Download the case study
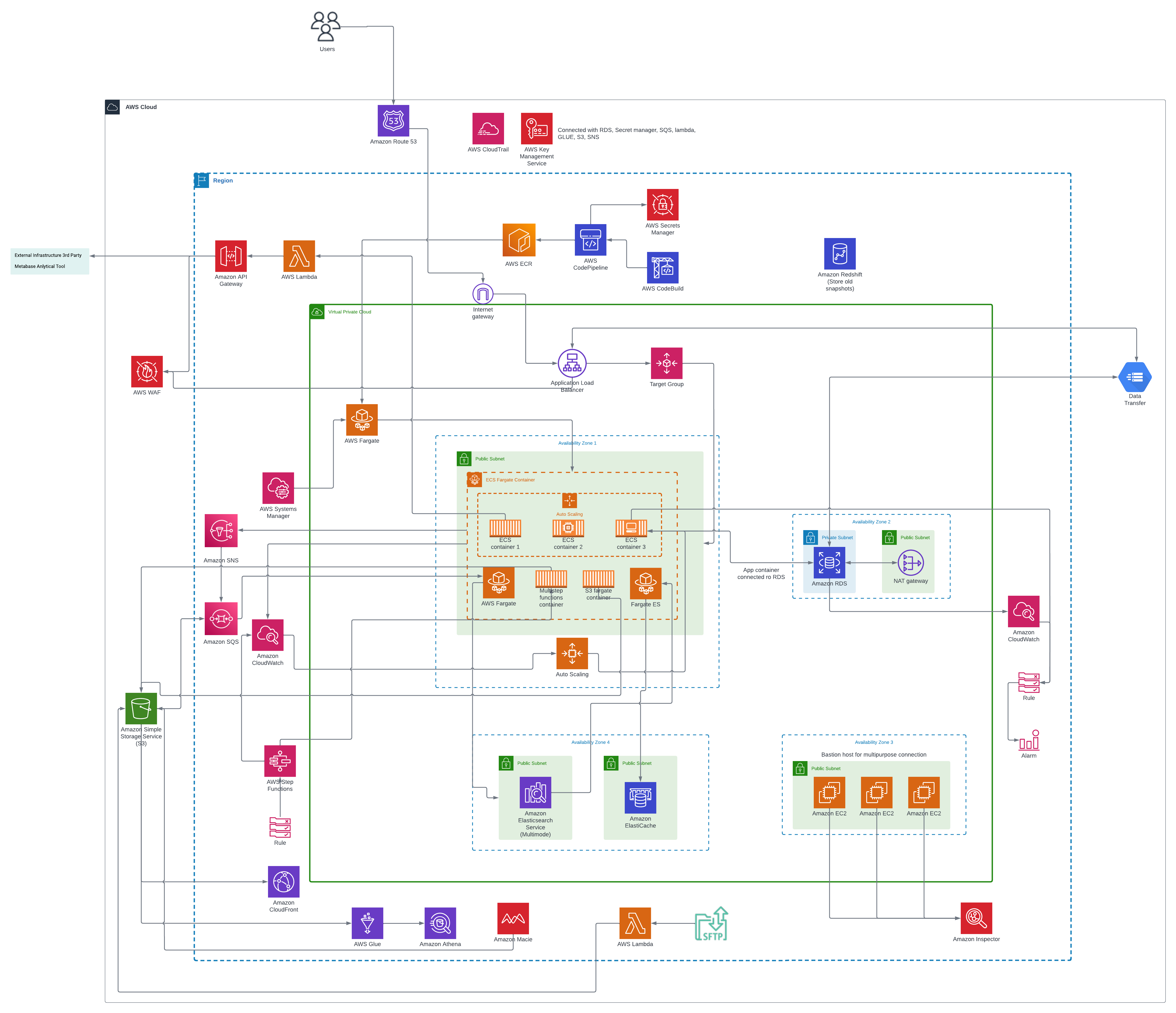
Virgil: Using technology to streamline the recruitment process
Category: Human resource management
Services: Managed Engineering Teams, Cloud Architecture Design, and Review
Category: Human resource management
Services: Managed Engineering Teams, Cloud Architecture Design, and Review