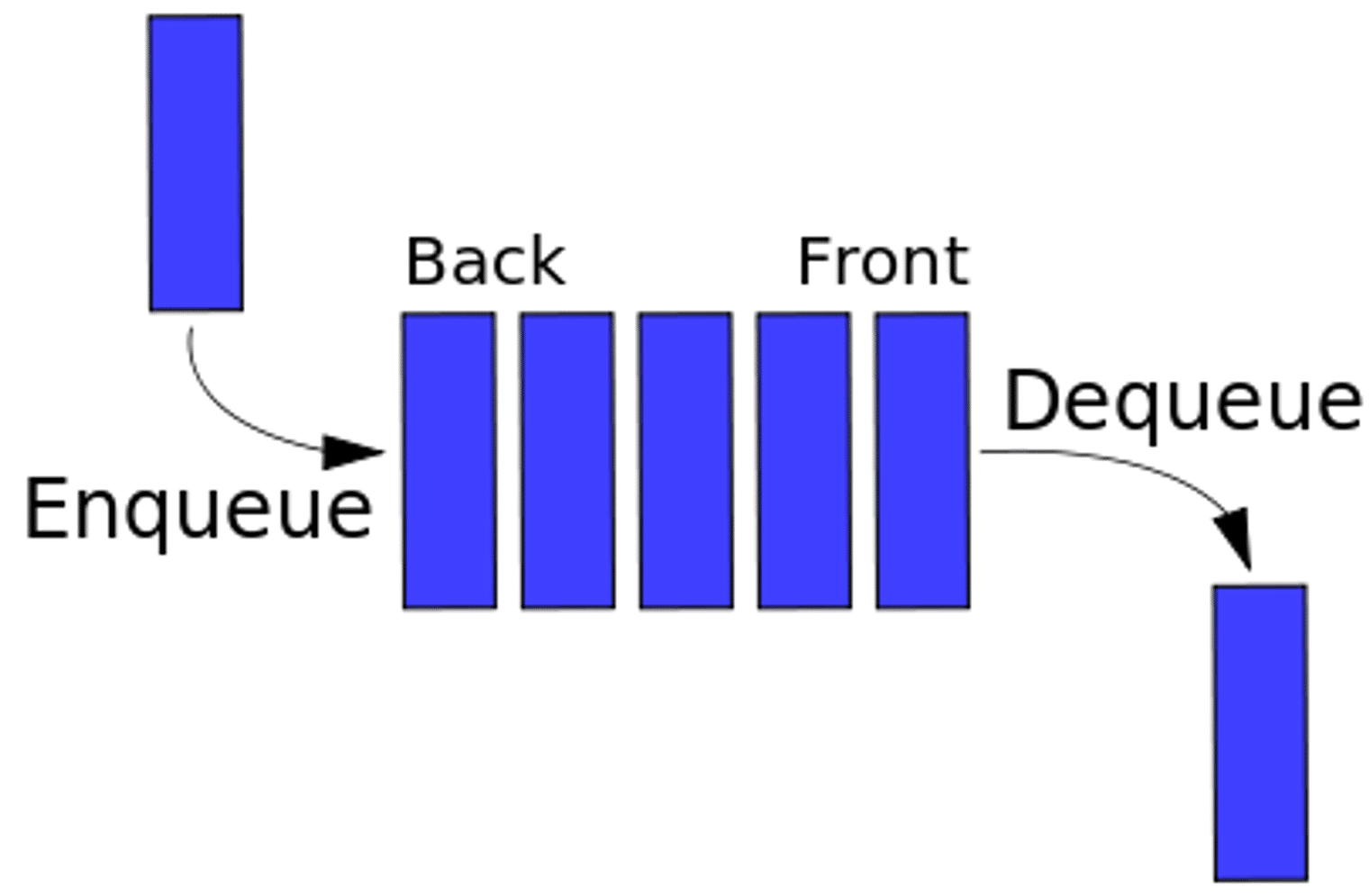
Alberto Gimeno, Software Engineer at Github, suggests you make your tasks as atomic as possible with the help of Message queues so that you can retrieve them successfully when they failed.

