As we were struggling with large servers and low storage limits, we decided that it was best to forward all this data to large data centers and call their cluster the cloud. It meant more storage, but also resulted into dependency on the internet to access our data. Then, we made connected devices, also known as Internet of Things (IoTs) that are connected to the cloud and constantly pull and push data into it. It allowed us to store large amounts of data and retrieve it efficiently. But there was one major issue – bandwidth.
With a shortage of bandwidth, we could either increase the number of servers, which would be expensive or send only the most important data to the cloud in order to save bandwidth. Edge and fog computing help us achieve exactly that, and in this article, we will discuss how they do it and help IoT devices function better.
What is edge computing?
Edge computing refers to processing and analyzing data at or near the source rather than relying solely on cloud or centralized servers. It brings computing power closer to the devices and sensors generating the data, reducing latency and enhancing real-time capabilities.
Edge computing and cloud computing are complementary technologies. While cloud computing involves storing and processing data in centralized servers in data centers, edge computing brings computation closer to the data source. Edge computing can work with cloud computing to create a hybrid architecture, optimizing data processing and storage for various applications. The faster and localized processing is similar to how edge computing speeds up data processing by bringing it closer to the source, improving efficiency and responsiveness.
What is fog computing?
Fog computing is a decentralized approach that extends cloud computing capabilities to the network’s edge. It involves deploying computing resources, such as storage and processing power, closer to where data is generated and consumed. It enables faster data processing, reduces latency, and improves efficiency.
Imagine you’re at a busy airport, waiting for your flight. The airport has multiple information booths to get flight updates, directions, and other services. Instead of going all the way to the central control tower (cloud) for every request, the information booths (fog nodes) provide you with immediate assistance. Fog computing works similarly, bringing processing power closer to devices, like your smartphone, for faster and more efficient data processing.
Edge computing and IoT
Instead of completely depending on a cluster of clouds for computing and data storage, edge computing is able to provide intelligent services by leveraging local computing and local edge devices like routers, PCs, and smartphones. The biggest advantage of this all is, of course, shorter response time as the data is processed locally.
While many might refer to edge computing as the work that happens at the very edge of the network where the cloud is connected to the physical world via an IoT device, it is much more than just data processing and computation.
By using the processing power of IoT devices, edge computing applications are able to pre-process, filter, score, and aggregate IoT data. It also uses the flexibility of the cloud services to run complicated analysis on that data.
Edge computing vs Fog computing
With edge computing, the IoT data is collected and analyzed directly by controllers, sensors, and other connected devices, or the data is transmitted to a nearby computing device for analysis.
While fog computing is similar to edge computing and they are often mistaken for each other, there is a slight difference between them. In fog computing, there is only one centralized computing device responsible for processing data from different endpoints in the networks. On the other hand, in edge computing, every network participates in processing data.
The main difference between them is where the computation and intelligence power is placed in their architecture:
- Edge computing pushes communication capabilities, processing power, and intelligence data directly into devices like programmable automation controllers
- Fog computing pushes intelligence data to the local area network and processes data either in an IoT gateway or a fog node
Application and use cases of Edge computing
Edge computing can help financial organizations identify and stop non-compliant transactions by setting up micro data centers that enable real-time analytics. Since the processing is faster, the non-compliant transactions are stopped more quickly leading to better results for the organization.
Wind farms can also take advantage of edge computing. Since they are located in remote areas and getting information from the cloud quickly isn’t always possible, edge computing allows real-time analysis of data to modify the turbines in order to maintain efficient electricity output.
Examples of Fog computing
The oil and gas pipelines around the world generate terabytes of data over the course of years. By leveraging fog computing for oil pipelines, we can create fog computing nodes that transfer data to each other in a line and the cloud will only need to know about the high-level details which will, in turn, save bandwidth.
Processing sensor data at the edge
Sensors are the devices on the edge that communicate with the cloud through the edge IoT gateway.
For instance, an engine sensor may be emitting temperature status reports every second which may not be useful for a cloud based analytical application that processes the temperature reports after every minute. So, instead, the edge IoT gateway can store the information from the sensor and send it after every minute.
Advantages and disadvantages of fog computing
There are many ups and down to fog computing. Its advantages include:
- It provides location awareness, low latency, and improves the overall quality of services
- Brings data close to the user as compared to storing data far from the end point in data centers
- With its ability to control data at the different end points, it’s able to integrate distributed data center with cloud services
- It creates a dense geographical distribution
The disadvantages of fog computing include:
Advantages of edge computing
With edge computing, there is a lot to gain, including:
- Since every network participates in processing data, it leads to lesser delays
- Real-time data analysis at the local level
- Lower operating costs since there are smaller data management and operational expenses
- Lowered network traffic since less data is transmitted between the data centers and the local devices
- Improved performance of the apps with lower latency
How does fog computing work?
Fog computing is responsible for analyzing the most time sensitive data sent by the internet of things. Essentially, the fog nodes that are closest to the sensors look for problems or signs and then prevent them from sending signals to the actuators.