Tip #9: Always have the ability to roll back your code in case of failed deploys
Martin L. Abbott and Mike Fisher, in their book “Scalability Rules: 50 Principles for Scaling Web Sites”, shared this valuable key takeaway,
“Don’t accept that the application is too complex or that you release code too often as excuses that you can’t rollback. No sane pilot would take off in an airplane without the ability to land, and no sane engineer would roll code that they could not pull back-off in an emergency. “
This quote is perfect for all types of scaling, not just web applications. The thing is: as much as you want your code to execute perfectly, there will always be some situations when your final deployment fails and you need to revert back to make things better. This is when you need to do code rollback.
In his article at Dzone titled “How to do rollbacks well”, Benjamin Wooton, Co-Founder, and CTO at Contino stressed the fear that most developers possess for not being able to roll back the failed code deploys.

According to Ben, when your code push is unsuccessful, a rollback becomes necessary to restore the environment to a previously stable state.
Tip #10: Load or performance Test Your Application Every Single Day
Once your application reaches the scalability bottleneck, it’s important for you to analyze either the performance issue which you experience upfront or the load due to which your application fails to respond.
Performance and load testing — albeit confusing terms for many — can be useful for you to determine such metrics. Roger Campbell, owner at Loadstorm (a platform to implement load testing for applications), clears the air of confusion people to have regarding Load and Performance testing.

While Performance testing is used to check your application’s response time to the load. On the contrary, load testing deals with scalability metrics such as requests per second and concurrent users.
As far as Load Testing is concerned, you should experience an increase in your application’s throughput when a load is increased.
Steve “ardalis” Smith, an experienced Software architect and tutor at Pluralsight, explained about what happens when you suddenly load test your application using the example of Requests per the second curve in his blog.
In the test, you test your application with a small load (say for 1 user) and increase it considerably till the request per second curve (r/s) hits a bottleneck and starts losing its pace.
In the words of Steve,
 The Image attached below (no. 1) represents what our r/s curve will look like until it reached up to 50 users. On the other hand, Image (no. 2) describes the r/s curve when your application starts to experience the final throughput in terms of load.
The Image attached below (no. 1) represents what our r/s curve will look like until it reached up to 50 users. On the other hand, Image (no. 2) describes the r/s curve when your application starts to experience the final throughput in terms of load.
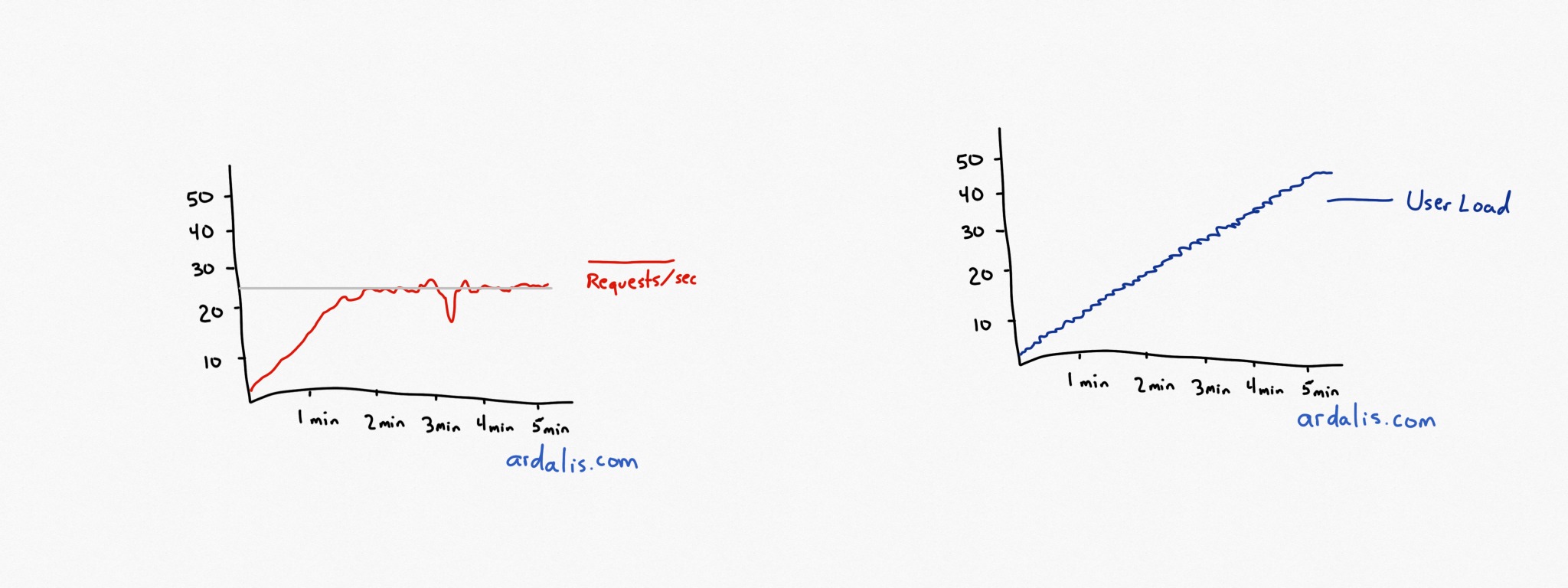
While Steve takes you through the basics of Load Testing, Joe Colantonio (test automation architect for a large Fortune 100 company and founder of TestGuild) runs a website completely dedicated to educating the software professionals about Performance testing.
Joe describes the consequences of not implementing performance testing in their applications.