- Data that can wait only a few seconds or minutes is sent directly to the fog node for analysis and action
- Date that is much less time sensitive is sent directly to the cloud for long term storage or historical analytics
Fog nodes also send data periodically to the cloud for storage. By effectively using local data and only sending selective data to the cloud fog computing is able to save bandwidth.
Fog computing architecture
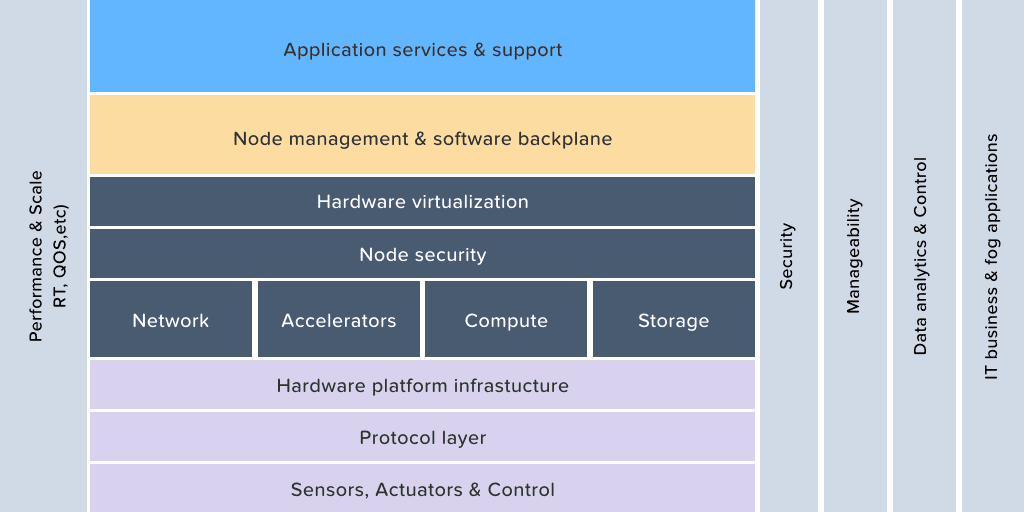
Edge computing exclusively performs analytics either close to the network’s edge or at the devices that are on edge. On the other hand, fog computing can perform analytics on any part of the network, right from the center to the edge.
The fog computing architecture consists of three main segments:
IoT devices: These are the connected devices that send large volumes of data to the fog network and eventually the cloud.
Fog network: It is responsible for receiving data from the IoT devices in real-time, using any protocol. Then the fog nodes run IoT enabled applications for real-time analysis and their response time is often a millisecond.
Cloud: The cloud receives and puts together the periodic data summaries sent by the different fog nodes. It also performs analysis on the data to gather business insights and then sends new application rules based on those insights to the fog nodes.
Edge computing components
The Edge things
As we have mentioned, edge computing means processing data as close to the network as possible. All the data generation, analytics, and taking action is done on edge only. The edge things can be sensors, actuators, and smart devices.
IoT gateway
The main responsibility of the IoT gateway is to connect the edge things with the cloud. That is why it must be able to understand both the field protocols and cloud protocols. It also stores peripheral data and then sends periodic data to the cloud.
Cloud
The cloud takes the periodic data from the gateway, analysis it and then sends instructions back to the gateway.
Edge computing deep learning applications
Since edge computing already can take real-time decisions, we can add deep learning architecture on the edge to improve the quality of decision making.
For instance, by introducing deep learning algorithms like convolutional neural network, it becomes possible for ATM cameras to automatically detect if someone is trying to access an ATM wearing a helmet or cap.
Instead of relying on the cloud for processing, real-time processing can be done on the edge decreasing latency issues, cost, bandwidth, and problems related to limited connectivity.
Generating edge analytics in IoT
With edge analytics, it becomes possible to collect and analyze data by performing automated analytical computations at the edge/ source instead of sending data to the cloud and waiting for the results.
The analytics can be done on any device like a switch, gateway, router, or a server. By analyzing the data at the edge right when it’s generated, it easy to respond to emerging conditions faster. Not to mention, the burden of moving large amounts of data over the network also decreases.
With edge analytics, it’s easy to apply rich set of analytics even at a small scale, and it’s flexible enough to scale up and still maintain seamless operations.
Agent based modeling in edge computing
The next big thing to revolutionize edge and fog networks would be locally present agents. These agents will be driven by Artificial intelligence, making sure the system dynamics are optimized and the impact of industrial automation is maximized.
From autonomous monitoring of power consumption to building safety criticality within hardware ecosystems, Agents will revolutionize everything that we know so far about our world. Edge computing has a high opportunity for these agents to become more and more ubiquitous, as the agents won’t have to rely on bulky or even need a remote cloud infrastructure to operate.
To many industry practitioners that we speak to, used to be baffled by the idea of taking a network offline citing SAP’s move to Cloud in the early 2016. But, SAP itself now acquired an edge IoT platform company, while others like Microsoft and Amazon launched their own IoT Edge platforms as well.
We have been extensively working with IoT edge solutions for some time now. Subscribe to our blog to get future updates on our work.