That said when you hit the rock-bottom of your application’s lifeline, it’s important to Load test and performance test it every other day.
Tip #11: Root out any Single point of failure (SPOF), but be prepared when failure strikes your application
Dr. Ian Malcom, one of our favorite Jurassic Park characters, once paraphrased, “failure, uh, finds a way”.
When it comes to scaling web application, failures are inevitable. Therefore, it becomes extremely evident for us to either isolate the failure or to identify any single point of failure.
But before you decide to isolate any failure or root-out any SPOF, ask yourself a certain set of questions: What if the piece of code you have written doesn’t work at all? What if you end up writing an old legacy code that is hard to maintain and scale at some point?
Isaac Wong, Vice President of Metadata Platform Architecture, expressed this in the Metadata Engineering blog,

Taking this one step further, Sean Hull, Cofounder of Orbit, advice to find out what causes an application to fail in the first place. Is it because your database isn’t working properly? Or Is it because you have an inefficient server handling your requests?

In the majority of cases, a Single point of failure might strike your application if your application has,
- An unsecured network
- Failure of particular resources (e.g server, network resources, database, caching system)
- Lacking in built-in redundancies
In extreme cases, however, a SPOF could be due to Machine failure, physical or virtual damage to an application. However, as a developer, you often don’t get to know the real cause until you experience the failure with your naked eyes.
For instance, a big part that prevented Airbnb from achieving web scalability was due to the failure of Amazon Web Services and outage. Had it not been for scalability, Airbnb could have implemented the following things to prevent from SPOF,
- Use multiple zones and regions for databases
- Use multiple cloud providers
- Web servers can be hosted in different regions
- Use ‘Browsing only mode’ when don’t have control over the outage
Tip #12: Automate Everything to Run Continuously
In the world where Automation is used in almost 80% of engineering jobs, you can’t imagine your web development without it.
When it comes to scalability, automation is considered as one of the important parameters. We need to automate everything when the infrastructure gets bigger because it is hard to manage every instance. Understanding the importance of automation can help you to scale web apps.
Todd Hoff, owner of highscalability.com, shares his tip –
Don’t deploy by hand or do anything you can convince a machine to do for you.
With automation, you don’t need to manage each individual instance. Amazon’s S3 is one of the effective solutions for storage. It is possible to achieve scalability by moving towards the following cloud storage solutions:
- AWS Elastic Beanstalk
- AWS OpsWorks
- Amazon EC2
- AWS CloudFormation
- AWS CodeDeploy
Check out all 25+ expert tips in the infographic below!
Embed this Infographic on Your Site (Use following code)

Conclusion
Ofcourse, there may be millions of tips to tackle the challenges of website scalability; however the ones shared by the experts are the core ingredients of a successful scalability recipe. Now, it’s your call to implement these tips according to your challenges.
But, do give us the feedback. Do you have a scalability tip that you want to share? Shoot us a comment!

apijack
Fantastic compilation article. Congrats! Strongly agreed especially with the tip to avoid using local disk storage and make use of APIs for cloud data storage management.
Saket Kumar
A very well written article collating so many different tips for successfully implementing a highly scalable application